- 1、[CL] Cutting Down on Prompts and Parameters: Simple Few-Shot Learning with Language Models
- 2、[CL] On the Diversity and Limits of Human Explanations
- 3、[CV] Giraffe: Representing scenes as compositional generative neural feature fields
- 4、[CV] Time Lens: Event-based Video Frame Interpolation
- 5、[LG] Model-Based Reinforcement Learning via Latent-Space Collocation
- [CV] To the Point: Efficient 3D Object Detection in the Range Image with Graph Convolution Kernels
- [RO] Multi-Robot Deep Reinforcement Learning for Mobile Navigation
- [CV] Shape As Points: A Differentiable Poisson Solver
- [AS] Scaling Laws for Acoustic Models
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CL] Cutting Down on Prompts and Parameters: Simple Few-Shot Learning with Language Models
R L. L IV, I Balažević, E Wallace, F Petroni, S Singh, S Riedel
[University of Edinburgh & UC Berkeley & Facebook AI Research]
减少提示和参数:基于语言模型的简单少样本学习。使用训练样本和任务描述的提示语言模型 (LM) 被视为近期小样本学习取得成功的关键。本文表明在少样本设置中微调语言模型可以大大减少对提示工程的需求。事实上,可以使用空提示,既不包含特定任务模板也不包含训练样本的提示,在范围广泛的任务中实现与手工微调的提示相比有竞争力的准确度。虽然微调语言模型确实为每个下游任务引入了新参数,但可以显著减少这种内存开销:仅微调偏差项可以实现与标准微调相当或更好的精度,同时仅更新 0.1% 的参数。总之,建议对语言模型进行微调以进行小样本学习,因为它更准确、对不同提示具有鲁棒性,并且可以与使用冻结语言模型几乎一样有效。
Prompting language models (LMs) with training examples and task descriptions has been seen as critical to recent successes in few-shot learning. In this work, we show that finetuning LMs in the few-shot setting can considerably reduce the need for prompt engineering. In fact, one can use null prompts, prompts that contain neither taskspecific templates nor training examples, and achieve competitive accuracy to manuallytuned prompts across a wide range of tasks. While finetuning LMs does introduce new parameters for each downstream task, we show that this memory overhead can be substantially reduced: finetuning only the bias terms can achieve comparable or better accuracy than standard finetuning while only updating 0.1% of the parameters. All in all, we recommend finetuning LMs for few-shot learning as it is more accurate, robust to different prompts, and can be made nearly as efficient as using frozen LMs.
https://weibo.com/1402400261/KmmnLvYkP 




2、[CL] On the Diversity and Limits of Human Explanations
C Tan
[University of Chicago]
人工解释的多样性和局限性。NLP 越来越多的努力旨在构建人工解释的数据集。然而,解释一词包含了广泛的概念,每个概念都有不同的属性和后果。本文的目标是提供一个不同类型的解释和人工局限性的概述,并讨论在NLP中收集和使用解释的意义。受心理学和认知科学先前工作的启发,将NLP中现有的人工解释分为三类:近似机制、证据和程序。这三类性质不同,并且对由此产生的解释有影响。例如,程序在心理学中不被视为解释,而是与从指令中学习的大量工作相联系。解释的多样性进一步体现在代理问题上,这些代理问题是标记者解释和回答开放式的为什么问题所需要的。最后,解释可能需要与预测不同的,通常是更深层次的理解,这让人怀疑人工是否能在某些任务中提供有用的解释。
A growing effort in NLP aims to build datasets of human explanations. However, the term explanation encompasses a broad range of notions, each with different properties and ramifications. Our goal is to provide an overview of diverse types of explanations and human limitations, and discuss implications for collecting and using explanations in NLP. Inspired by prior work in psychology and cognitive sciences, we group existing human explanations in NLP into three categories: proximal mechanism, evidence, and procedure. These three types differ in nature and have implications for the resultant explanations. For instance, procedure is not considered explanations in psychology and connects with a rich body of work on learning from instructions. The diversity of explanations is further evidenced by proxy questions that are needed for annotators to interpret and answer open-ended why questions. Finally, explanations may require different, often deeper, understandings than predictions, which casts doubt on whether humans can provide useful explanations in some tasks.
https://weibo.com/1402400261/Kmms7ywpl 



