- 1、[CV] Embedding-based Instance Segmentation of Microscopy Images
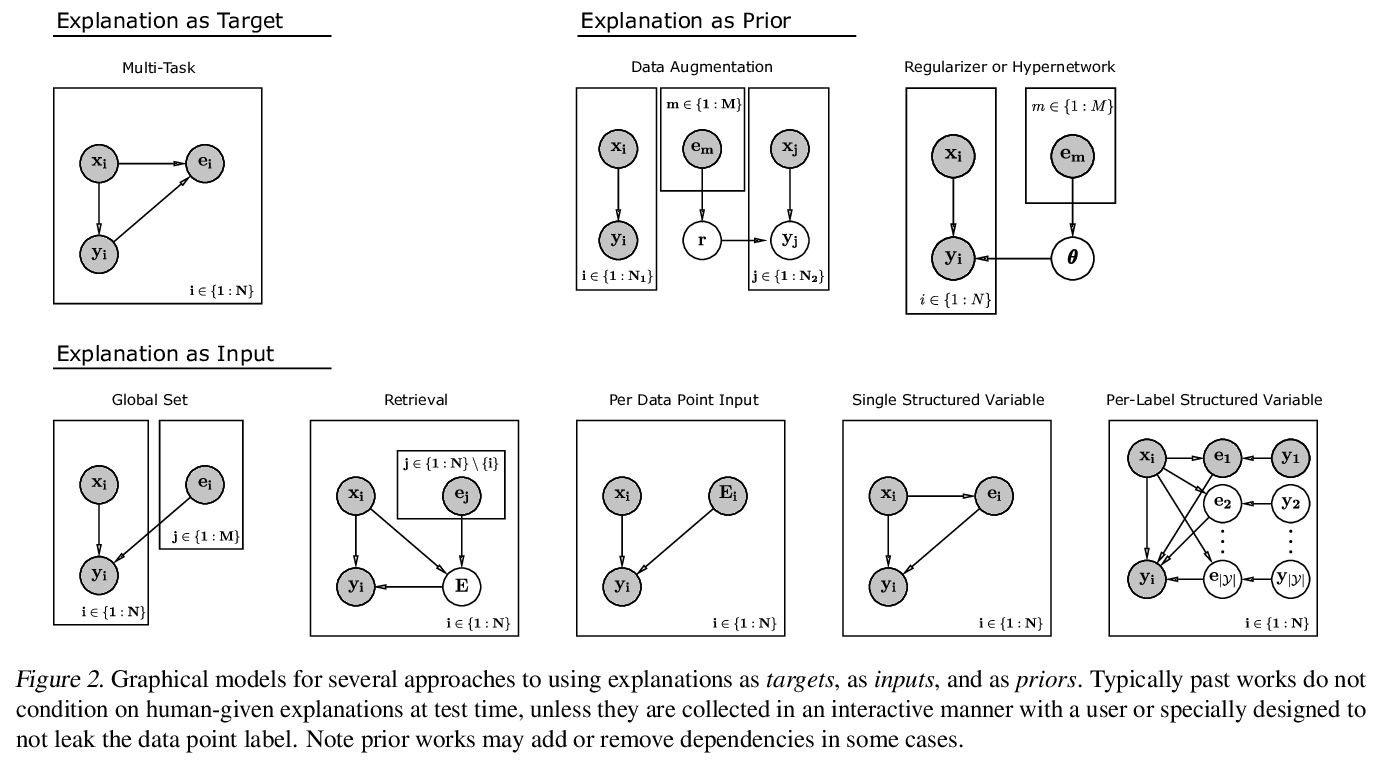
- 2、[CL] When Can Models Learn From Explanations? A Formal Framework for Understanding the Roles of Explanation Data
- 3、[LG] A Survey on Understanding, Visualizations, and Explanation of Deep Neural Networks
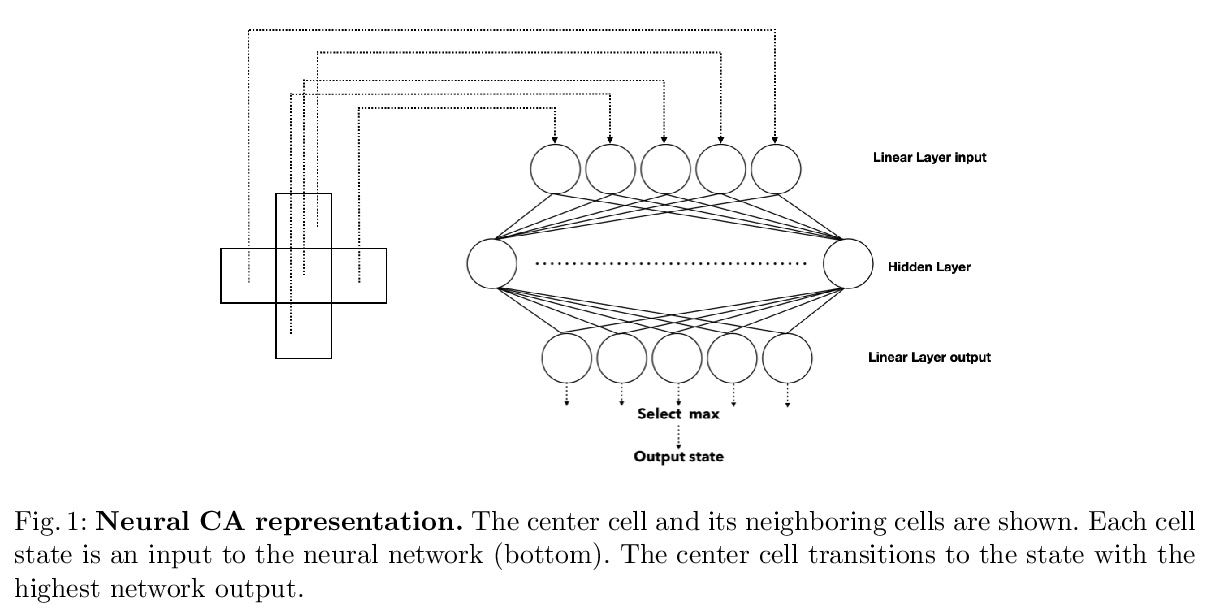
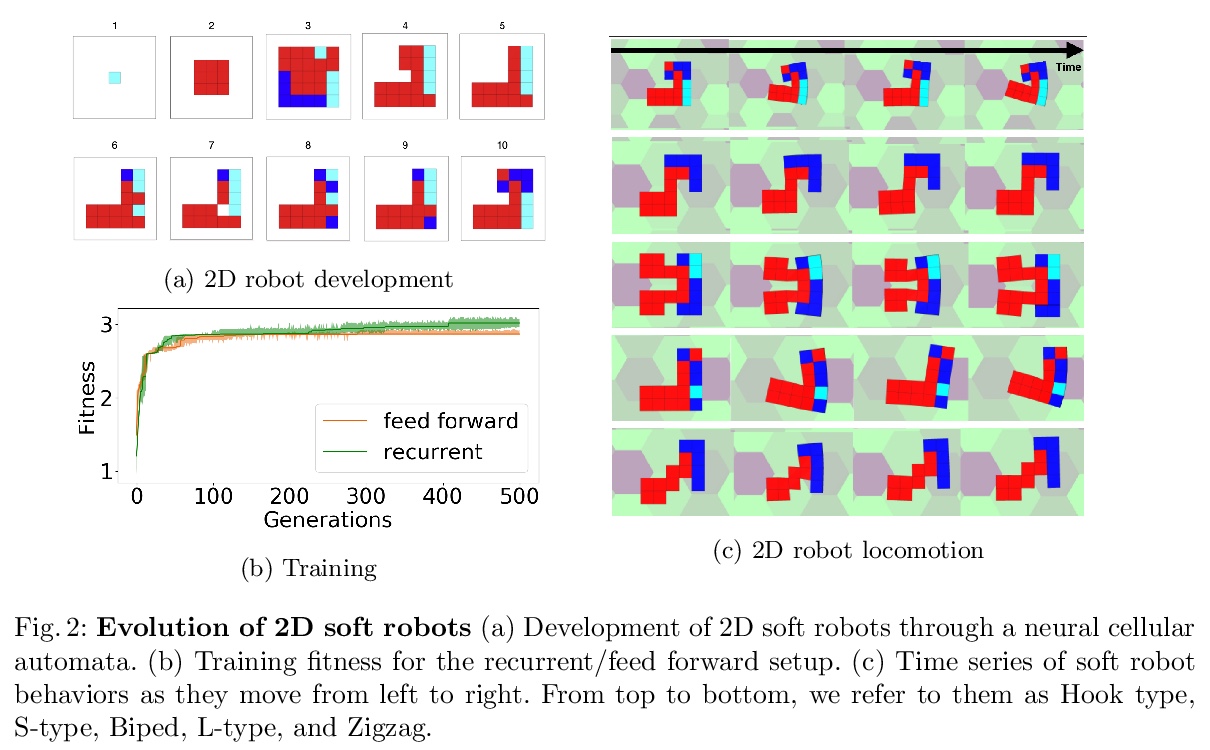
- 4、[RO] Regenerating Soft Robots through Neural Cellular Automata
- 5、[LG] Safe Multi-Agent Reinforcement Learning via Shielding
- [CL] Disambiguatory Signals are Stronger in Word-initial Positions
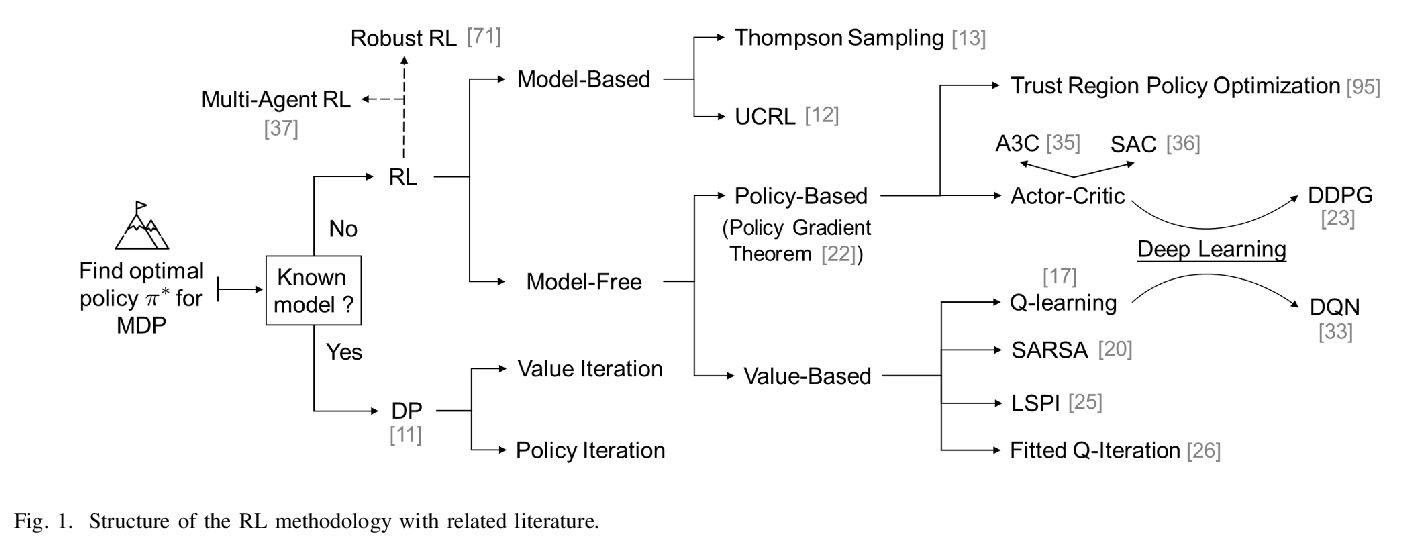
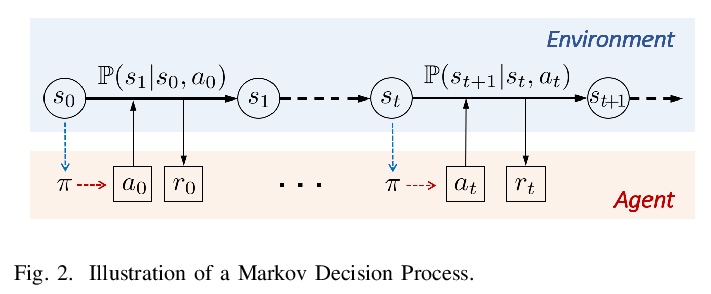
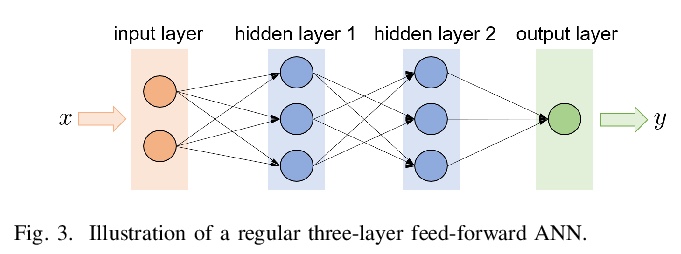
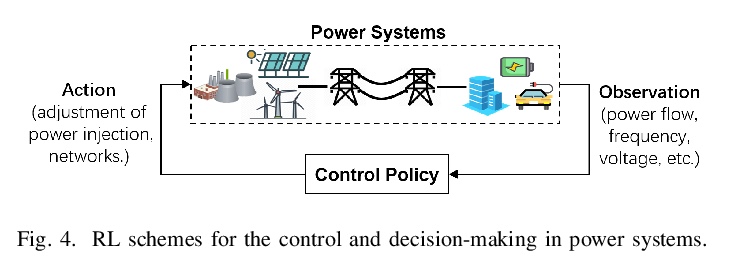
- [LG] Reinforcement Learning for Decision-Making and Control in Power Systems: Tutorial, Review, and Vision
