- 1、[CV] Towards Real-time and Light-weight Line Segment Detection
- 2、[CV] You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection
- 3、[CV] Language-Driven Image Style Transfer
- 4、[CV] Bootstrap Your Own Correspondences
- 5、[CV] KVT: k-NN Attention for Boosting Vision Transformers
- [AS] Omnizart: A General Toolbox for Automatic Music Transcription
- [LG] Reward is enough for convex MDPs
- [LG] What Matters for Adversarial Imitation Learning?
- [LG] Gaussian Processes with Differential Privacy
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CV] Towards Real-time and Light-weight Line Segment Detection
G Gu, B Ko, S Go, S Lee, J Lee, M Shin
[NAVER/LINE Vision]
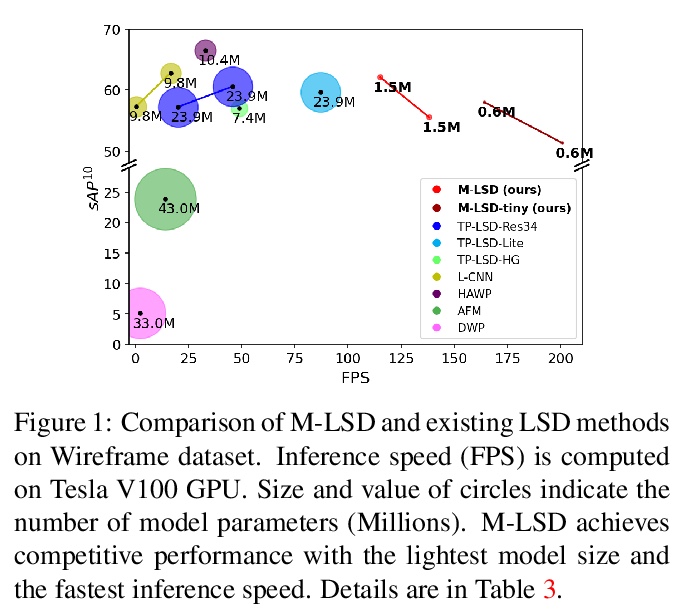
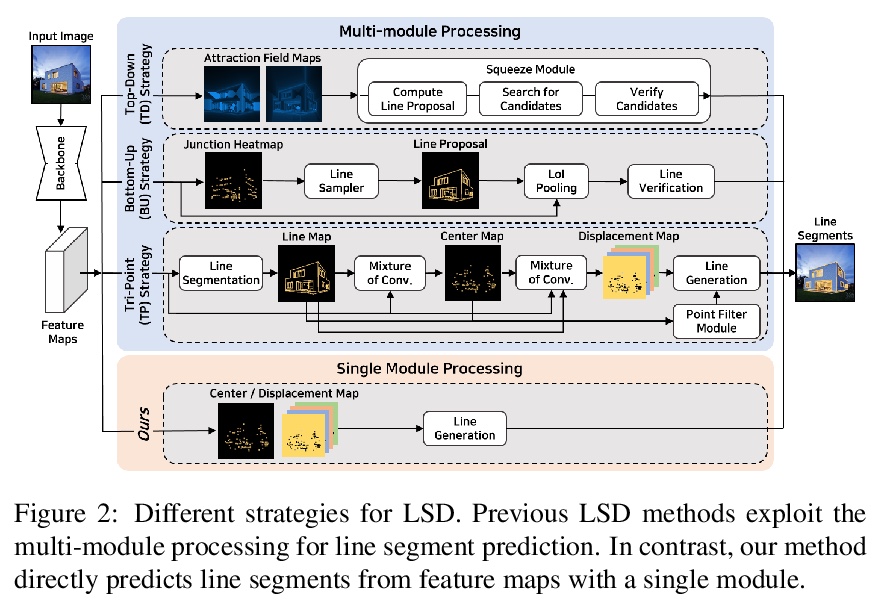
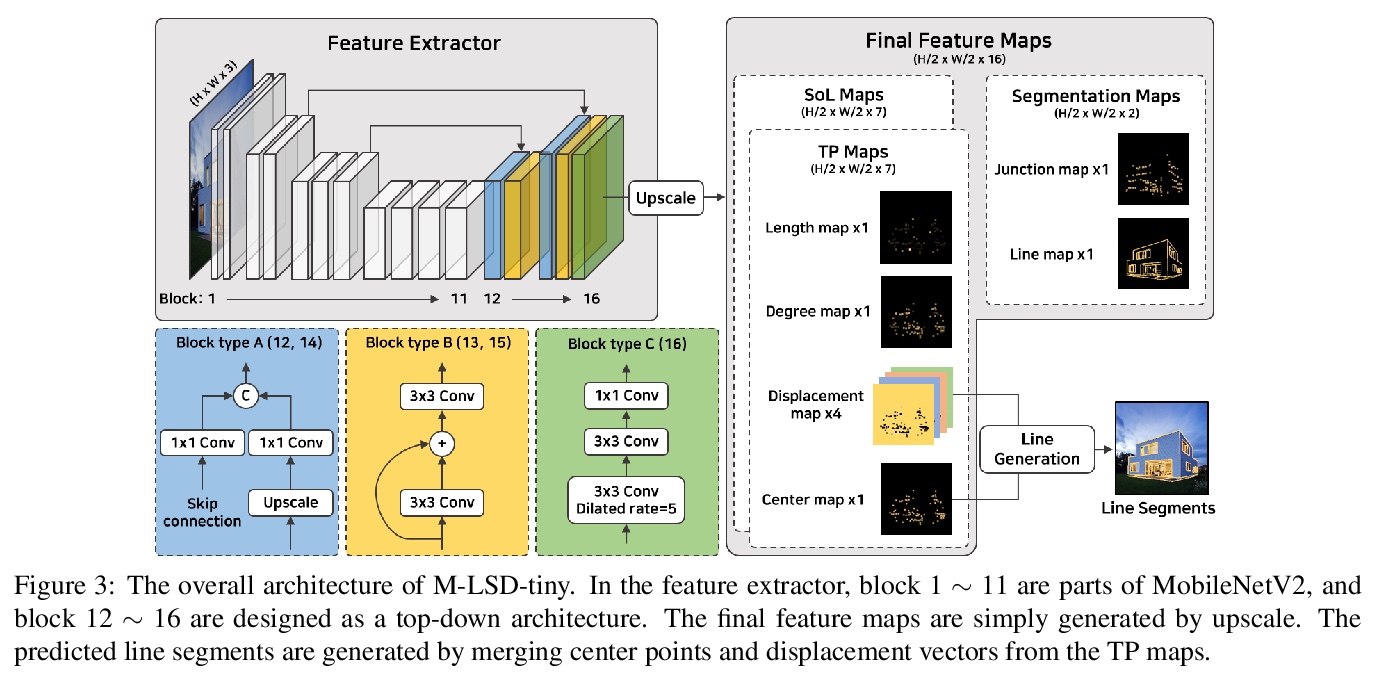
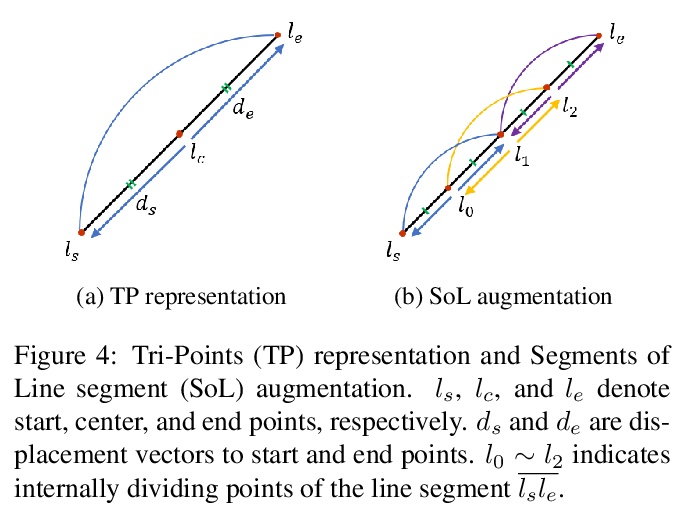
轻量实时深度直线段检测。基于深度学习的直线段检测(LSD),存在模型巨大、计算成本高的问题,限制了其在计算受限环境中的实时推理。本文提出一种面向资源受限环境的实时、轻量的直线段检测器移动LSD(M-LSD)。设计了一种极其有效的LSD架构,通过最小化骨干网络,去除之前方法中典型的多模块直线段预测过程。为保持这一轻量网络的竞争性能,提出了新的训练方案。直线段分段(SoL)增强和几何学习方案。SoL增强将一条线段分成多个子段,在训练过程中提供辅助线数据。几何学习方案允许模型从匹配损失、结点和线段划分、长度和角度回归中获取额外的几何线索。与之前最好的实时LSD方法TP-LSD-Lite相比,所提出模型(M-LSDtiny)实现了具有竞争力的性能,在使用Wireframe和YorkUrban数据集进行评估时,模型了缩小2.5%,在GPU上的推理速度增加了130.5%。模型在Android和iPhone移动设备上的运行速度分别为56.8 FPS和48.6 FPS,是第一个可用于移动设备的实时深度LSD方法。
Previous deep learning-based line segment detection (LSD) suffer from the immense model size and high computational cost for line prediction. This constrains them from real-time inference on computationally restricted environments. In this paper, we propose a real-time and lightweight line segment detector for resource-constrained environments named Mobile LSD (M-LSD). We design an extremely efficient LSD architecture by minimizing the backbone network and removing the typical multi-module process for line prediction in previous methods. To maintain competitive performance with such a light-weight network, we present novel training schemes: Segments of Line segment (SoL) augmentation and geometric learning scheme. SoL augmentation