3、[CV] Giraffe: Representing scenes as compositional generative neural feature fields
M Niemeyer, A Geiger
[Max Planck Institute for Intelligent Systems]
GIRAFFE:将场景表示为组合生成式神经特征场。深度生成模型允许在高分辨率下进行逼真的图像合成。但对许多应用来说不够:内容创建也需要可控。虽然最近的一些工作研究了如何解缠数据中的潜变化因素,但大多是在2D中操作,忽略了世界的3D属性。此外,只有少数工作考虑到了场景的组合性。本文的关键假设是,将组合式3D场景表示纳入生成模型,可以使图像合成更可控。将场景表示为生成式神经特征场,能从背景中分离出一个或多个物体,以及单个物体的形状和外观,同时无需任何额外的监督,就能从非结构化和非姿态化的图像集中学习。将这种场景表示与神经渲染管道结合起来,可以产生快速而真实的图像合成模型。实验表明,该模型能解缠单个物体,并允许在场景中平移和旋转它们,以及改变相机姿态。
Deep generative models allow for photorealistic image synthesis at high resolutions. But for many applications, this is not enough: content creation also needs to be controllable. While several recent works investigate how to disentangle underlying factors of variation in the data, most of them operate in 2D and hence ignore that our world is three-dimensional. Further, only few works consider the compositional nature of scenes. Our key hypothesis is that incorporating a compositional 3D scene representation into the generative model leads to more controllable image synthesis. Representing scenes as compositional generative neural feature fields allows us to disentangle one or multiple objects from the background as well as individual objects’ shapes and appearances while learning from unstructured and unposed image collections without any additional supervision. Combining this scene representation with a neural rendering pipeline yields a fast and realistic image synthesis model. As evidenced by our experiments, our model is able to disentangle individual objects and allows for translating and rotating them in the scene as well as changing the camera pose.
https://weibo.com/1402400261/Kmmyz7fVa 




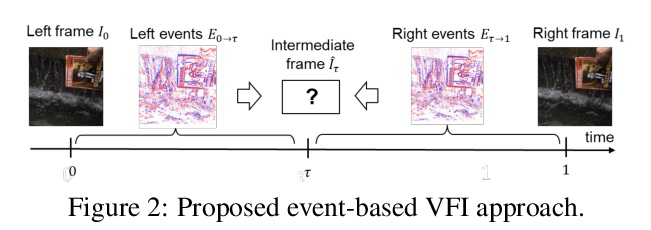
4、[CV] Time Lens: Event-based Video Frame Interpolation
S. Tulyakov, D. Gehrig, S. Georgoulis, J. Erbach, M. Gehrig, Y. Li, D. Scaramuzza
[Huawei Technologies & ETH Zurich]
Time Lens:基于事件的视频帧插值。最先进的帧插值方法,通过从连续关键帧推断图像中的物体运动来生成中间帧。在没有额外信息的情况下,必须使用一阶近似值,即光流,但这种选择限制了可以建模的运动类型,导致在高动态场景中出现错误。事件相机是一种新型传感器,通过在帧间盲时提供辅助视觉信息来解决这一限制,通过异步测量每像素亮度变化,以高时间分辨率和低延迟来完成这一工作。基于事件的帧插值方法通常采用基于合成的方法,其中预测的帧残差直接应用于关键帧。虽然这些方法可以捕捉到非线性运动,但受到重影的影响,在少事件低纹理区域表现不佳。因此,基于合成的方法和基于流的方法是互补的。本文提出一种新方法Time Lens,利用了两者的优势,在三个合成基准和两个真实基准上进行了广泛的评估,与最先进的基于帧和基于事件的方法相比,显示了高达5.21dB的PSNR改进。在高动态场景中发布了一个新的大规模数据集,旨在挑战现有方法的极限。
State-of-the-art frame interpolation methods generate intermediate frames by inferring object motions in the image from consecutive key-frames. In the absence of additional information, first-order approximations, i.e. optical flow, must be used, but this choice restricts the types of motions that can be modeled, leading to errors in highly dynamic scenarios. Event cameras are novel sensors that address this limitation by providing auxiliary visual information in the blind-time between frames. They asynchronously measure per-pixel brightness changes and do this with high temporal resolution and low latency. Event-based frame interpolation methods typically adopt a synthesis-based approach, where predicted frame residuals are directly applied to the key-frames. However, while these approaches can capture non-linear motions they suffer from ghosting and perform poorly in low-texture regions with few events. Thus, synthesis-based and flow-based approaches are complementary. In this work, we introduce Time Lens, a novel method that leverages the advantages of both. We extensively evaluate our method on three synthetic and two real benchmarks where we show an up to 5.21 dB improvement in terms of PSNR over state-of-the-art frame-based and event-based methods. Finally, we release a new large-scale dataset in highly dynamic scenarios, aimed at pushing the limits of existing methods.
https://weibo.com/1402400261/KmmCEj9Km 



