- 1、[LG] Reverb: A Framework For Experience Replay
- 2、[LG] Directive Explanations for Actionable Explainability in Machine Learning Applications
- 3、[LG] Towards a reinforcement learning de novo genome assembler
- 4、[AS] LightSpeech: Lightweight and Fast Text to Speech with Neural Architecture Search
- 5、[LG] Neural SDEs as Infinite-Dimensional GANs
- [AS] Expressive Neural Voice Cloning
- [CL] Stereotype and Skew: Quantifying Gender Bias in Pre-trained and Fine-tuned Language Models
- [CV] S: Neural Shape, Skeleton, and Skinning Fields for 3D Human Modeling
- [AS] Speech Emotion Recognition with Multiscale Area Attention and Data Augmentation
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Reverb: A Framework For Experience Replay
A Cassirer, G Barth-Maron, E Brevdo, S Ramos, T Boyd, T Sottiaux, M Kroiss
[DeepMind & Google Research]
Reverb:强化学习经验回放框架。Reverb是专为强化学习经验重放而设计的高效、可扩展、易于使用的系统,其设计是灵活的,适合用于经验重放或优先经验重放——众多非策略算法的关键组成部分。其设计是为了在分布式配置中高效工作,非常适合于大规模的强化学习智能体,许多演员和学习者并行运行,最多可容纳数千并发客户端。灵活的API为用户提供了方便、准确配置重放缓冲区的工具。包括从缓冲区中选择和移除元素的策略,以及控制采样和插入元素之间比例的选项。
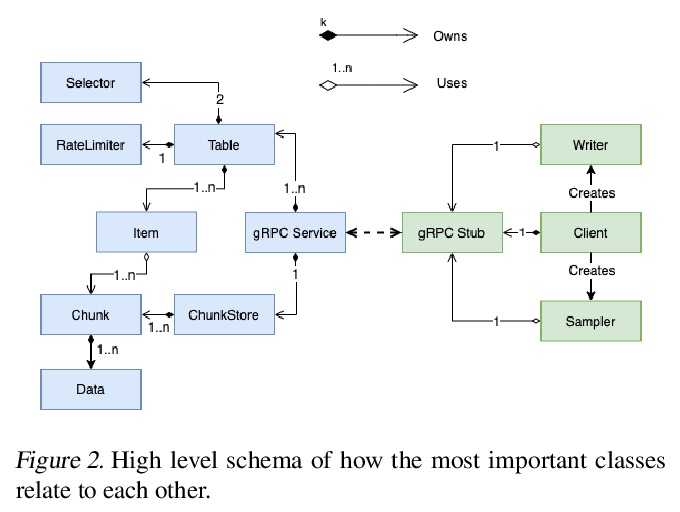
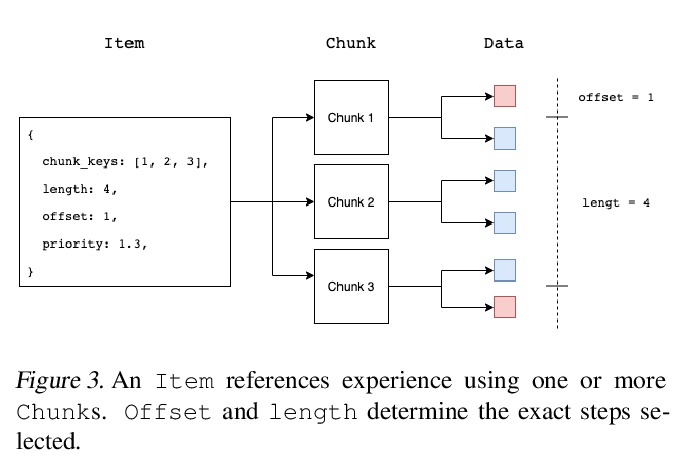
A central component of training in Reinforcement Learning (RL) is Experience: the data used for training. The mechanisms used to generate and consume this data have an important effect on the performance of RL algorithms.In this paper, we introduce Reverb: an efficient, extensible, and easy to use system designed specifically for experience replay in RL. Reverb is designed to work efficiently in distributed configurations with up to thousands of concurrent clients.The flexible API provides users with the tools to easily and accurately configure the replay buffer. It includes strategies for selecting and removing elements from the buffer, as well as options for controlling the ratio between sampled and inserted elements. This paper presents the core design of Reverb, gives examples of how it can be applied, and provides empirical results of Reverb’s performance characteristics.
