- 1、[LG] An Attention Free Transformer
- 2、[CL] Comparing Test Sets with Item Response Theory
- 3、[CL] Attention Flows are Shapley Value Explanations
- 4、[CV] Single Image Depth Estimation using Wavelet Decomposition
- 5、[LG] A Differentiable Point Process with Its Application to Spiking Neural Networks
- [LG] How Attentive are Graph Attention Networks?
- [CV] Fourier Space Losses for Efficient Perceptual Image Super-Resolution
- [CL] Hi-Transformer: Hierarchical Interactive Transformer for Efficient and Effective Long Document Modeling
- [CL] multiPRover: Generating Multiple Proofs for Improved Interpretability in Rule Reasoning
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[LG] An Attention Free Transformer
S Zhai, W Talbott, N Srivastava, C Huang, H Goh, R Zhang, J Susskind
[Apple Inc]
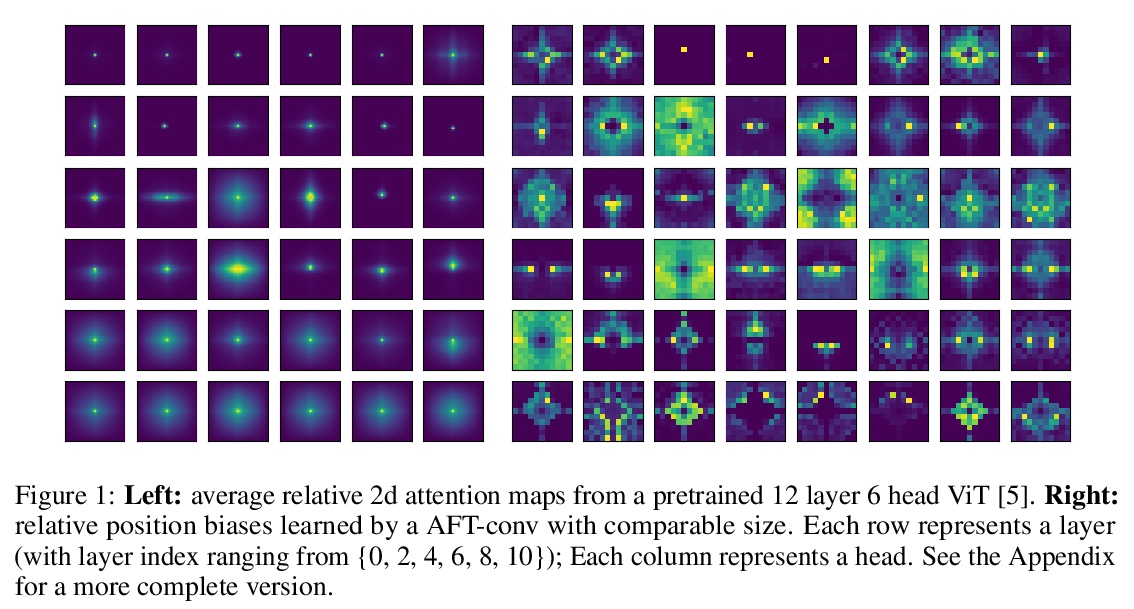