5、[LG] Model-Based Reinforcement Learning via Latent-Space Collocation
O Rybkin, C Zhu, A Nagabandi, K Daniilidis, I Mordatch, S Levine
[University of Pennsylvania & Covariant & Google AI & UC Berkeley]
基于潜空间组配的基于模型强化学习。在只利用原始高维观察(如图像)的情况下,对未来进行规划的能力,可以为自主智能体提供广泛能力。直接规划未来行动的基于视觉模型的强化学习方法在只需要短跨度推理的任务上显示出令人印象深刻的结果,然而,这些方法在时间扩展任务上却很困难。通过规划状态序列而不仅仅是行动,更容易解决长时间任务,因为行动的影响随着时间的推移而大大增加,更难优化。为实现这一点,借鉴了在最优控制文献中对长视距任务显示出良好效果的组配思想,并通过利用学习到的潜状态空间模型将其适应于基于图像的设置。由此产生的潜组配方法(LatCo)优化了潜状态轨迹,比以前提出的基于视觉模型的强化学习在具有稀疏奖励和长期目标的任务上的方法有所改进。
The ability to plan into the future while utilizing only raw high-dimensional observations, such as images, can provide autonomous agents with broad capabilities. Visual model-based reinforcement learning (RL) methods that plan future actions directly have shown impressive results on tasks that require only short-horizon reasoning, however, these methods struggle on temporally extended tasks. We argue that it is easier to solve long-horizon tasks by planning sequences of states rather than just actions, as the effects of actions greatly compound over time and are harder to optimize. To achieve this, we draw on the idea of collocation, which has shown good results on long-horizon tasks in optimal control literature, and adapt it to the image-based setting by utilizing learned latent state space models. The resulting latent collocation method (LatCo) optimizes trajectories of latent states, which improves over previously proposed shooting methods for visual model-based RL on tasks with sparse rewards and long-term goals.
https://weibo.com/1402400261/KmmGzhgBJ 




另外几篇值得关注的论文:
[CV] To the Point: Efficient 3D Object Detection in the Range Image with Graph Convolution Kernels
To the Point::基于图卷积核的深度图高效3D目标检测
Y Chai, P Sun, J Ngiam, W Wang, B Caine, V Vasudevan, X Zhang, D Anguelov
[Waymo LLC & Google Brain]
https://weibo.com/1402400261/KmmJIjQ8M 




[RO] Multi-Robot Deep Reinforcement Learning for Mobile Navigation
面向移动导航的多机器人深度强化学习
K Kang, G Kahn, S Levine
[UC Berkeley]
https://weibo.com/1402400261/KmmMq6YPJ 




[CV] Shape As Points: A Differentiable Poisson Solver
SAP:可微泊松解算器
S Peng, C M Jiang, Y Liao, M Niemeyer, M Pollefeys, A Geiger
[ETH Zurich & Max Planck Institute for Intelligent Systems,]
https://weibo.com/1402400261/KmmOHAZ9Y 




[AS] Scaling Laws for Acoustic Models
声学模型的缩放律
J Droppo, O Elibol
[Amazon Alexa]
https://weibo.com/1402400261/KmmQ76ggf 




若有收获,就点个赞吧
0 人点赞
