- 1、 [LG] Hardware and Software Optimizations for Accelerating Deep Neural Networks: Survey of Current Trends, Challenges, and the Road Ahead
- 2、 [LG] Curiosity in exploring chemical space: Intrinsic rewards for deep molecular reinforcement learning
- 3、 [LG] Imitating Interactive Intelligence
- 4、 [LG] Task Uncertainty Loss Reduce Negative Transfer in Asymmetric Multi-task Feature Learning
- 5、[CL] EdgeBERT: Optimizing On-Chip Inference for Multi-Task NLP
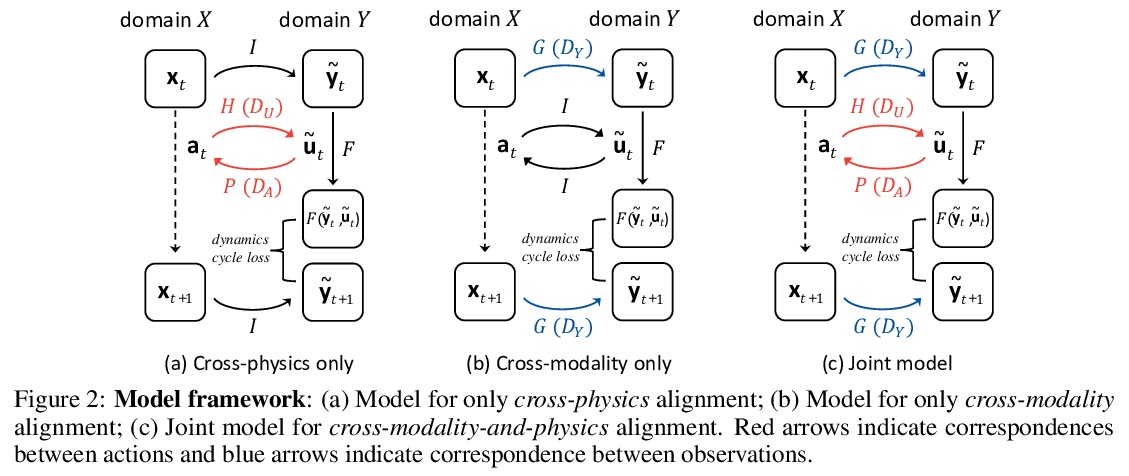
- [RO] Learning Cross-Domain Correspondence for Control with Dynamics Cycle-Consistency
- [LG] Deep Learning for Human Mobility: a Survey on Data and Models
- [IR] Cross-domain Retrieval in the Legal and Patent Domains: a Reproducability Study
- [CV] HyperSeg: Patch-wise Hypernetwork for Real-time Semantic Segmentation
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、 [LG] Hardware and Software Optimizations for Accelerating Deep Neural Networks: Survey of Current Trends, Challenges, and the Road Ahead
M Capra, B Bussolino, A Marchisio, G Masera, M Martina, M Shafique
[Politecnico di Torino & Technische Universität Wien (TU Wien) & New York University Abu Dhabi]
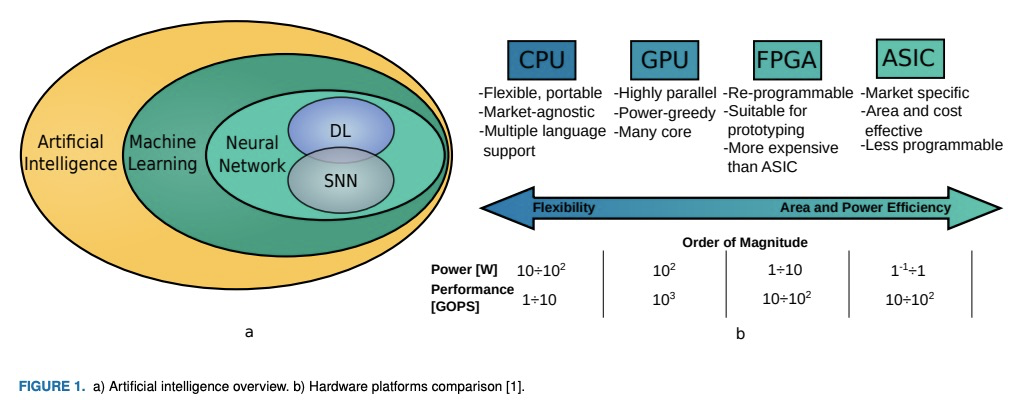
深度网络加速软硬件优化综述。总结和比较了CPU、GPU、FPGA和ASIC四种领先的算法运行平台,描述了最先进的解决方案,最突出的是后两种方案,提供了更大的设计灵活性,具有高能效的潜力,特别在推理过程中。除了硬件解决方案,还讨论了DNN和SNN模型在执行过程中可能存在的一些重要安全性问题,提供了全面的基准测试的总结,解释了如何评价为它们设计的不同网络和硬件系统的质量。
Currently, Machine Learning (ML) is becoming ubiquitous in everyday life. Deep Learning (DL) is already present in many applications ranging from computer vision for medicine to autonomous driving of modern cars as well as other sectors in security, healthcare, and finance. However, to achieve impressive performance, these algorithms employ very deep networks, requiring a significant computational power, both during the training and inference time. A single inference of a DL model may require billions of multiply-and-accumulated operations, making the DL extremely compute- and energy-hungry. In a scenario where several sophisticated algorithms need to be executed with limited energy and low latency, the need for cost-effective hardware platforms capable of implementing energy-efficient DL execution arises. This paper first introduces the key properties of two brain-inspired models like Deep Neural Network (DNN), and Spiking Neural Network (SNN), and then analyzes techniques to produce efficient and high-performance designs. This work summarizes and compares the works for four leading platforms for the execution of algorithms such as CPU, GPU, FPGA and ASIC describing the main solutions of the state-of-the-art, giving much prominence to the last two solutions since they offer greater design flexibility and bear the potential of high energy-efficiency, especially for the inference process. In addition to hardware solutions, this paper discusses some of the important security issues that these DNN and SNN models may have during their execution, and offers a comprehensive section on benchmarking, explaining how to assess the quality of different networks and hardware systems designed for them.