https://weibo.com/1402400261/K1Z7A9tmW

2、[LG] Directive Explanations for Actionable Explainability in Machine Learning Applications
R Singh, P Dourish, P Howe, T Miller, L Sonenberg, E Velloso, F Vetere
[The University of Melbourne & University of California, Irvine]
对机器学习应用中的可操作性解释的指导性说明。研究了用指令性解释来帮助实现机器学习辅助决策的前景。指令性解释列出了人工需要采取哪些具体行动来实现其期望的结果。如果机器学习模型做出了对人不利的决策(例如拒绝贷款申请),那么它既要解释为什么会做出该决策,也要解释人如何才能获得他们期望的结果(如果可能的话)。这通常是用反事实解释来完成的,但一般不会告诉个体如何行动。反事实解释可通过明确地向人们提供他们可以用来实现预期目标的行动来改进。进行了一项在线研究,调查人们对指令性解释的看法。提出了一个概念模型来生成这种解释。在线研究表明,人们对指令性解释有显著偏好(P <0.001)。参与者的首选解释类型受到多种因素的影响,如个人偏好、社会因素和指令的可行性。该研究结果凸显了创建指令性解释时需要以人为本和针对具体情境的方法。
This paper investigates the prospects of using directive explanations to assist people in achieving recourse of machine learning decisions. Directive explanations list which specific actions an individual needs to take to achieve their desired outcome. If a machine learning model makes a decision that is detrimental to an individual (e.g. denying a loan application), then it needs to both explain why it made that decision and also explain how the individual could obtain their desired outcome (if possible). At present, this is often done using counterfactual explanations, but such explanations generally do not tell individuals how to act. We assert that counterfactual explanations can be improved by explicitly providing people with actions they could use to achieve their desired goal. This paper makes two contributions. First, we present the results of an online study investigating people’s perception of directive explanations. Second, we propose a conceptual model to generate such explanations. Our online study showed a significant preference for directive explanations (> p<0.001). However, the participants’ preferred explanation type was affected by multiple factors, such as individual preferences, social factors, and the feasibility of the directives. Our findings highlight the need for a human-centred and context-specific approach for creating directive explanations.
https://weibo.com/1402400261/K1ZeSeuZD


3、[LG] Towards a reinforcement learning de novo genome assembler
K Padovani, R Xavier, A Carvalho, A Reali, A Chateau, R Alves