splits a line segment into multiple subparts, which are used to provide auxiliary line data during the training process. Moreover, the geometric learning scheme allows a model to capture additional geometric cues from matching loss, junction and line segmentation, length and degree regression. Compared with TP-LSD-Lite, previously the best real-time LSD method, our model (M-LSDtiny) achieves competitive performance with 2.5% of model size and an increase of 130.5% in inference speed on GPU when evaluated with Wireframe and YorkUrban datasets. Furthermore, our model runs at 56.8 FPS and 48.6 FPS on Android and iPhone mobile devices, respectively. To the best of our knowledge, this is the first real-time deep LSD method available on mobile devices.
https://weibo.com/1402400261/KipfC7USU


2、[CV] You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection
Y Fang, B Liao, X Wang, J Fang, J Qi, R Wu, J Niu, W Liu
[Huazhong University of Science & Technology & Horizon Robotics]
通过目标检测重新思考视觉Transformer。Transformer能否从纯粹序列到序列的角度,在对2D空间结构了解最少的情况下进行2D物体级识别?为回答这个问题,本文提出了You Only Look at One Sequence (YOLOS),一系列基于简单视觉Transformer的目标检测模型,只有尽可能少的修改和归纳偏见。仅在中等规模的ImageNet-1k数据集上预训练的YOLOS,已经可以在COCO上实现有竞争力的目标检测性能,直接采用BERT-Base的YOLOS-Base可实现42.0的框AP。通过目标检测讨论了当前预训练方案和模型缩放策略对视觉Transformer的影响以及限制。
Can Transformer perform 2D object-level recognition from a pure sequence-to-sequence perspective with minimal knowledge about the 2D spatial structure? To answer this question, we present You Only Look at One Sequence (YOLOS), a series of object detection models based on the naïve Vision Transformer with the fewest possible modifications as well as inductive biases. We find that YOLOS pre-trained on the mid-sized ImageNet-1k dataset only can already achieve competitive object detection performance on COCO, e.g., YOLOS-Base directly adopted from BERT-Base can achieve 42.0 box AP. We also discuss the impacts as well as limitations of current pre-train schemes and model scaling strategies for Transformer in vision through object detection.