https://weibo.com/1402400261/JAllSCv4S
2、 [LG] Curiosity in exploring chemical space: Intrinsic rewards for deep molecular reinforcement learning
L A. Thiede, M Krenn, A Nigam, A Aspuru-Guzik
[University of Toronto]
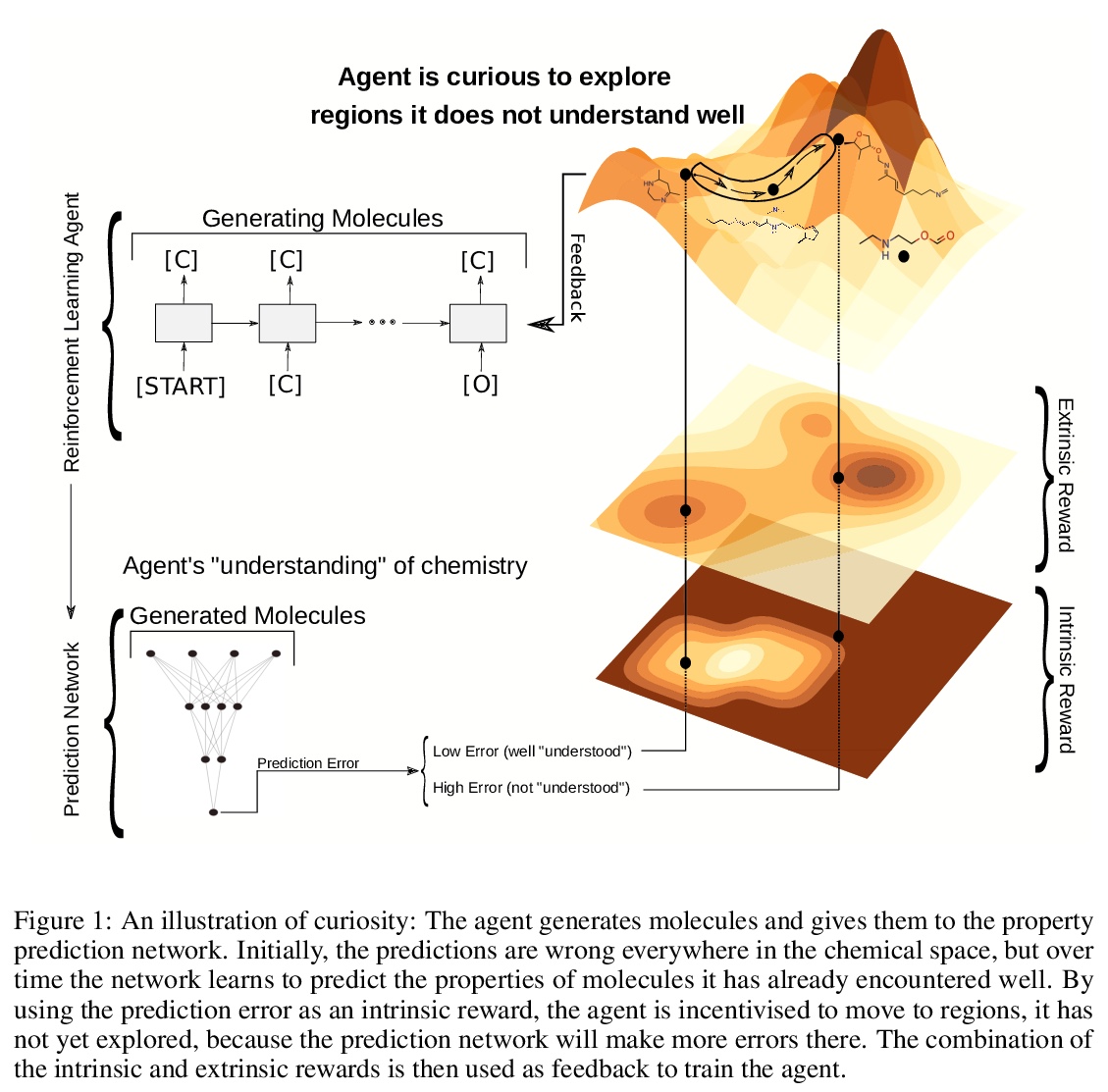
用好奇探索化学空间:分子深度强化学习的内在奖励。提出一种新的、高效的深度强化学习探索策略,用于识别高性能分子和化合物,可在没有任何先验知识的情况下探索化学空间,其灵感来自于文献中被称为“好奇”的概念。在三个基准上的实验表明,好奇智能体可以找到性能更好的分子。
Computer-aided design of molecules has the potential to disrupt the field of drug and material discovery. Machine learning, and deep learning, in particular, have been topics where the field has been developing at a rapid pace. Reinforcement learning is a particularly promising approach since it allows for molecular design without prior knowledge. However, the search space is vast and efficient exploration is desirable when using reinforcement learning agents. In this study, we propose an algorithm to aid efficient exploration. The algorithm is inspired by a concept known in the literature as curiosity. We show on three benchmarks that a curious agent finds better performing molecules. This indicates an exciting new research direction for reinforcement learning agents that can explore the chemical space out of their own motivation. This has the potential to eventually lead to unexpected new molecules that no human has thought about so far.