[Federal University of Para & Vale Technology Institute & University of Sao Paulo]
基于强化学习的从头基因组组装。基因组组装是基因组学项目中最相关、计算最复杂的任务之一,组装软件没提供类似的基因组作为参考时,组装就会变得更加复杂(这种情况被称为de novo)。本工作旨在阐明如何应用强化学习来解决基因组组装这一现实世界问题。通过扩展文献中发现的唯一解决这一问题的方法,仔细探索了由Q-learning算法执行的智能体学习的各个方面,以了解其是否适合应用于与真实基因组项目所面临的特征更为相似的场景中。这里提出的改进措施包括改变之前的奖励系统,加入基于动态修剪和与进化计算相互协作的状态空间探索优化策略。在23个新的环境上进行了尝试,结果表明,使用所提出的改进措施,在性能上取得了一致的进步,然而,也证明了它们的局限性,特别是与状态和动作空间的高维度有关。
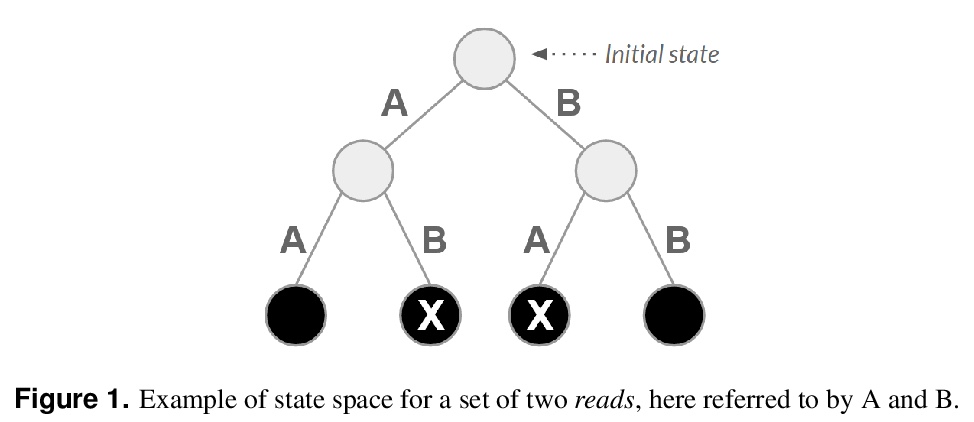
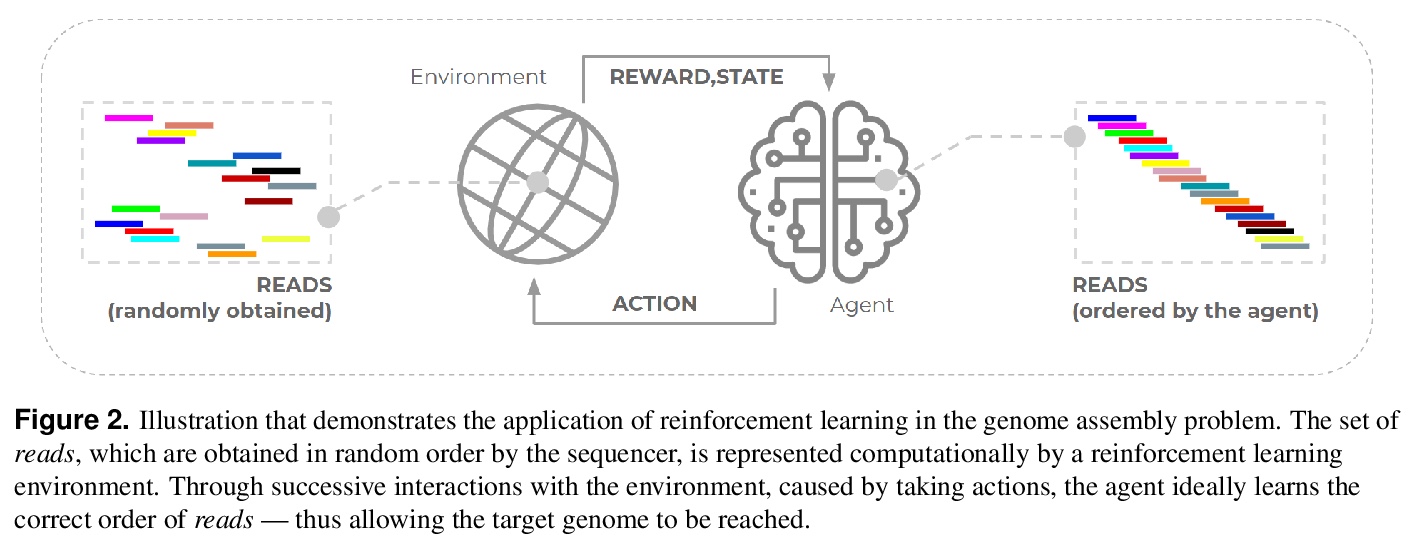
The use of reinforcement learning has proven to be very promising for solving complex activities without human supervision during their learning process. However, their successful applications are predominantly focused on fictional and entertainment problems - such as games. Based on the above, this work aims to shed light on the application of reinforcement learning to solve this relevant real-world problem, the genome assembly. By expanding the only approach found in the literature that addresses this problem, we carefully explored the aspects of intelligent agent learning, performed by the Q-learning algorithm, to understand its suitability to be applied in scenarios whose characteristics are more similar to those faced by real genome projects. The improvements proposed here include changing the previously proposed reward system and including state space exploration optimization strategies based on dynamic pruning and mutual collaboration with evolutionary computing. These investigations were tried on 23 new environments with larger inputs than those used previously. All these environments are freely available on the internet for the evolution of this research by the scientific community. The results suggest consistent performance progress using the proposed improvements, however, they also demonstrate the limitations of them, especially related to the high dimensionality of state and action spaces. We also present, later, the paths that can be traced to tackle genome assembly efficiently in real scenarios considering recent, successfully reinforcement learning applications - including deep reinforcement learning - from other domains dealing with high-dimensional inputs.