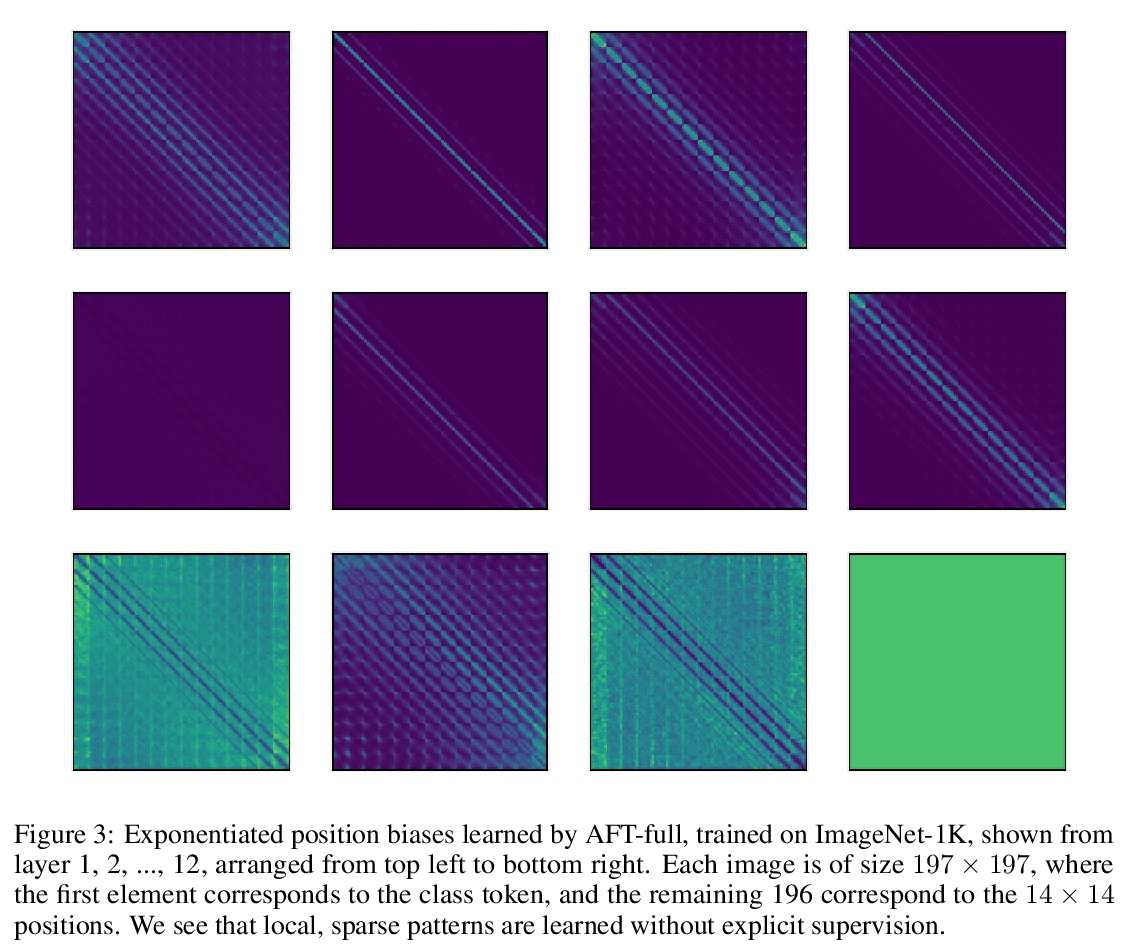
无注意力Transformer。提出了无注意力Transformer(AFT),Transformer的一种高效变体,消除了点积自注意力的需要。在AFT层,先将键和值与一组学习到的位置偏差相结合,其结果逐元素与查询相乘。这个新操作与上下文大小和特征维度相关的内存复杂度都是线性的,与大的输入和大模型可很好兼容。提出了AFT-local和AFT-conv两个模型变体,在保持全局连通性的同时利用了局部性和空间权重共享的理念。对两个自回归建模任务(CIFAR10和Enwik8)及图像识别任务(ImageNet-1K分类)进行了广泛实验,AFT在所有基准上都表现出有竞争力的性能,同时提供了出色的效率。
We introduce Attention Free Transformer (AFT), an efficient variant of Transformers [1] that eliminates the need for dot product self attention. In an AFT layer, the key and value are first combined with a set of learned position biases, the result of which is multiplied with the query in an element-wise fashion. This new operation has a memory complexity linear w.r.t. both the context size and the dimension of features, making it compatible to both large input and