https://weibo.com/1402400261/JAlqclzrO

3、 [LG] Imitating Interactive Intelligence
J Abramson, A Ahuja, A Brussee, F Carnevale, M Cassin, S Clark, A Dudzik, P Georgiev, A Guy, T Harley, F Hill, A Hung, Z Kenton, J Landon, T Lillicrap, K Mathewson, A Muldal, A Santoro, N Savinov, V Varma, G Wayne, N Wong, C Yan, R Zhu
[DeepMind]
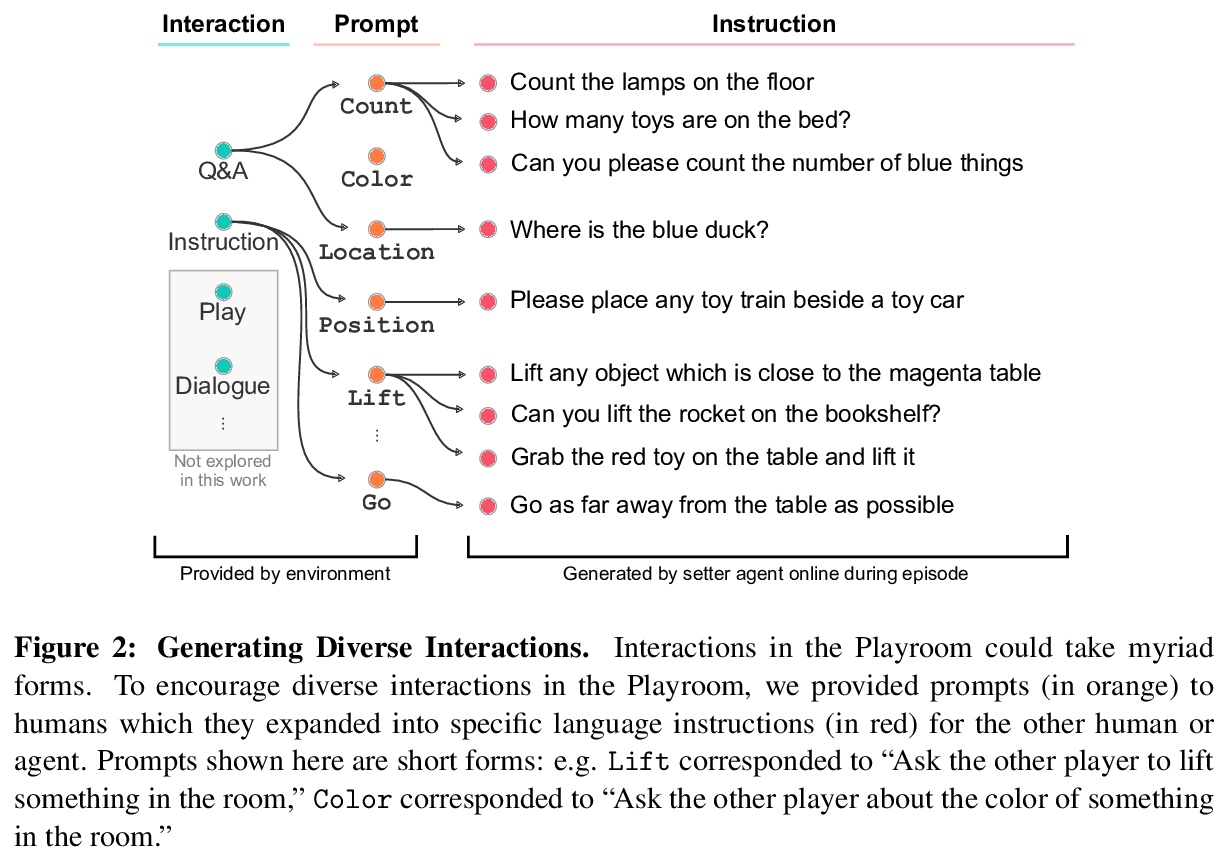
模仿交互式智能。研究如何利用虚拟环境的简化,来设计能与人类自然交互的人工智能体。为了构建能与人类稳健交互的智能体,用另一个经过学习的智能体,来近似人类的角色,用逆强化学习思想来减少人与人之间和智能体与智能体之间交互行为的差距。开发了各种行为测试,包括由观看智能体视频或直接与智能体交互的人类进行评价。在虚拟环境中的实验结果证明,大规模的人类行为模仿是创造智能和交互式智能体的一个有前途的工具,可靠评价这种智能体的挑战也是可以克服的。
A common vision from science fiction is that robots will one day inhabit our physical spaces, sense the world as we do, assist our physical labours, and communicate with us through natural language. Here we study how to design artificial agents that can interact naturally with humans using the simplification of a virtual environment. This setting nevertheless integrates a number of the central challenges of artificial intelligence (AI) research: complex visual perception and goal-directed physical control, grounded language comprehension and production, and multi-agent social interaction. To build agents that can robustly interact with humans, we would ideally train them while they interact with humans. However, this is presently impractical. Therefore, we approximate the role of the human with another learned agent, and use ideas from inverse reinforcement learning to reduce the disparities between human-human and agent-agent interactive behaviour. Rigorously evaluating our agents poses a great challenge, so we develop a variety of behavioural tests, including evaluation by humans who watch videos of agents or interact directly with them. These evaluations convincingly demonstrate that interactive training and auxiliary losses improve agent behaviour beyond what is achieved by supervised learning of actions alone. Further, we demonstrate that agent capabilities generalise beyond literal experiences in the dataset. Finally, we train evaluation models whose ratings of agents agree well with human judgement, thus permitting the evaluation of new agent models without additional effort. Taken together, our results in this virtual environment provide evidence that large-scale human behavioural imitation is a promising tool to create intelligent, interactive agents, and the challenge of reliably evaluating such agents is possible to surmount.
https://weibo.com/1402400261/JAlxCtHC9

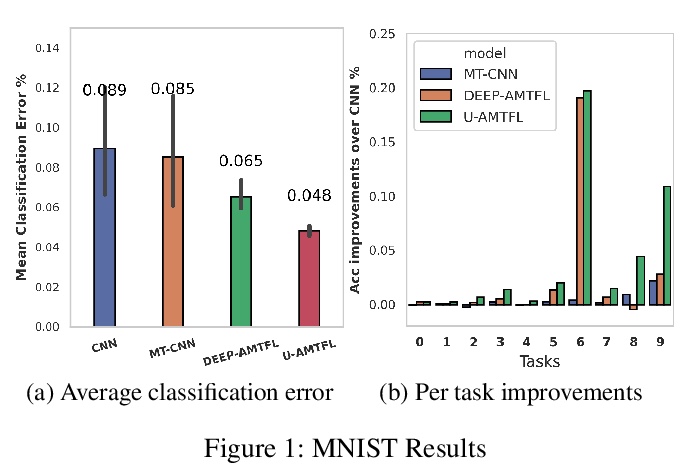
4、 [LG] Task Uncertainty Loss Reduce Negative Transfer in Asymmetric Multi-task Feature Learning
R P d Silva, C Suphavilai, N Nagarajan
[National University of Singapore & Genome Institute of Singapore]
用任务不确定性损失减轻非对称多任务特征学习中的负迁移。提出利用不确定性作为任务可靠性度量,用任意同方差不确定性来捕捉任务之间的相对置信,为任务损失设置权重,来减少非对称多任务学习中的负迁移。在两个不同领域数据集(图像识别和药物基因组学)上进行了实验,结果表明,该方法有效减少了负迁移,有助于提高多任务学习的鲁棒性。
Multi-task learning (MTL) is frequently used in settings where a target task has to be learnt based on limited training data, but knowledge can be leveraged from related auxiliary tasks. While MTL can improve task performance overall relative to single-task learning (STL), these improvements can hide negative transfer (NT), where STL may deliver better performance for many individual tasks. Asymmetric multitask feature learning (AMTFL) is an approach that tries to address this by allowing tasks with higher loss values to have smaller influence on feature representations for learning other tasks. Task loss values do not necessarily indicate reliability of models for a specific task. We present examples of NT in two orthogonal datasets (image recognition and pharmacogenomics) and tackle this challenge by using aleatoric homoscedastic uncertainty to capture the relative confidence between tasks, and set weights for task loss. Our results show that this approach reduces NT providing a new approach to enable robust MTL.