https://weibo.com/1402400261/K1Zlaz346

4、[AS] LightSpeech: Lightweight and Fast Text to Speech with Neural Architecture Search
R Luo, X Tan, R Wang, T Qin, J Li, S Zhao, E Chen, T Liu
[University of Science and Technology of China & Microsoft Research Asia & Microsoft Azure Speech]
LightSpeech:基于神经架构搜索的轻量快速文字转语音。提出LightSpeech,利用神经架构搜索(NAS)来发现轻量和快速的文字转语音(TTS)模型。分析了原FastSpeech 2模型中各模块的内存和延迟,设计了相应改进,包括模型骨干和包含各种轻量级和潜在有效架构的搜索空间。采用GBDT-NAS来搜索性能好、效率高的架构。实验表明,与FastSpeech 2相比,发现的轻量级模型在CPU上实现了15倍的压缩比,减少了16倍的MAC,推理速度提升了6.5倍,音频质量与FastSpeech 2持平。
Text to speech (TTS) has been broadly used to synthesize natural and intelligible speech in different scenarios. Deploying TTS in various end devices such as mobile phones or embedded devices requires extremely small memory usage and inference latency. While non-autoregressive TTS models such as FastSpeech have achieved significantly faster inference speed than autoregressive models, their model size and inference latency are still large for the deployment in resource constrained devices. In this paper, we propose LightSpeech, which leverages neural architecture search~(NAS) to automatically design more lightweight and efficient models based on FastSpeech. We first profile the components of current FastSpeech model and carefully design a novel search space containing various lightweight and potentially effective architectures. Then NAS is utilized to automatically discover well performing architectures within the search space. Experiments show that the model discovered by our method achieves 15x model compression ratio and 6.5x inference speedup on CPU with on par voice quality. Audio demos are provided at > this https URL.