https://weibo.com/1402400261/KipkzEMDC
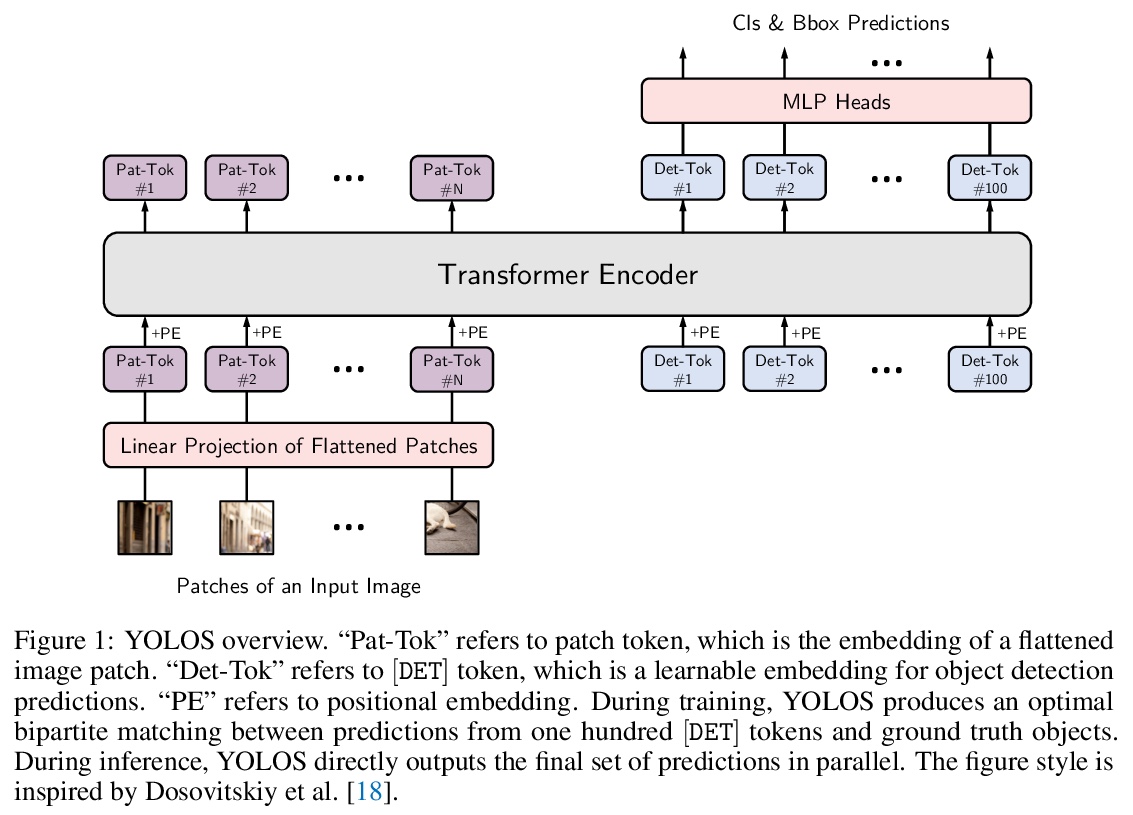

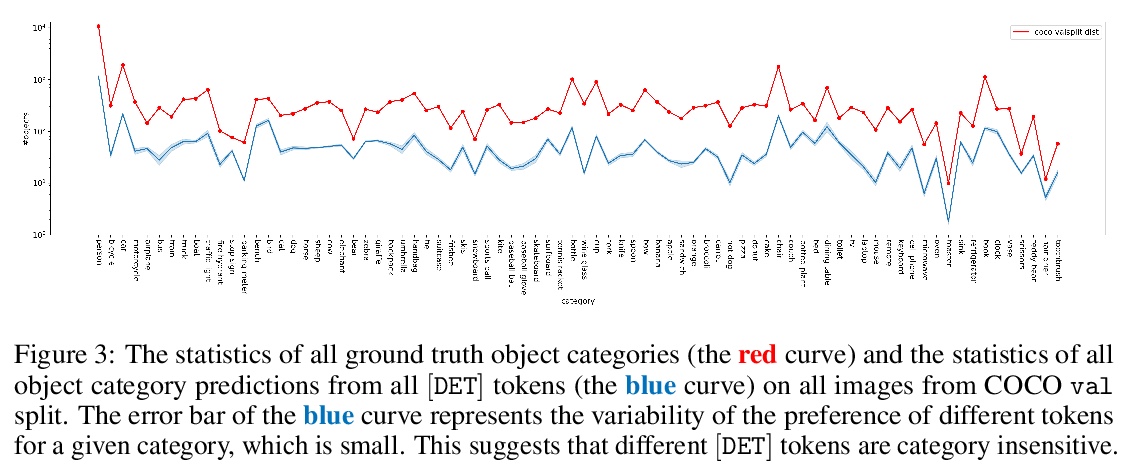
3、[CV] Language-Driven Image Style Transfer
T Fu, X E Wang, W Y Wang
[UC Santa Barbara & UC Santa Cruz]
语言驱动的图像画风迁移。尽管有很好的效果,但需要提前准备风格图像的画风迁移,可能会缺乏创造性和可用性。另一方面,遵循人工指示是进行艺术画风迁移的最自然的方式,可大大改善视觉效果应用的可控性。本文提出一个新任务——语言驱动的图像画风迁移(LDIST)——在文本指导下操纵内容图像风格。提出了对比语言视觉艺术家(CLVA),可学习从画风指令中提取视觉语义,通过图块式画风判别器完成LDIST。判别器考虑了语言和风格图像或迁移结果图块间相关性来联合嵌入风格指示。CLVA进一步比较内容图像和风格指令的对比对,以提高迁移结果之间的互关系。来自同一内容图像的迁移结果可保持一致的内容结构,从包含类似视觉语义的风格指令中呈现出类似的风格模式。实验表明,所提出的CLVA是有效的,在LDIST上取得了很好的迁移结果。
Despite having promising results, style transfer, which requires preparing style images in advance, may result in lack of creativity and accessibility. Following human instruction, on the other hand, is the most natural way to perform artistic style transfer that can significantly improve controllability for visual effect applications. We introduce a new task—language-driven image style transfer (LDIST)—to manipulate the style of a content image, guided by a text. We propose contrastive language visual artist (CLVA) that learns to extract visual semantics from style instructions and accomplish LDIST by the patch-wise style discriminator. The discriminator considers the correlation between language and patches of style images or transferred results to jointly embed style instructions. CLVA further compares contrastive pairs of content image and style instruction to improve the mutual relativeness between transfer results. The transferred results from the same content image can preserve consistent content structures. Besides, they should present analogous style patterns from style instructions that contain similar visual semantics. The experiments show that our CLVA is effective and achieves superb transferred results on LDIST.