- [CV] Learning domain-agnostic visual representation for computational pathology using medically-irrelevant style transfer augmentation
- [LG] Winning Lottery Tickets in Deep Generative Models
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Embedding-based Instance Segmentation of Microscopy Images
M Lalit, P Tomancak, F Jug
[Center for Systems Biology Dresden (CSBD) & Max Planck Institute of Molecular Cell Biology and Genetics]
基于嵌入的显微图像实例分割。提出了端到端可训练深度学习方法EMBEDSEG,针对生物目标的复杂形状,将每个像素嵌入到给定实例的Medoid,采用测试时增强方案,显著提高了生物显微镜数据集的实例分割性能。证明了基于嵌入的实例分割在不同的生物相关显微镜数据集上,实现了与最先进方法相比有竞争力的结果。整个流水线具有足够小的内存占用,可以在几乎所有支持CUDA的笔记本电脑硬件上使用。
https://weibo.com/1402400261/K0Vqrcurt


2、[CL] When Can Models Learn From Explanations? A Formal Framework for Understanding the Roles of Explanation Data
P Hase, M Bansal
[University of North Carolina at Chapel Hill]
模型何时能从解释中学习?理解解释数据作用的形式化框架。研究了在什么情况下,对单个数据点的解释可以(或不可以)提高模型性能。提出了理解解释在建模中作用的形式化框架,解释最适合用于基于检索的建模方法中,过去的解释被检索出来,并作为预测未来数据点的模型输入,也可以作为标签,或者作为先验。