https://weibo.com/1402400261/K1ZpXw88Y
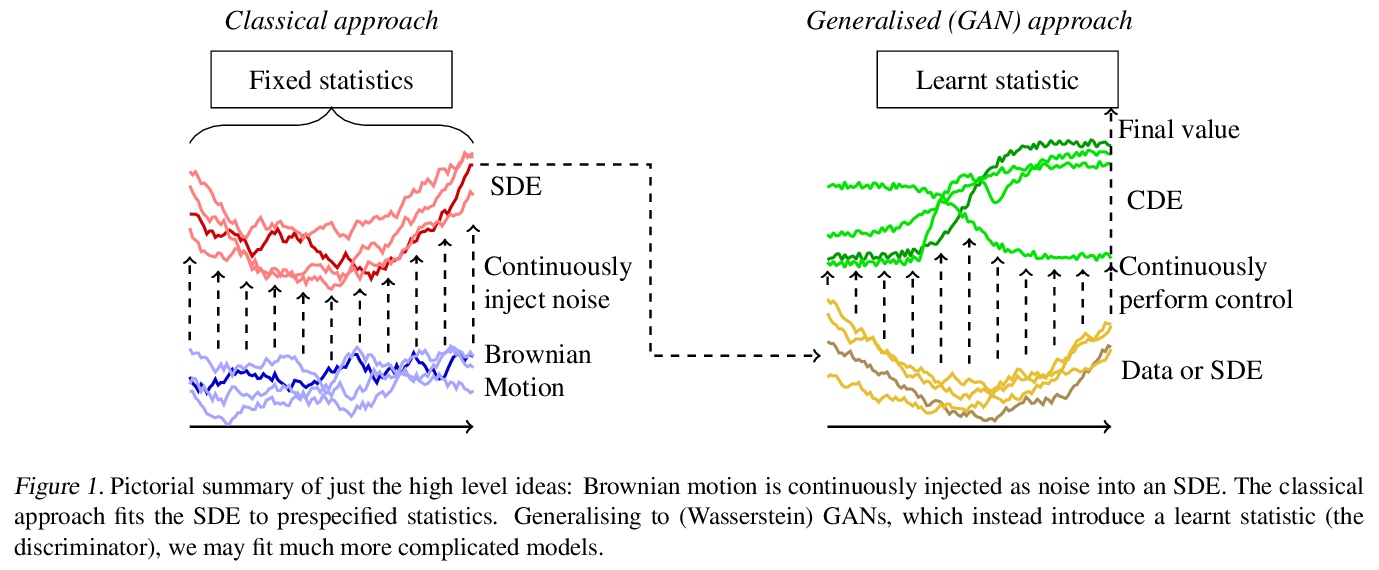
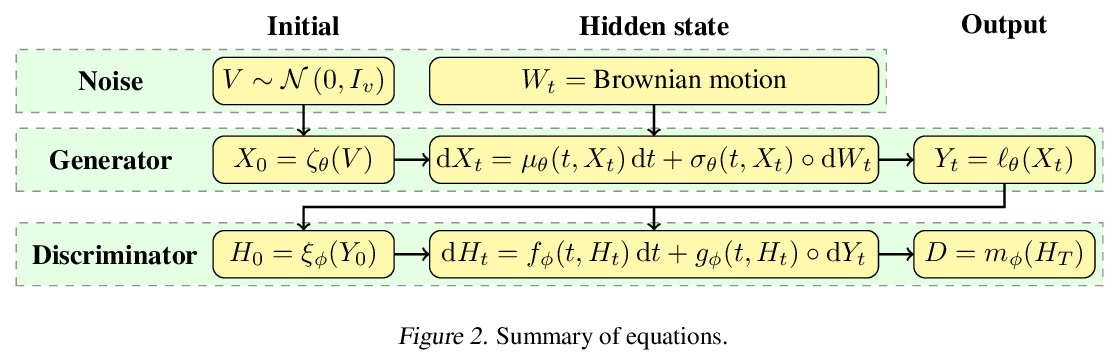
5、[LG] Neural SDEs as Infinite-Dimensional GANs
P Kidger, J Foster, X Li, H Oberhauser, T Lyons
[University of Oxford]
神经随机微分方程与无限维对抗生成网络。本文表明,经典的随机微分方程(SDE)拟合方法可作为(Wasserstein)GANs的一种特殊情况来处理,神经网络和经典方法可以合在一起。输入噪声是布朗运动,输出样本是数值求解器产生的时间演化路径,通过将判别器参数化为神经可控微分方程(CDE),得到神经SDE作为连续时间生成的时间序列模型。与以往关于这个问题的工作不同,这是经典方法的直接扩展,既没有参考预先指定的统计量,也没有参考密度函数。任意的漂移和扩散是可以接受的,由于Wasserstein损失具有唯一的全局最小值,在无限的数据极限中,任何SDE都可以被学习。该方法扩展了现有的经典SDE建模方法——用预先指定的报酬函数——可集成到现有的SDE建模工作流程中。
Stochastic differential equations (SDEs) are a staple of mathematical modelling of temporal dynamics. However, a fundamental limitation has been that such models have typically been relatively inflexible, which recent work introducing Neural SDEs has sought to solve. Here, we show that the current classical approach to fitting SDEs may be approached as a special case of (Wasserstein) GANs, and in doing so the neural and classical regimes may be brought together. The input noise is Brownian motion, the output samples are time-evolving paths produced by a numerical solver, and by parameterising a discriminator as a Neural Controlled Differential Equation (CDE), we obtain Neural SDEs as (in modern machine learning parlance) continuous-time generative time series models. Unlike previous work on this problem, this is a direct extension of the classical approach without reference to either prespecified statistics or density functions. Arbitrary drift and diffusions are admissible, so as the Wasserstein loss has a unique global minima, in the infinite data limit \textit{any} SDE may be learnt.