https://weibo.com/1402400261/JAlDnEbT8
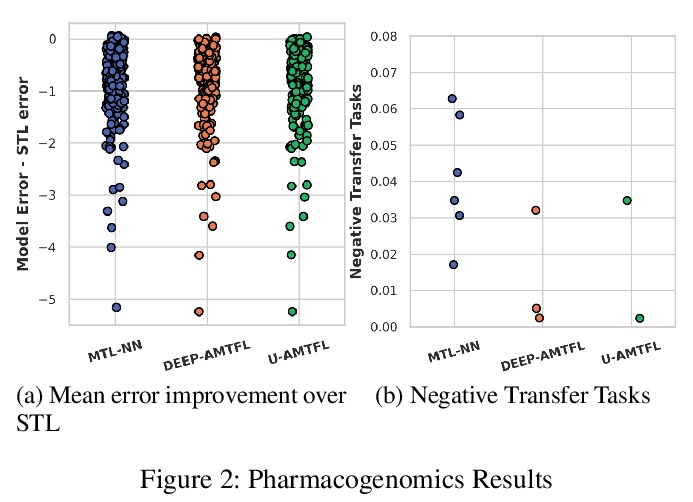
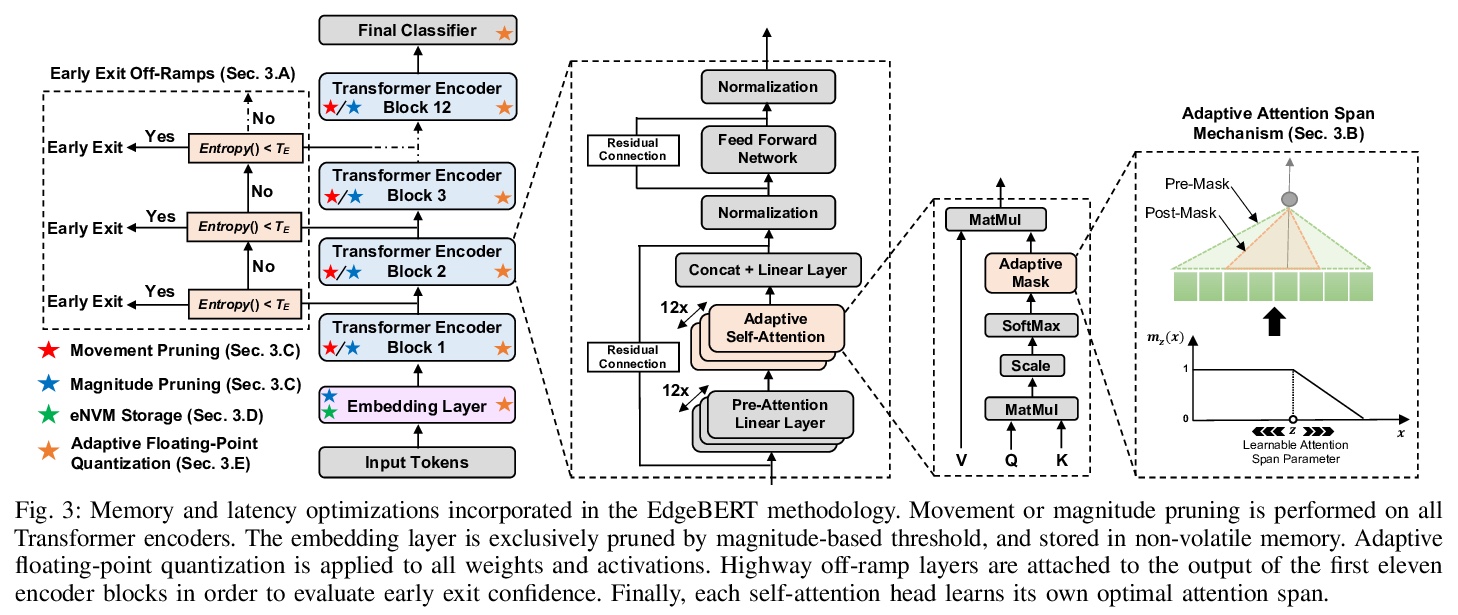
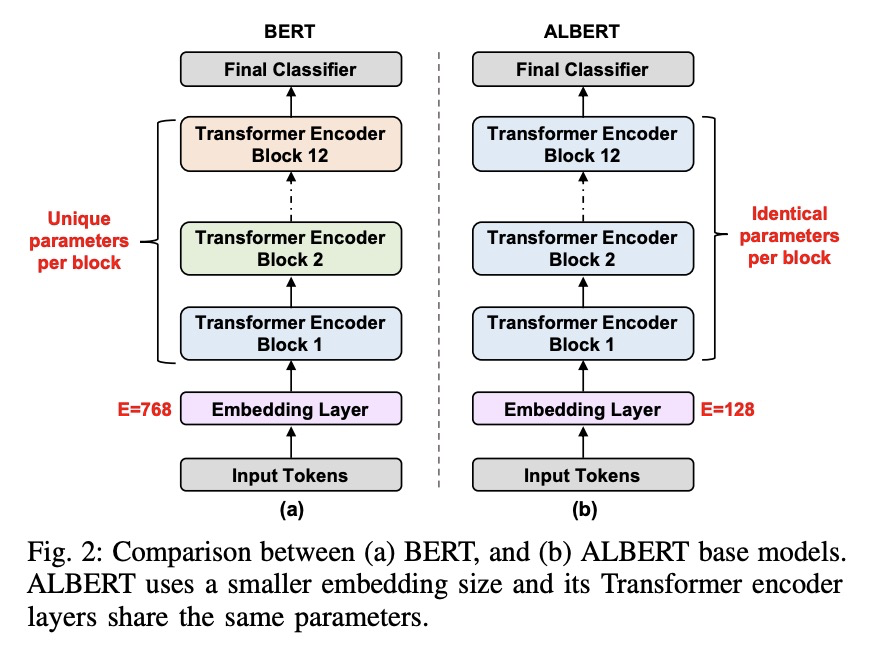
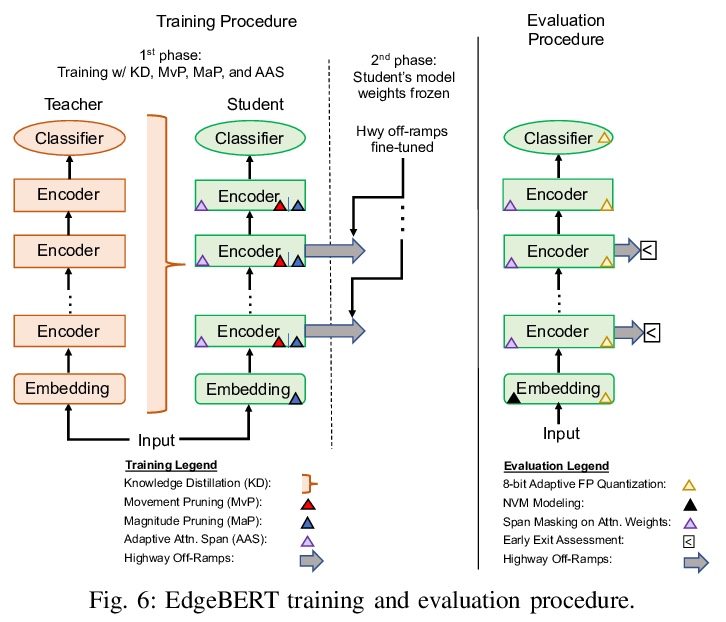
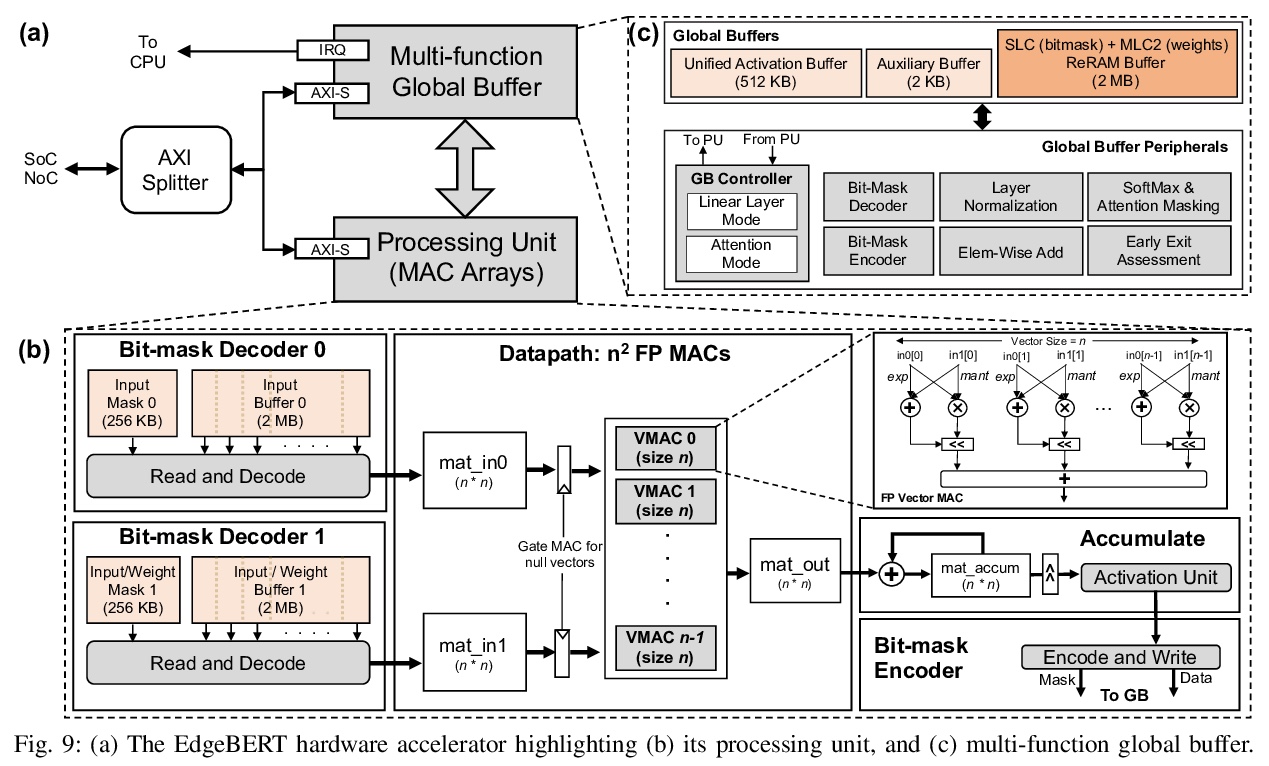
5、[CL] EdgeBERT: Optimizing On-Chip Inference for Multi-Task NLP
T Tambe, C Hooper, L Pentecost, E Yang, M Donato, V Sanh, A M. Rush, D Brooks, G Wei
[Harvard University & Tufts University & Hugging Face & Cornell University]
边缘设备片上多任务NLP推理优化。提出一种深入的、原则性算法和硬件设计方法,来最小化多任务NLP推理的延迟和能量消耗。通过 1)基于熵的早期停止,2)自适应的注意力跨度,3)运动和幅度修剪,4)浮点量化,与ALBERT基线相比,在多个GLUE基准上分别实现了2.4倍和13.4倍的推理延迟和内存节省,同时精度下降不到1%。设计了可扩展的硬件架构,将可共享的多任务嵌入参数的浮点编码,存储在高密度非易失性内存中。EdgeBERT能以5.2倍的速度实现NLP的全片上推理加速,比未优化的加速器和Nvidia Jetson Tegra X2移动GPU上的CUDA适配器的能量低157倍。
Transformer-based language models such as BERT provide significant accuracy improvement to a multitude of natural language processing (NLP) tasks. However, their hefty computational and memory demands make them challenging to deploy to resource-constrained edge platforms with strict latency requirements.We present EdgeBERT an in-depth and principled algorithm and hardware design methodology to achieve minimal latency and energy consumption on multi-task NLP inference. Compared to the ALBERT baseline, we achieve up to 2.4x and 13.4x inference latency and memory savings, respectively, with less than 1%-pt drop in accuracy on several GLUE benchmarks by employing a calibrated combination of 1) entropy-based early stopping, 2) adaptive attention span, 3) movement and magnitude pruning, and 4) floating-point quantization.Furthermore, in order to maximize the benefits of these algorithms in always-on and intermediate edge computing settings, we specialize a scalable hardware architecture wherein floating-point bit encodings of the shareable multi-task embedding parameters are stored in high-density non-volatile memory. Altogether, EdgeBERT enables fully on-chip inference acceleration of NLP workloads with 5.2x, and 157x lower energy than that of an un-optimized accelerator and CUDA adaptations on an Nvidia Jetson Tegra X2 mobile GPU, respectively.