https://weibo.com/1402400261/KipovbeHN

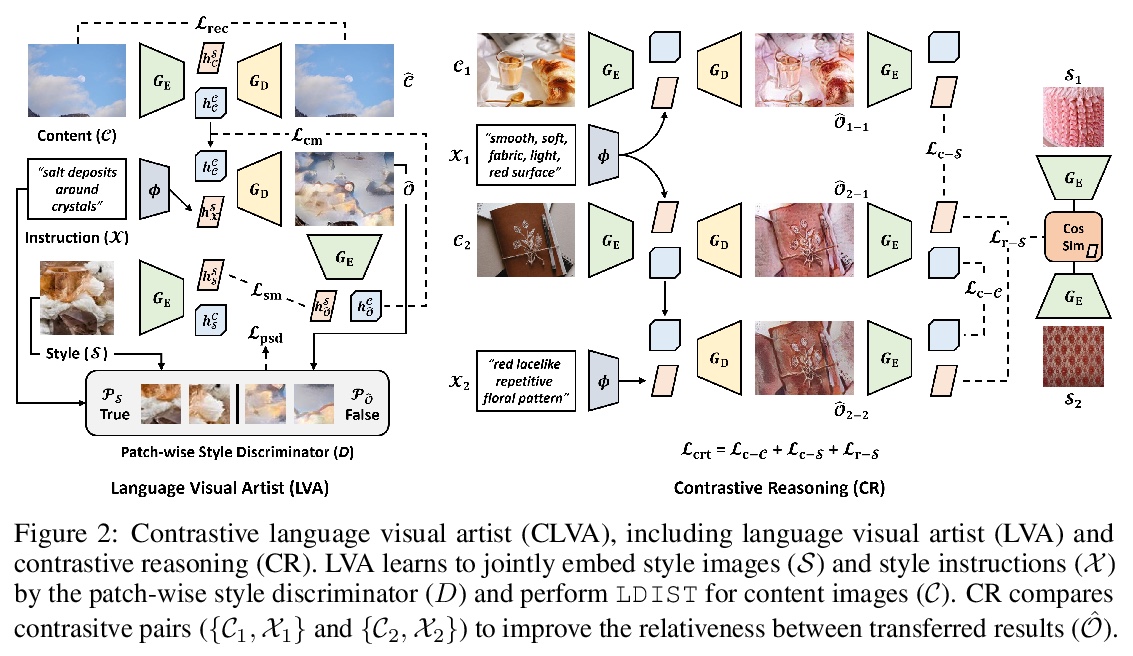

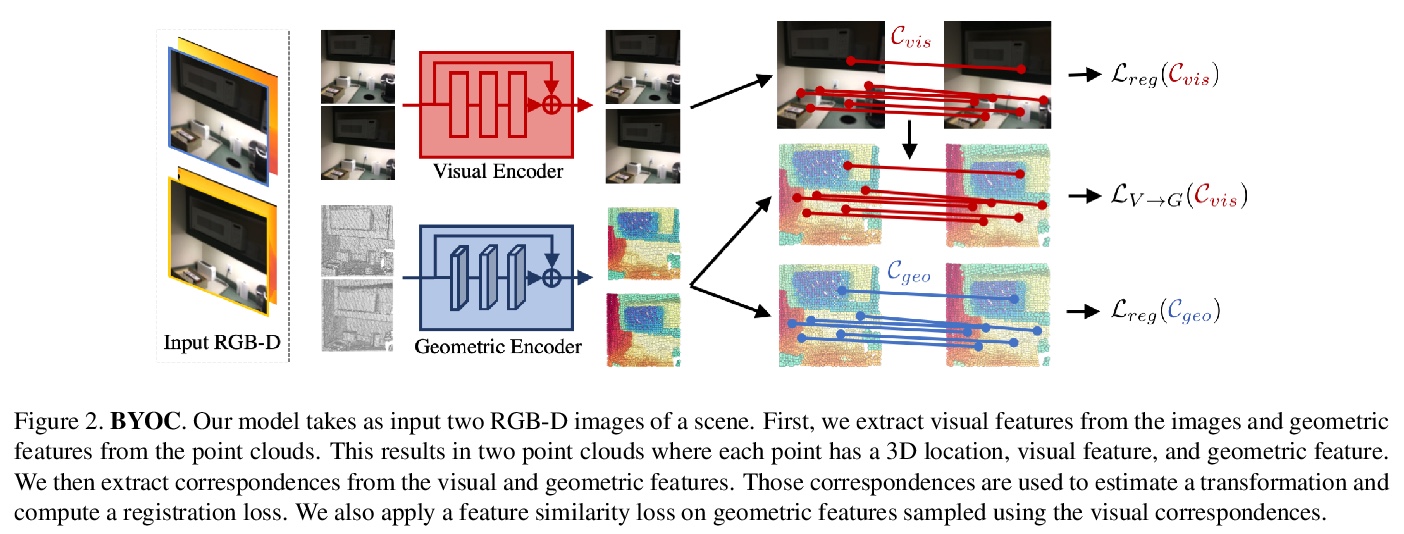
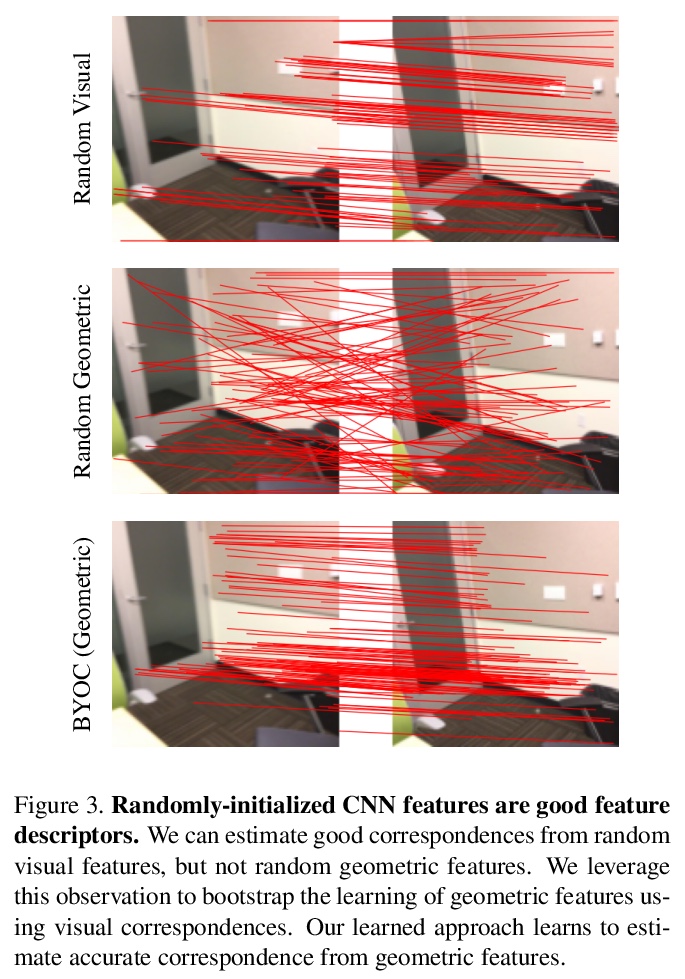
4、[CV] Bootstrap Your Own Correspondences
M E Banani, J Johnson
[University of Michigan]
点云配准中的BYOC自监督几何特征抽取。几何特征提取是点云配准管线的一个重要组成部分。最近的工作已经证明了如何利用监督学习来学习更好、更紧凑的3D特征。然而,这些方法对真值标注的依赖限制了其可扩展性。本文提出BYOC,一种自监督方法,从RGB-D视频中学习视觉和几何特征,不依赖姿态或对应关系的真值标注。随机初始化的CNN很容易提供良好的对应关系;可引导学习视觉和几何特征。所提出的方法结合了点云配准的经典思想和最新的表示学习方法。在室内场景数据集上评估了该方法,其效果优于传统的和基于学习的描述子,同时与目前最先进的监督方法相比具有竞争力。
Geometric feature extraction is a crucial component of point cloud registration pipelines. Recent work has demonstrated how supervised learning can be leveraged to learn better and more compact 3D features. However, those approaches’ reliance on ground-truth annotation limits their scalability. We propose BYOC: a self-supervised approach that learns visual and geometric features from RGB-D video without relying on ground-truth pose or correspondence. Our key observation is that randomly-initialized CNNs readily provide us with good correspondences; allowing us to bootstrap the learning of both visual and geometric features. Our approach combines classic ideas from point cloud registration with more recent representation learning approaches. We evaluate our approach on indoor scene datasets and find that our method outperforms traditional and learned descriptors, while being competitive with current state-of-the-art supervised approaches.