https://weibo.com/1402400261/K1ZuSbqe5

另外几篇值得关注的论文:
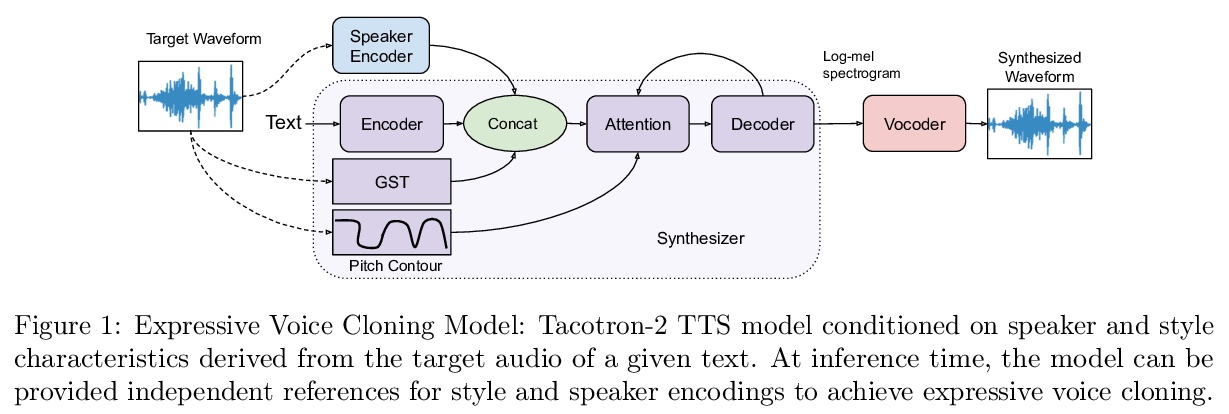
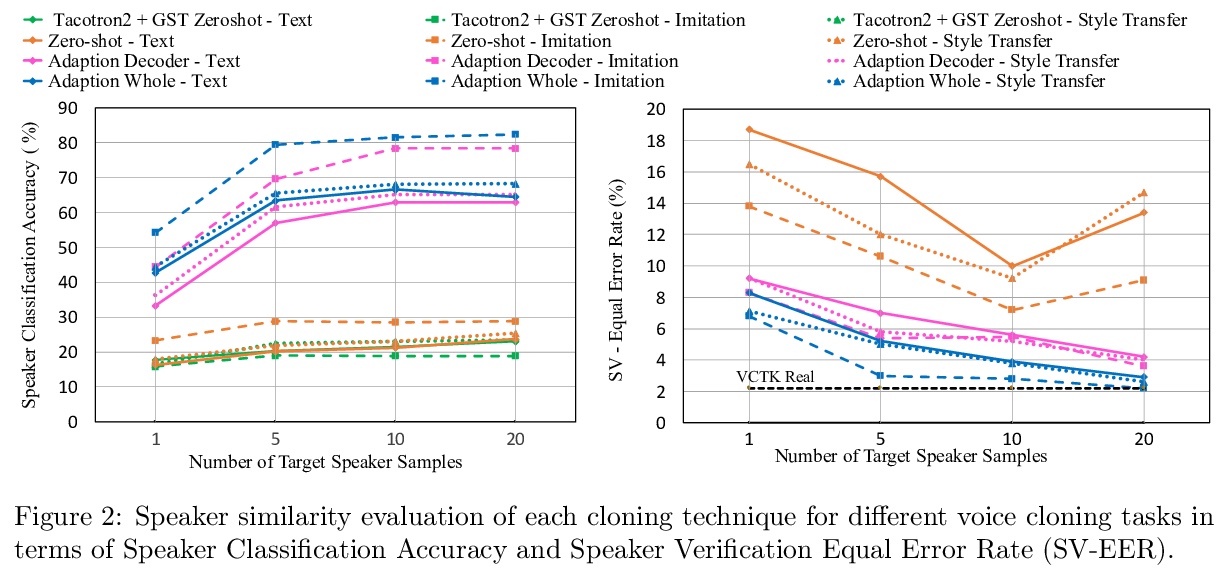
[AS] Expressive Neural Voice Cloning
富有表现力的神经网络可控语音克隆
P Neekhara, S Hussain, S Dubnov, F Koushanfar, J McAuley
[University of California San Diego]
https://weibo.com/1402400261/K1Zyy0XDN
[CL] Stereotype and Skew: Quantifying Gender Bias in Pre-trained and Fine-tuned Language Models