https://weibo.com/1402400261/JAlKWAYmC
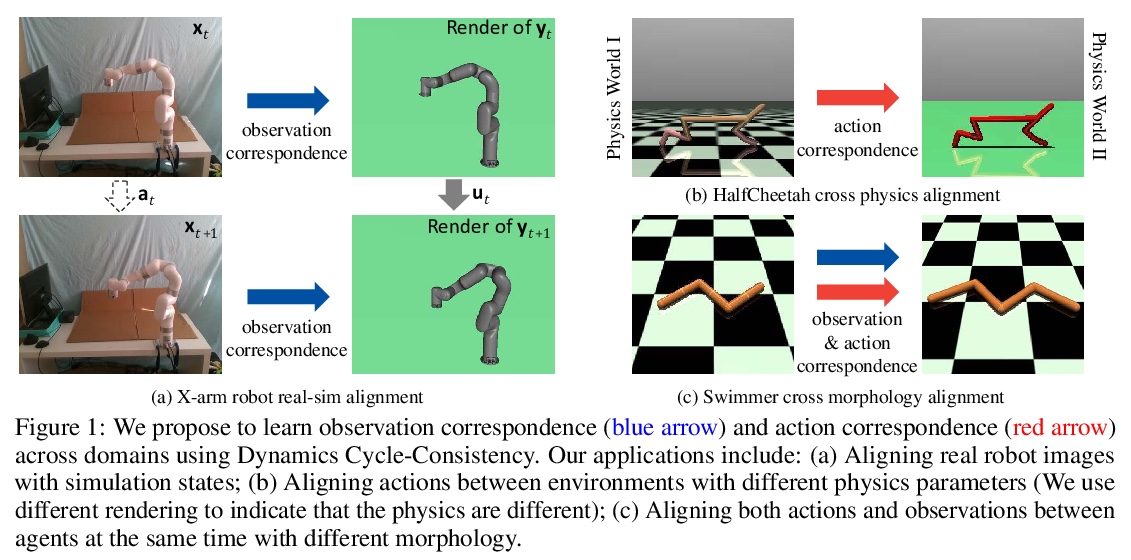
[RO] Learning Cross-Domain Correspondence for Control with Dynamics Cycle-Consistency
动态循环一致控制的跨域对应学习
Q Zhang, T Xiao, A A. Efros, L Pinto, X Wang
[Shanghai Jiao Tong University & UC Berkeley & New York University & UC San Diego]
https://weibo.com/1402400261/JAlR73E0k
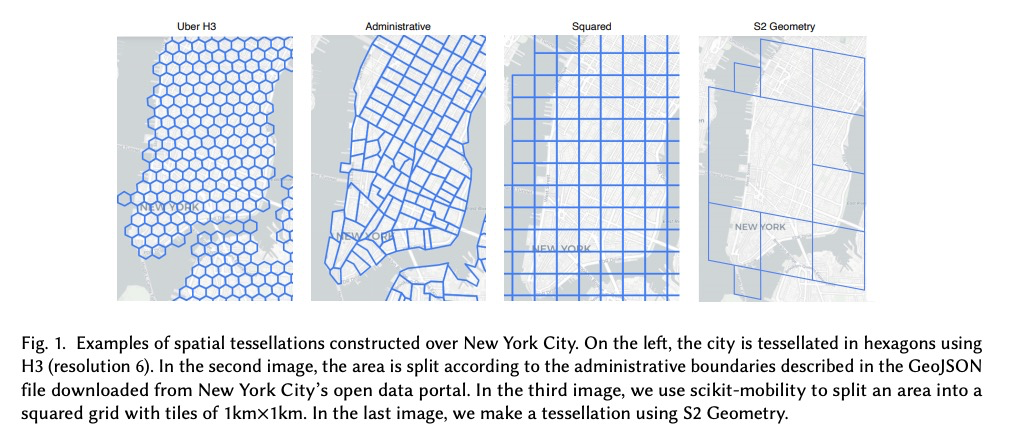
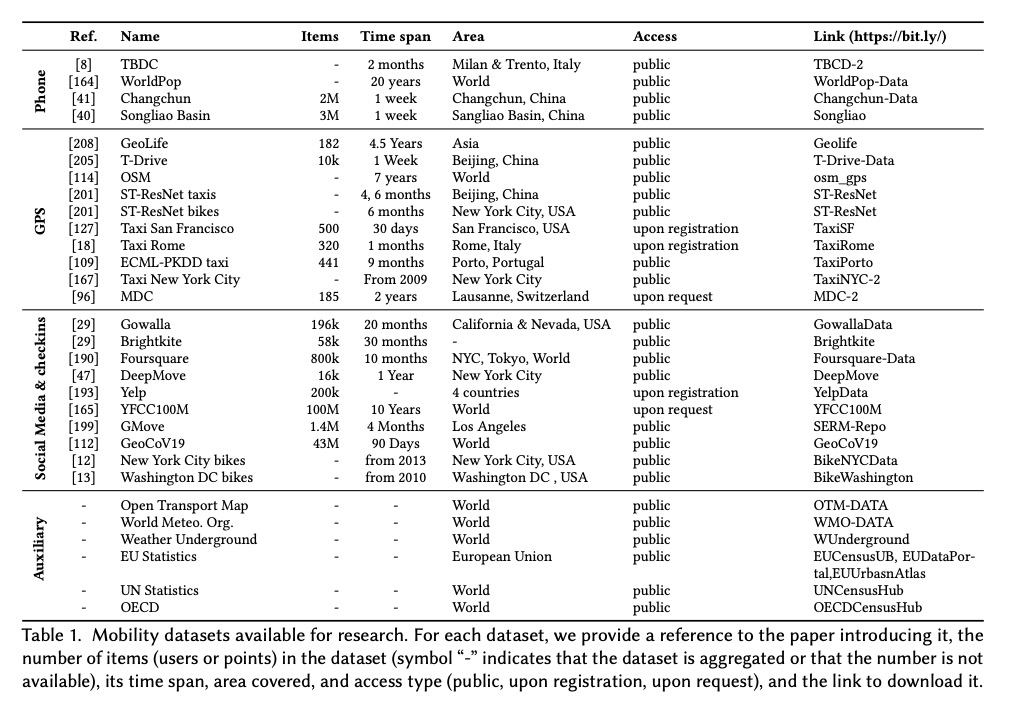