在论证了解释数据最有前途的作用是作为模型输入之后,提出使用一种基于检索的方法,并表明它解决合成任务的准确率高达95%以上,而没有解释数据的基线的准确率低于65%。通过实验研究了解释在建模中有用的前提条件,根据合成任务的结果,提出模型必须能在给定解释和输入的情况下,相对于单独使用输入,更好地推断出相关的潜信息。为了使解释检索可学习,发现(1)解释应该通过一个易于计算的特征与查询数据点联系起来,(2)解释应该在不同数据点之间具有相关性,(3)分类器对解释的解读应该是已知的或可识别的,(4)分类器和检索模型必须在另一个被训练之前都具有某种足够的质量。在三个现有的数据集(e-SNLI、TACRED和SemEval)上测试该方法时,发现解释并不能提高任务性能,这说明这些设置不符合上述标准之一。
https://weibo.com/1402400261/K0Vwvl02Q



3、[LG] A Survey on Understanding, Visualizations, and Explanation of Deep Neural Networks
A Shahroudnejad
[Concordia University]
深度神经网络理解、可视化和解释综述。说明了解释、可视化和理解深度神经网络(DNN)的必要性,特别是在复杂的机器学习和关键计算机视觉任务中。通过回顾三大类(结构化分析、行为分析和设计可解释性)最先进的解读和解释方案,推进了在该领域的知识。由于图像数据中存在一些视觉假象,可能会被错误地认为是一种解释或误导解释过程,使用理智检查测试来评价和验证所获得的解释非常重要;深度生成模型(DGM)作为最有前途的无监督和半监督学习方法,其说明和解读方法之前并没有完全研究过;由于其嵌入可解释性的优势,DNN结构仍有设计更多内在可解释策略的空间;解释可以发现导致模型做出错误预测的输入(对抗样本)背后的原因,可以用来提高DNN对各种对抗性攻击的抵抗力。
https://weibo.com/1402400261/K0VGtAAr7


4、[RO] Regenerating Soft Robots through Neural Cellular Automata