刻板印象与偏离:预训练和微调语言模型性别偏见量化
D d V Manela, D Errington, T Fisher, B v Breugel, P Minervini
[University College London]
https://weibo.com/1402400261/K1ZzYEDri


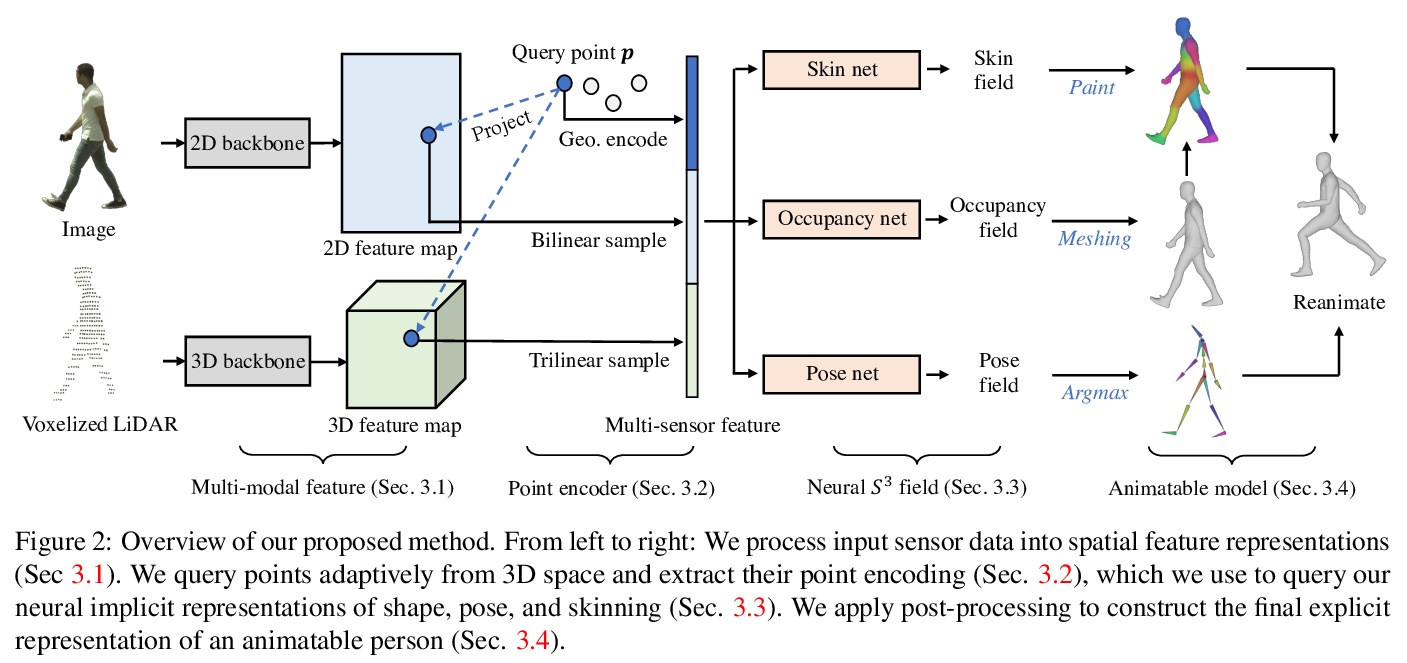
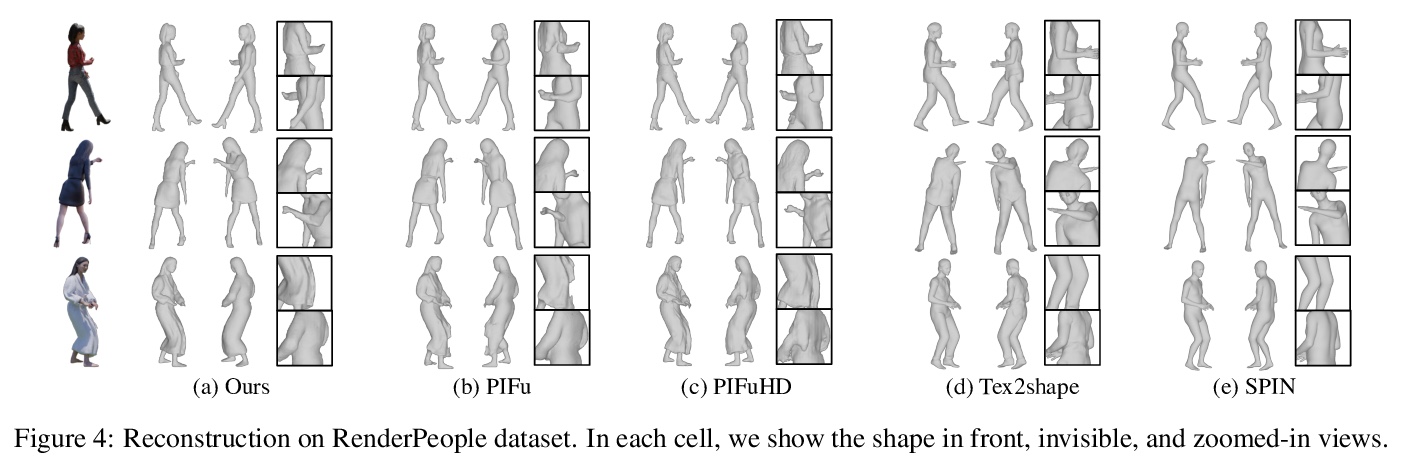
[CV] S: Neural Shape, Skeleton, and Skinning Fields for 3D Human Modeling
S:基于神经形状、骨架和皮肤场的3D人体建模
Z Yang, S Wang, S Manivasagam, Z Huang, W Ma, X Yan, E Yumer, R Urtasun