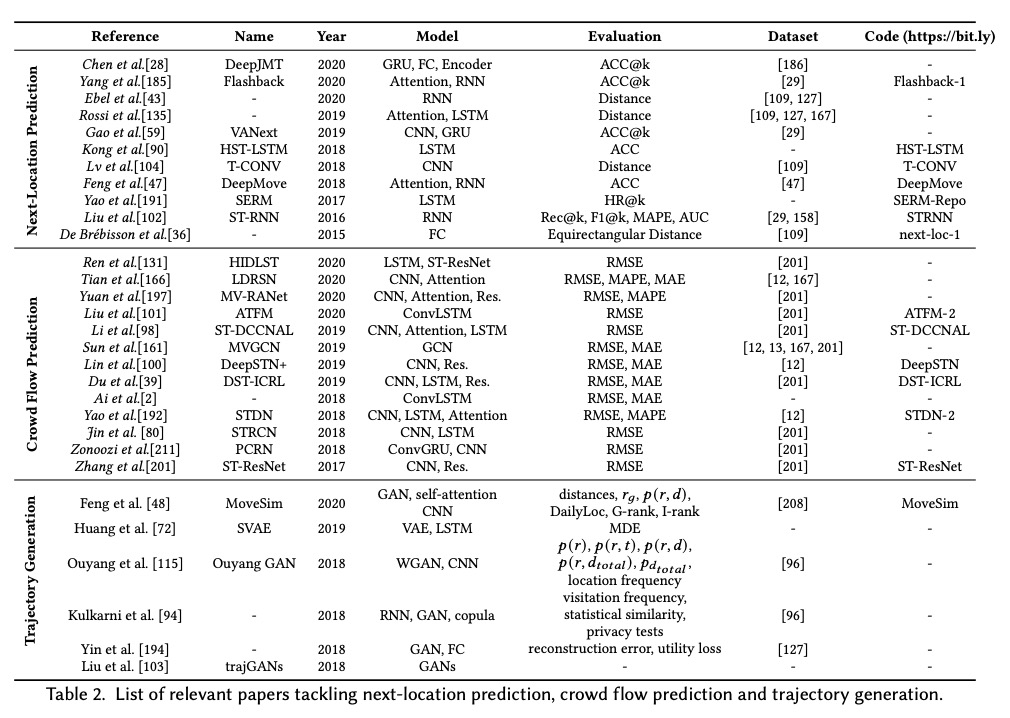
[LG] Deep Learning for Human Mobility: a Survey on Data and Models
人口流动性深度学习:数据和模型综述
M Luca, G Barlacchi, B Lepri, L Pappalardo
[Italy and Free University of Bolzano & Amazon Alexa & Fondazione Bruno Kessler (FBK)]
https://weibo.com/1402400261/JAlUIs5HU
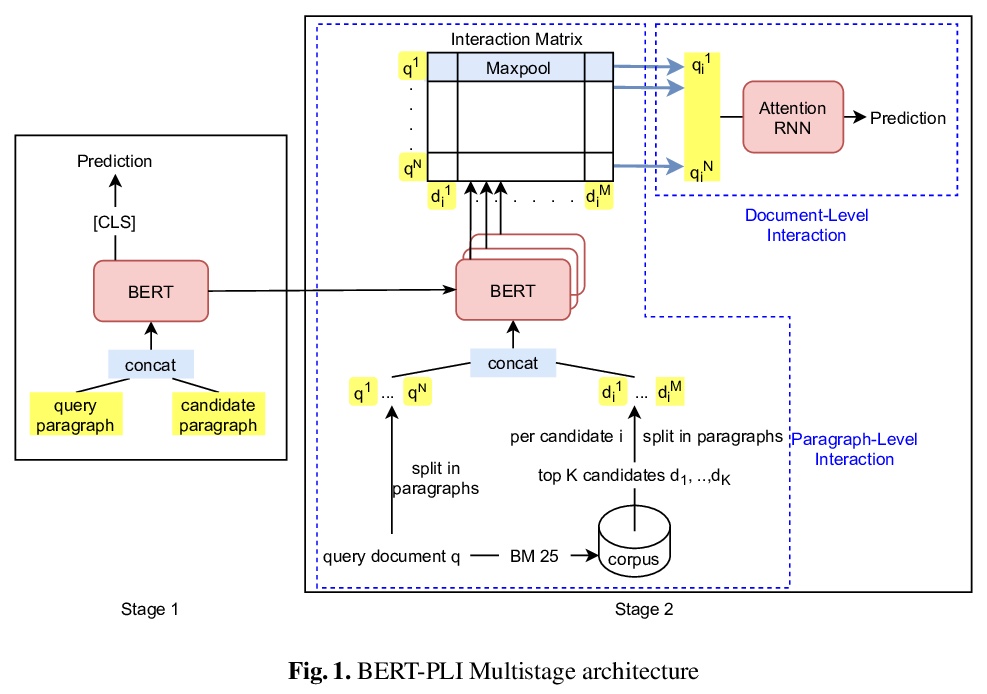
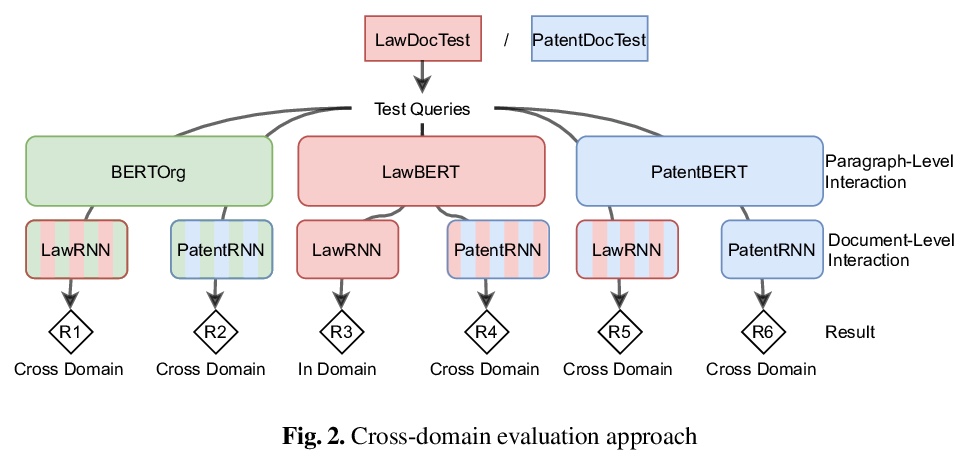
[IR] Cross-domain Retrieval in the Legal and Patent Domains: a Reproducability Study