K Horibe, K Walker, S Risi
[IT University of Copenhagen]
基于神经元胞自动机的柔性机器人再生。开发了一种模拟柔性机器人在受到损伤时重新生长部分形态的方法。提出了一种通过神经元胞自动机进行再生的柔性机器人模型,只依靠局部元胞信息来重新生长受损部件,为未来物理可再生柔性机器人开辟了可能性。该方法可以让模拟受损的柔性机器人仅通过局部元胞相互作用就能部分再生其原有形态,恢复部分运动能力。这些结果向使人工系统具备再生能力迈出了一步,并有可能使人工系统在各种情况和环境下进行更鲁棒的操作。
https://weibo.com/1402400261/K0VPagywE

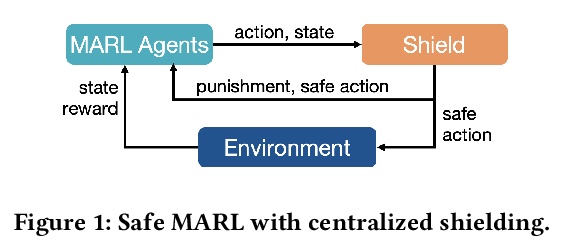
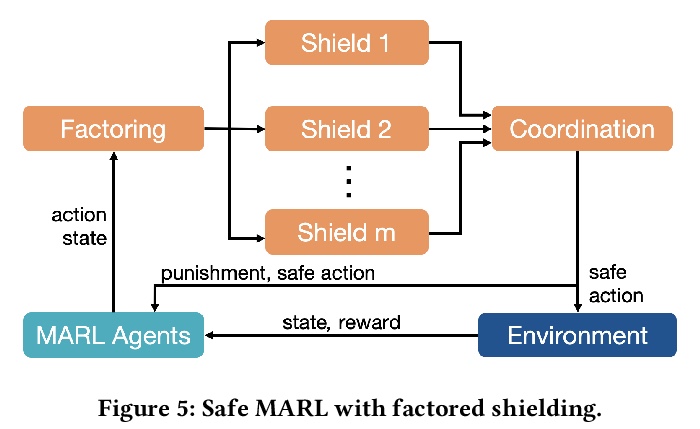
5、[LG] Safe Multi-Agent Reinforcement Learning via Shielding
I Elsayed-Aly, S Bharadwaj, C Amato, R Ehlers, U Topcu, L Feng
[University of Virginia & University of Texas at Austin & Northeastern University & Clausthal University of Technology]
基于屏蔽的安全多智能体强化学习。提出了两种屏蔽方法,以保证多智能体强化学习过程中用线性时序逻辑表达的安全规范。集中式屏蔽方法合成单个屏蔽,集中监控所有智能体的联合动作,只纠正任何违反线性时序逻辑安全规范的不安全动作。集中式屏蔽的可扩展性有限,因为屏蔽合成的计算成本随着智能体数量增加而成倍增长。因式屏蔽方法通过合成多个因式屏蔽,每个屏蔽在每个时间步中监控一个智能体子集来解决该限制。实验结果表明,两种屏蔽方法在学习过程中都能保证安全规范(如避免碰撞),并取得与非屏蔽多智能体强化学习相似的学习性能(如收敛速度、学习策略的质量)。
Multi-agent reinforcement learning (MARL) has been increasingly used in a wide range of safety-critical applications, which require guaranteed safety (e.g., no unsafe states are ever visited) during the learning process.Unfortunately, current MARL methods do not have safety guarantees. Therefore, we present two shielding approaches for safe MARL. In centralized shielding, we synthesize a single shield to monitor all agents’ joint actions and correct any unsafe action if necessary. In factored shielding, we synthesize multiple shields based on a factorization of the joint state space observed by all agents; the set of shields monitors agents concurrently and each shield is only responsible for a subset of agents at each step.Experimental results show that both approaches can guarantee the safety of agents during learning without compromising the quality of learned policies; moreover, factored shielding is more scalable in the number of agents than centralized shielding.