[Uber Advanced Technologies Group & University of Southern California]
https://weibo.com/1402400261/K1ZDA17FX

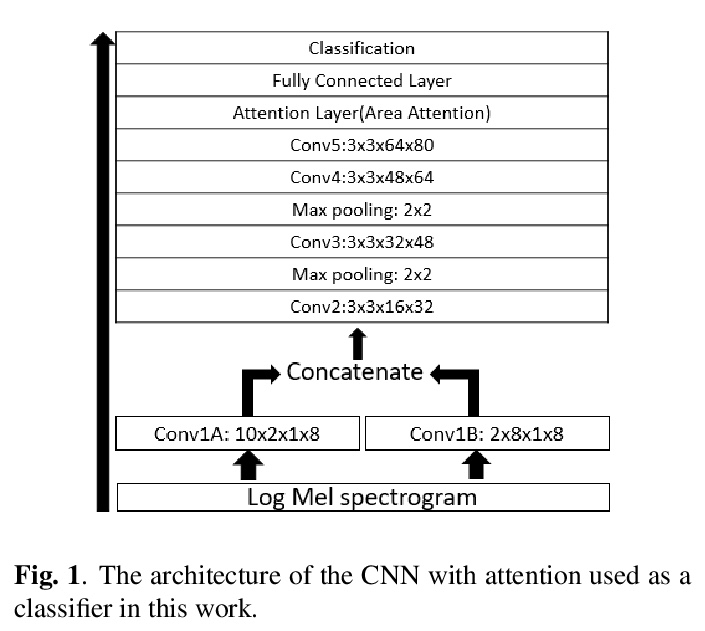
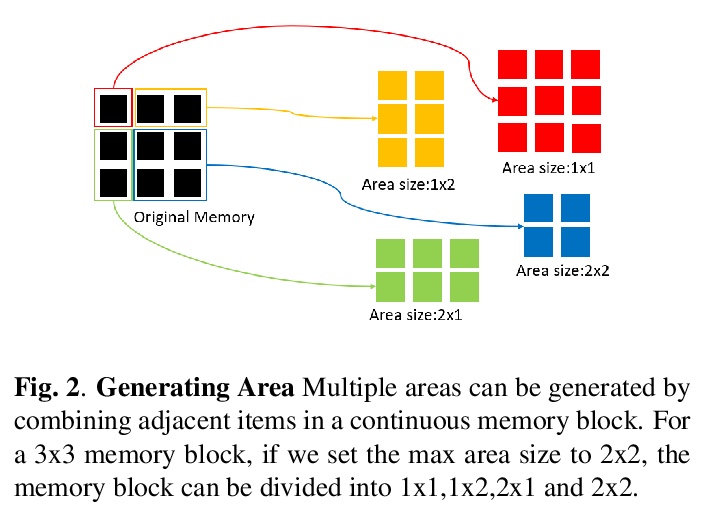
[AS] Speech Emotion Recognition with Multiscale Area Attention and Data Augmentation
基于多尺度区域注意和数据增广的语音情感识别
M Xu, F Zhang, X Cui, W Zhang
[Nanjing Tech University & IBM Data and AI & IBM Research AI]
https://weibo.com/1402400261/K1ZFd7TIA

若有收获,就点个赞吧
0 人点赞