法律、专利领域的跨领域检索:可复现性研究
S Althammer, S Hofstätter, A Hanbury
[TU Wien]
https://weibo.com/1402400261/JAlWzmI3S
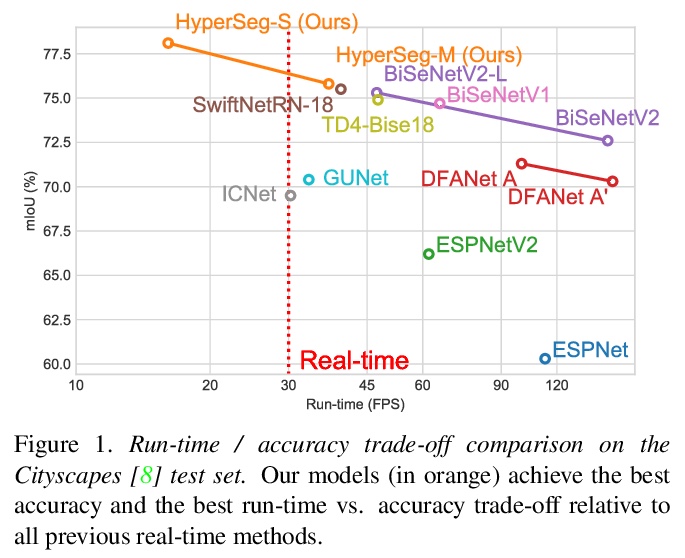
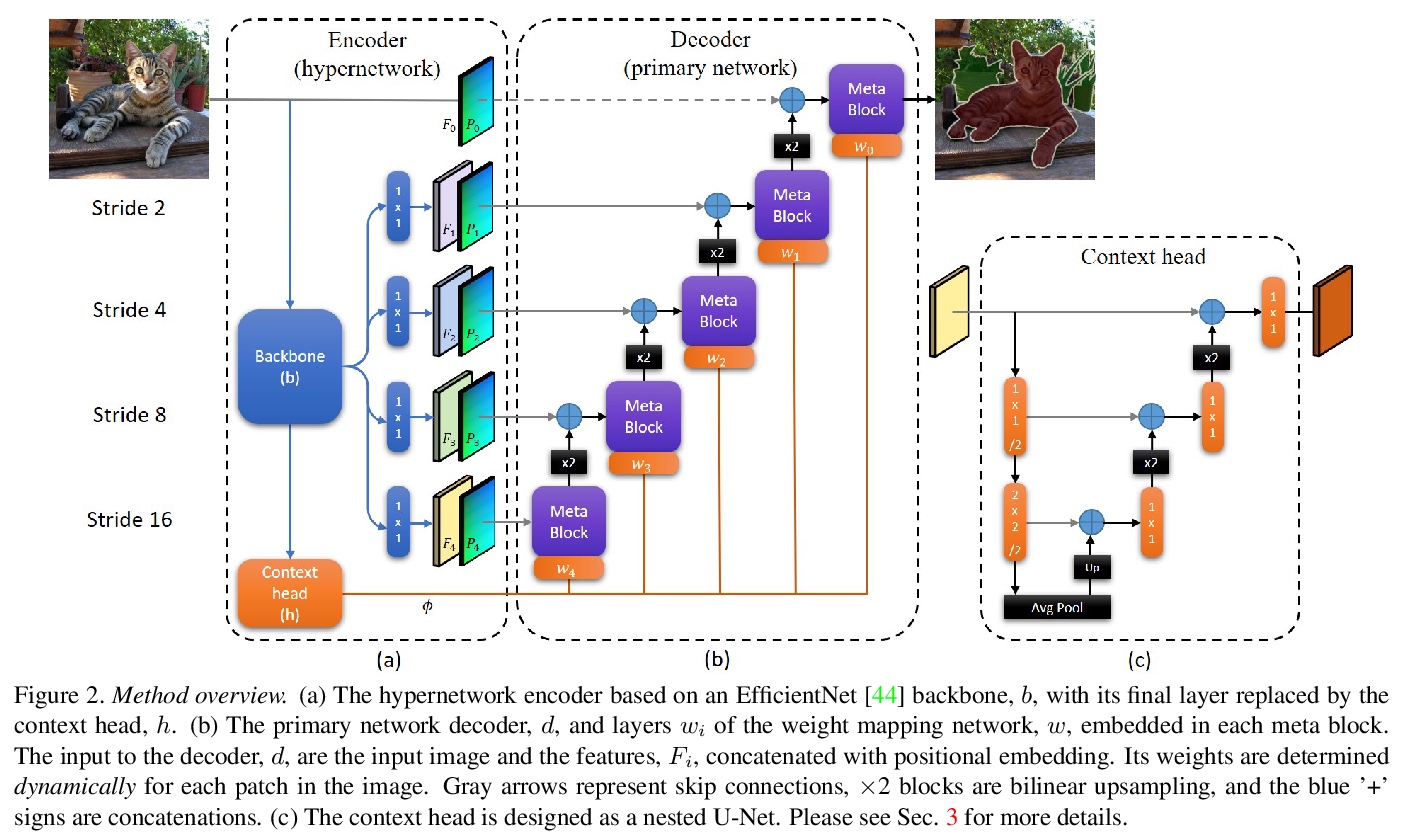
[CV] HyperSeg: Patch-wise Hypernetwork for Real-time Semantic Segmentation
HyperSeg:图块级超网络实时语义分割
Y Nirkin, L Wolf, T Hassner
[Facebook AI]
https://weibo.com/1402400261/JAm1PgdA5


若有收获,就点个赞吧
0 人点赞