https://weibo.com/1402400261/K0VSLzvdr
另外几篇值得关注的论文:
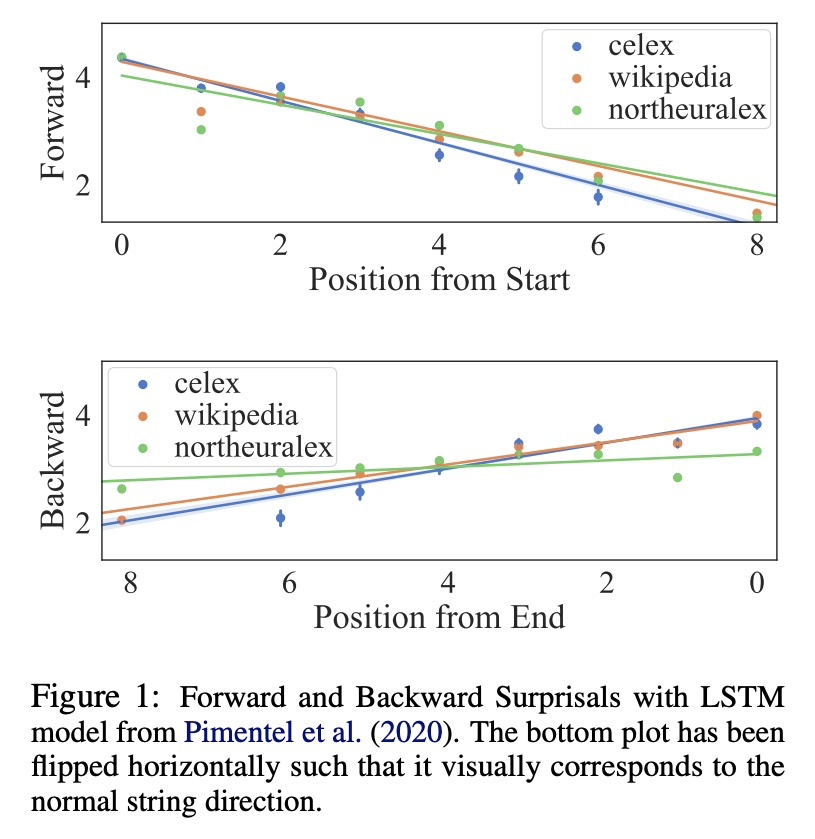
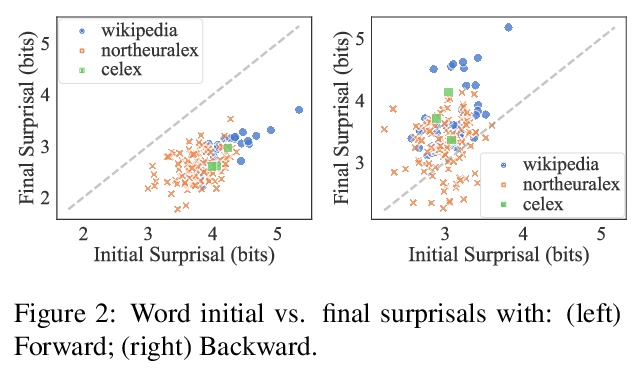
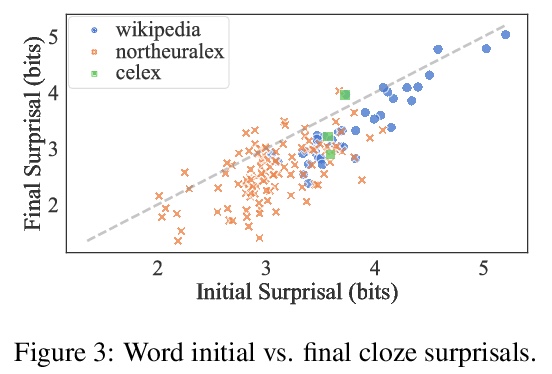
[CL] Disambiguatory Signals are Stronger in Word-initial Positions
词前段消歧信号更强(跨语言单词信息前置倾向)
T Pimentel, R Cotterell, B Roark
[University of Cambridge & Google]
https://weibo.com/1402400261/K0VW76hah