https://weibo.com/1402400261/Kipuszbbt
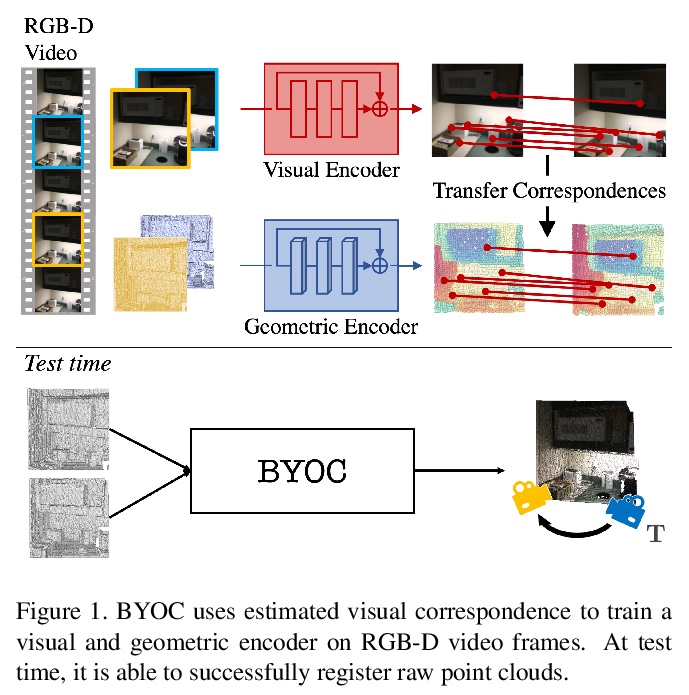

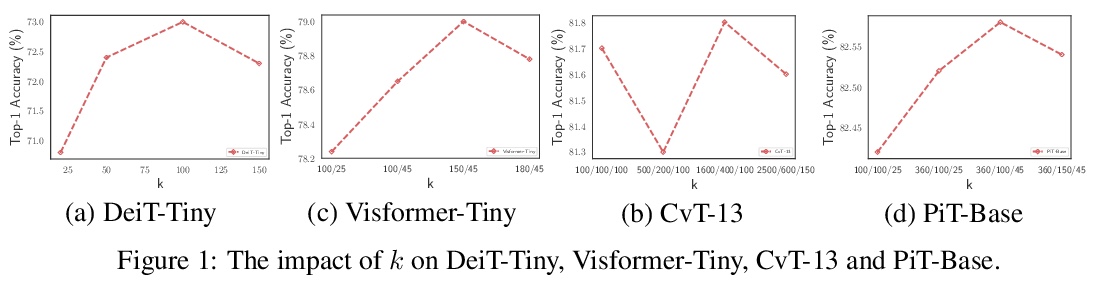
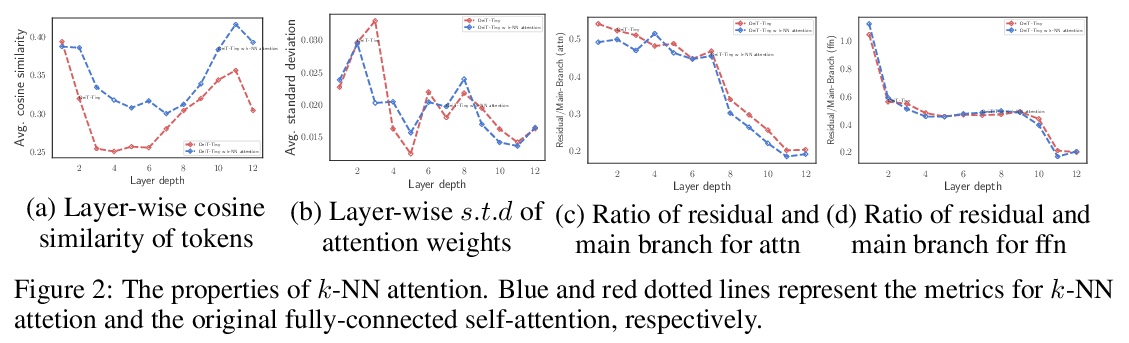
5、[CV] KVT: k-NN Attention for Boosting Vision Transformers
P Wang, X Wang, F Wang, M Lin, S Chang, W Xie, H Li, R Jin
[Alibaba Group]
KVT:用k-NN注意力提升视觉Transformer。卷积神经网络(CNN)多年来一直主导着计算机视觉,因为它能捕捉到局部性和变换不变性。最近,提出了许多视觉Transformer架构,显示出良好的性能。视觉Transformer的一个关键组成部分是全连接的自注意力,在模拟长程依赖性方面比CNN更强大。密集的自注意力用所有图块(token)计算注意力矩阵,可能忽略图块局部性,以及含噪token(例如杂乱的背景和遮挡),导致缓慢的训练过程和潜在的性能下降。为解决这些问题,本文提出一种稀疏注意力方案,k-NN注意力,用于提升视觉Transformer。k-NN注意力不用所有token来计算注意力矩阵,只从每次查询选择前k个最相似的token来计算注意力图。所提出的k-NN注意力自然继承了CNN的局部偏差,而没有引入卷积操作,近邻token往往比其他token更相似。此外,k-NN注意力允许探索长程的相关性,通过从整个图像中选择最相似的token过滤掉不相关的token。从理论上和经验上验证了k-NN注意力在从输入token中提取噪声和加快训练方面的强大作用。通过使用十个不同的视觉Transformer架构进行了广泛实验,以验证所提出的k-NN注意力可以与任何现有的Transformer架构一起工作,以提高其预测性能。
Convolutional Neural Networks (CNNs) have dominated computer vision for years, due to its ability in capturing locality and translation invariance. Recently, many vision transformer architectures have been proposed and they show promising performance. A key component in vision transformers is the fully-connected selfattention which is more powerful than CNNs in modelling long range dependencies. However, since the current dense self-attention uses all image patches (tokens) to compute attention matrix, it may neglect locality of images patches and involve noisy tokens (e.g., clutter background and occlusion), leading to a slow training process and potential degradation of performance. To address these problems, we propose a sparse attention scheme, dubbed k-NN attention, for boosting vision transformers. Specifically, instead of involving all the tokens for attention matrix calculation, we only select the top-k similar tokens from the keys for each query to compute the attention map. The proposed k-NN attention naturally inherits the local bias of CNNs without introducing convolutional operations, as nearby tokens tend to be more similar than others. In addition, the k-NN attention allows for the exploration of long range correlation and at the same time filters out irrelevant tokens by choosing the most similar tokens from the entire image. Despite its simplicity, we verify, both theoretically and empirically, that k-NN attention is powerful in distilling noise from input tokens and in speeding up training. Extensive experiments are conducted by using ten different vision transformer architectures to verify that the proposed k-NN attention can work with any existing transformer architectures to improve its prediction performance.