[LG] Reinforcement Learning for Decision-Making and Control in Power Systems: Tutorial, Review, and Vision
电力系统强化学习决策与控制:教程、回顾与展望
X Chen, G Qu, Y Tang, S Low, N Li
[Harvard University & California Institute of Technology]
https://weibo.com/1402400261/K0VYJjH2f
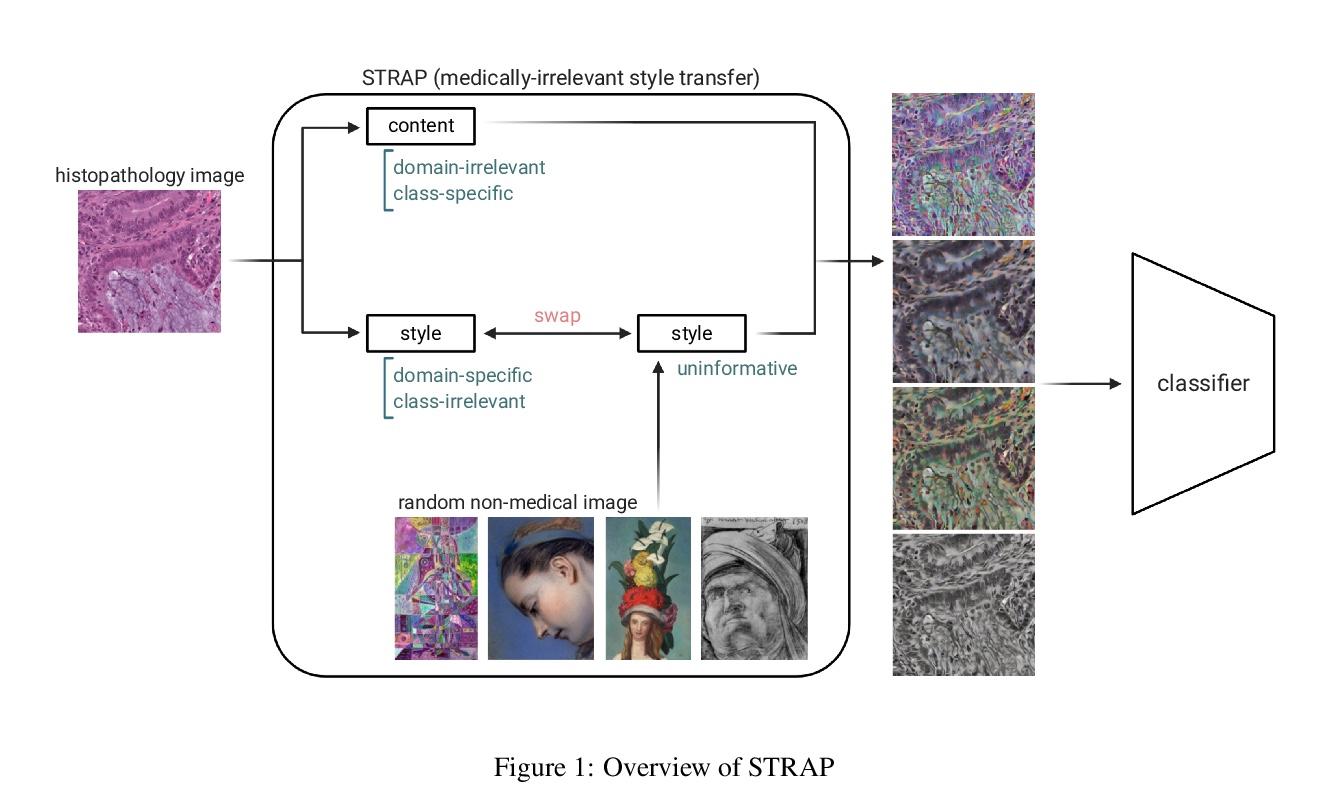
[CV] Learning domain-agnostic visual representation for computational pathology using medically-irrelevant style transfer augmentation
基于医学无关风格迁移增强的计算病理学领域不可知视觉表示学习