https://weibo.com/1402400261/Kipy6Dlk6


另外几篇值得关注的论文:
[AS] Omnizart: A General Toolbox for Automatic Music Transcription
Omnizart:通用音乐自动转录工具箱
Y Wu, Y Luo, T Chen, I Wei, J Hsu, Y Chuang, L Su
[Academia Sinica]
https://weibo.com/1402400261/KipsCvBTT
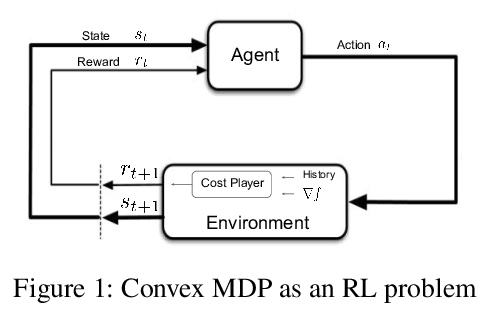
[LG] Reward is enough for convex MDPs
内在奖励可作为凸马尔科夫决策过程目标梯度
T Zahavy, B O’Donoghue, G Desjardins, S Singh
[DeepMind]
https://weibo.com/1402400261/KipCGBqGH
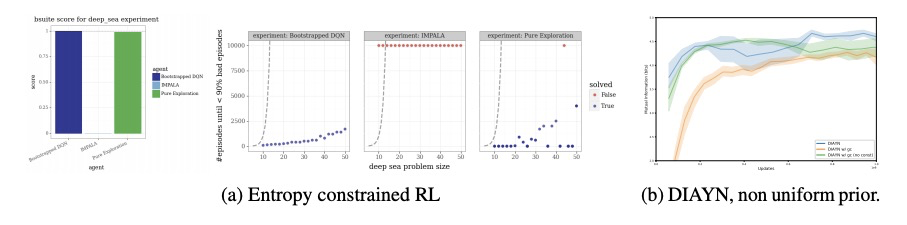
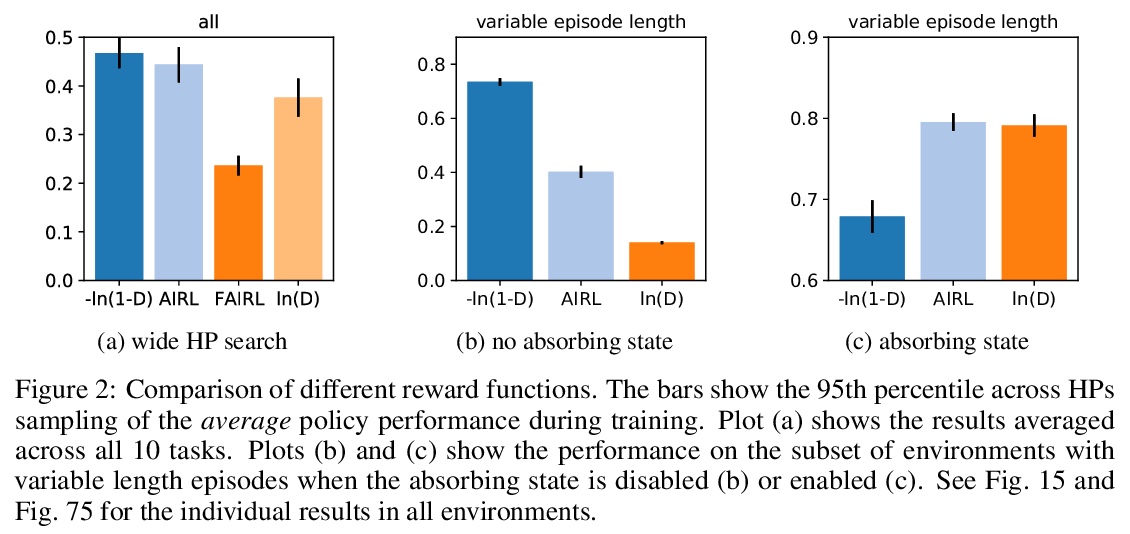
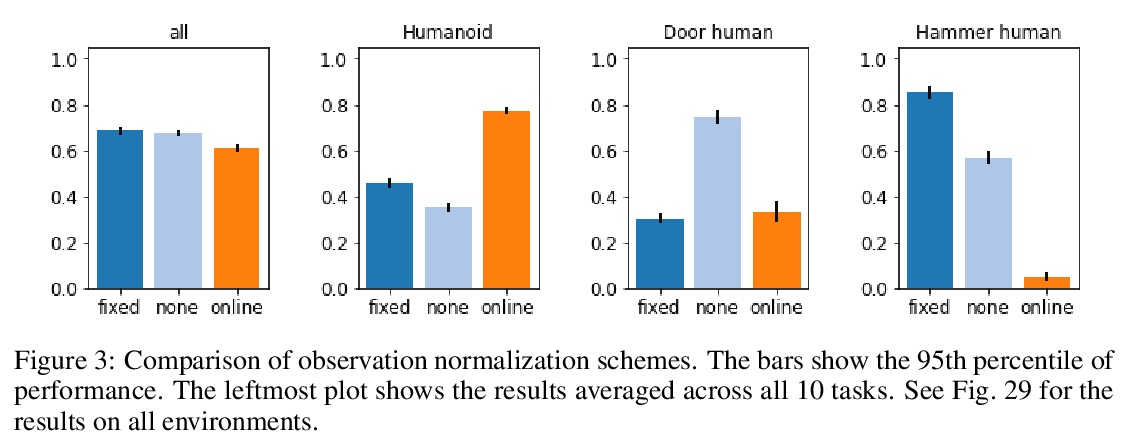
[LG] What Matters for Adversarial Imitation Learning?
对抗模仿学习的关键是什么?
M Orsini, A Raichuk, L Hussenot, D Vincent, R Dadashi, S Girgin, M Geist, O Bachem, O Pietquin, M Andrychowicz
[Google Research]
https://weibo.com/1402400261/KipGz548x

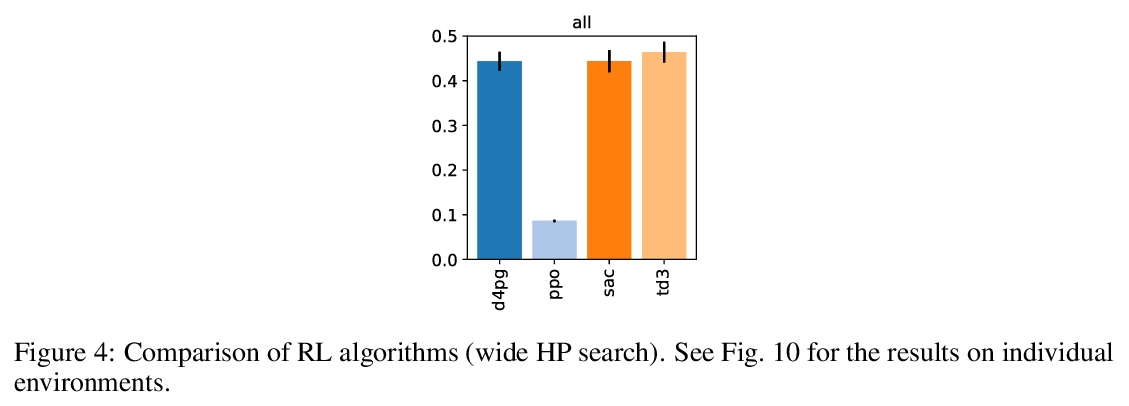
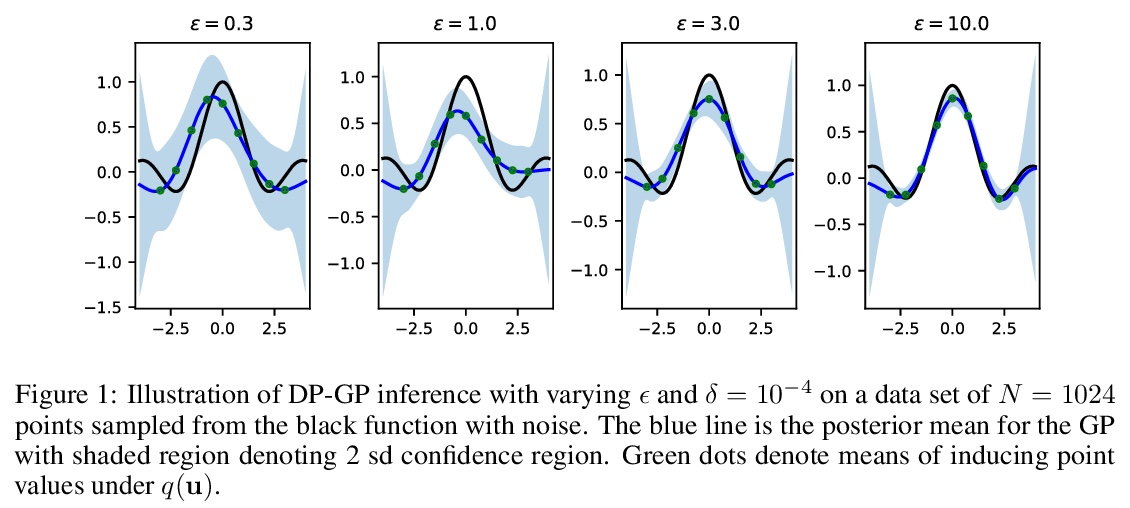
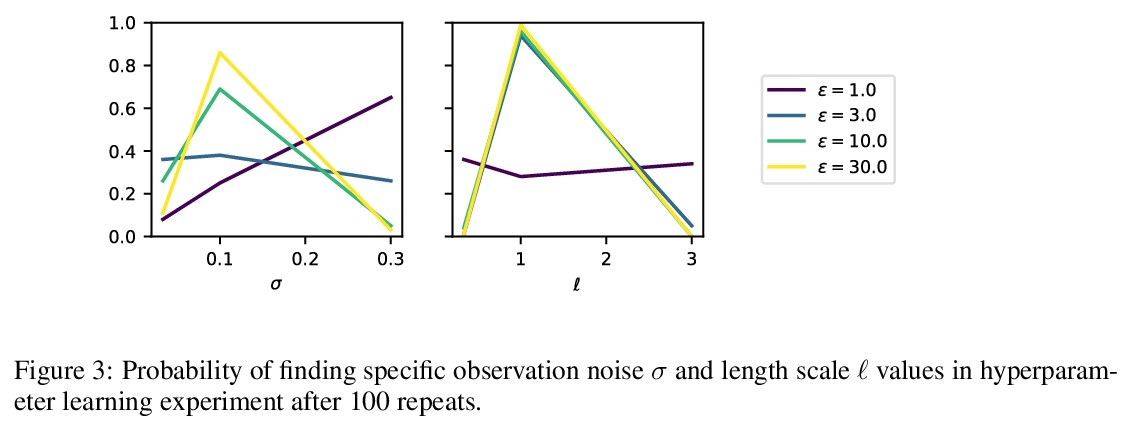
[LG] Gaussian Processes with Differential Privacy
差分隐私高斯过程
A Honkela
[University of Helsinki]
https://weibo.com/1402400261/KipMfmXEX


若有收获,就点个赞吧
0 人点赞