R Yamashita, J Long, S Banda, J Shen, D L. Rubin
[Stanford University]
https://weibo.com/1402400261/K0W1Z4DJS


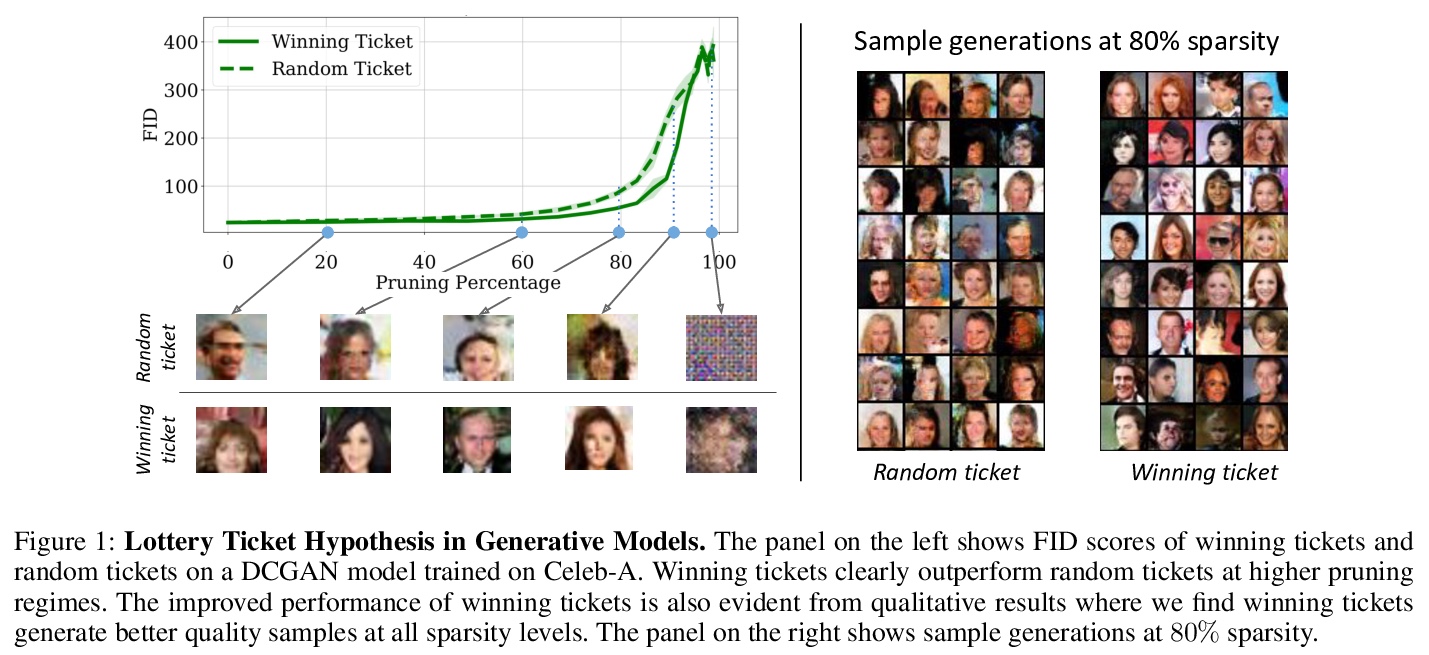
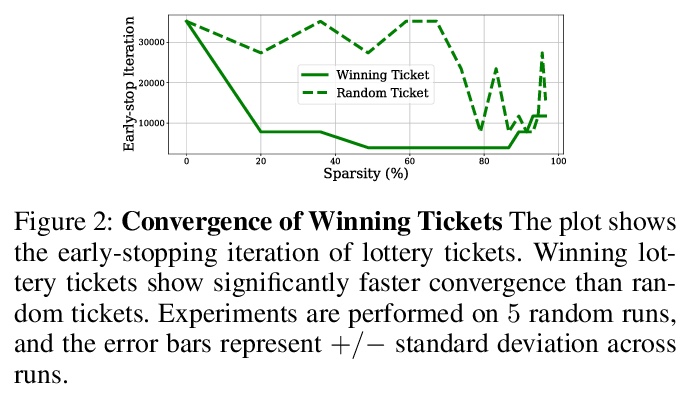
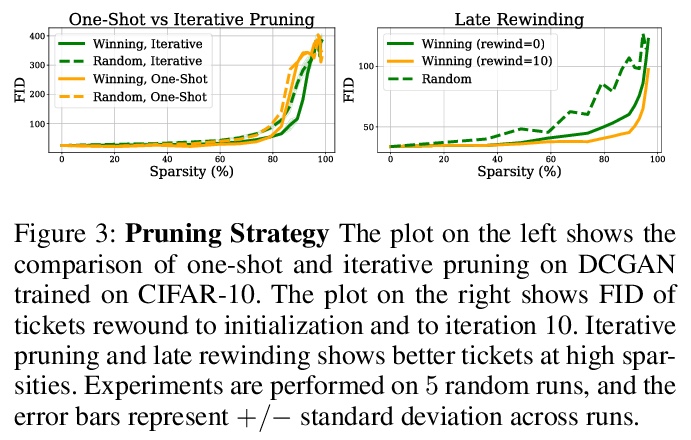
[LG] Winning Lottery Tickets in Deep Generative Models
深度生成模型中的中奖彩票
N M Kalibhat, Y Balaji, S Feizi
[University of Maryland]
https://weibo.com/1402400261/K0W52cznk

若有收获,就点个赞吧
0 人点赞