model sizes. We also introduce AFT-local and AFT-conv, two model variants that take advantage of the idea of locality and spatial weight sharing while maintaining global connectivity. We conduct extensive experiments on two autoregressive modeling tasks (CIFAR10 and Enwik8) as well as an image recognition task (ImageNet-1K classification). We show that AFT demonstrates competitive performance on all the benchmarks, while providing excellent efficiency at the same time.
https://weibo.com/1402400261/Kj0VHx87g


2、[CL] Comparing Test Sets with Item Response Theory
C Vania, P M Htut, W Huang, D Mungra, R Y Pang, J Phang, H Liu, K Cho, S R. Bowman
[Amazon & New York University & Allen Institute for AI]
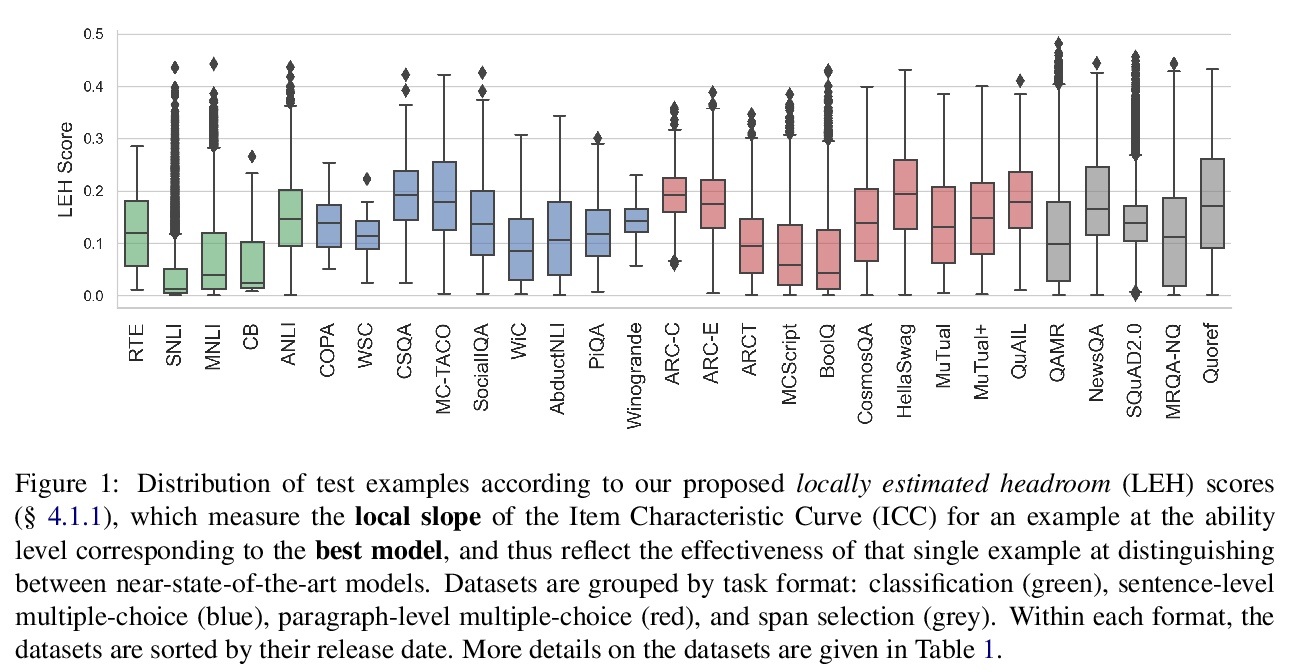
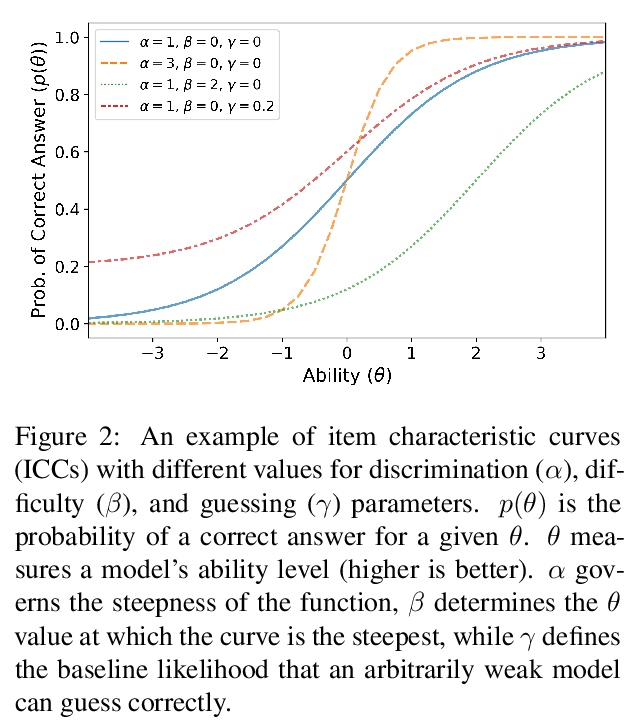
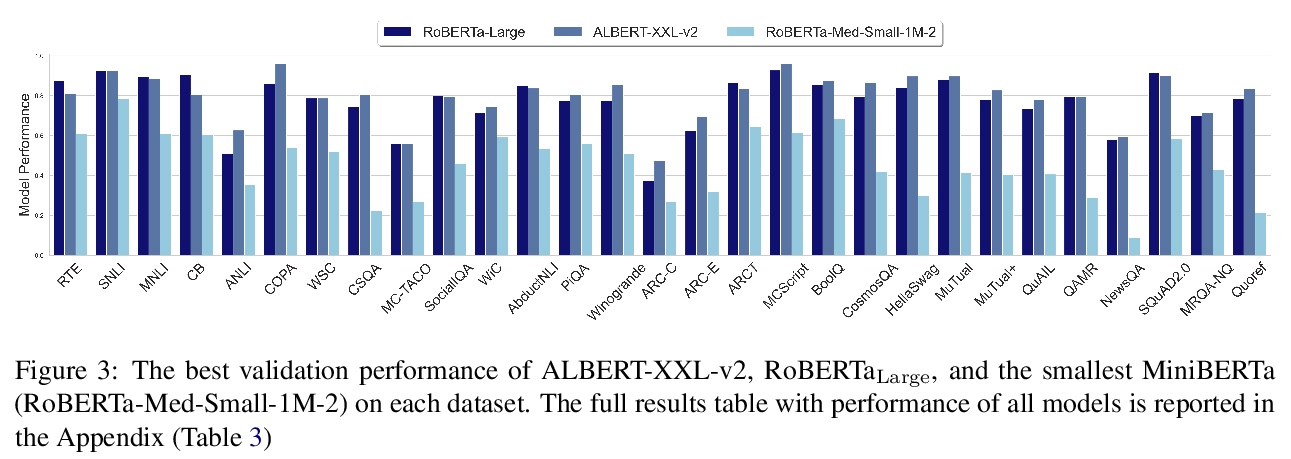
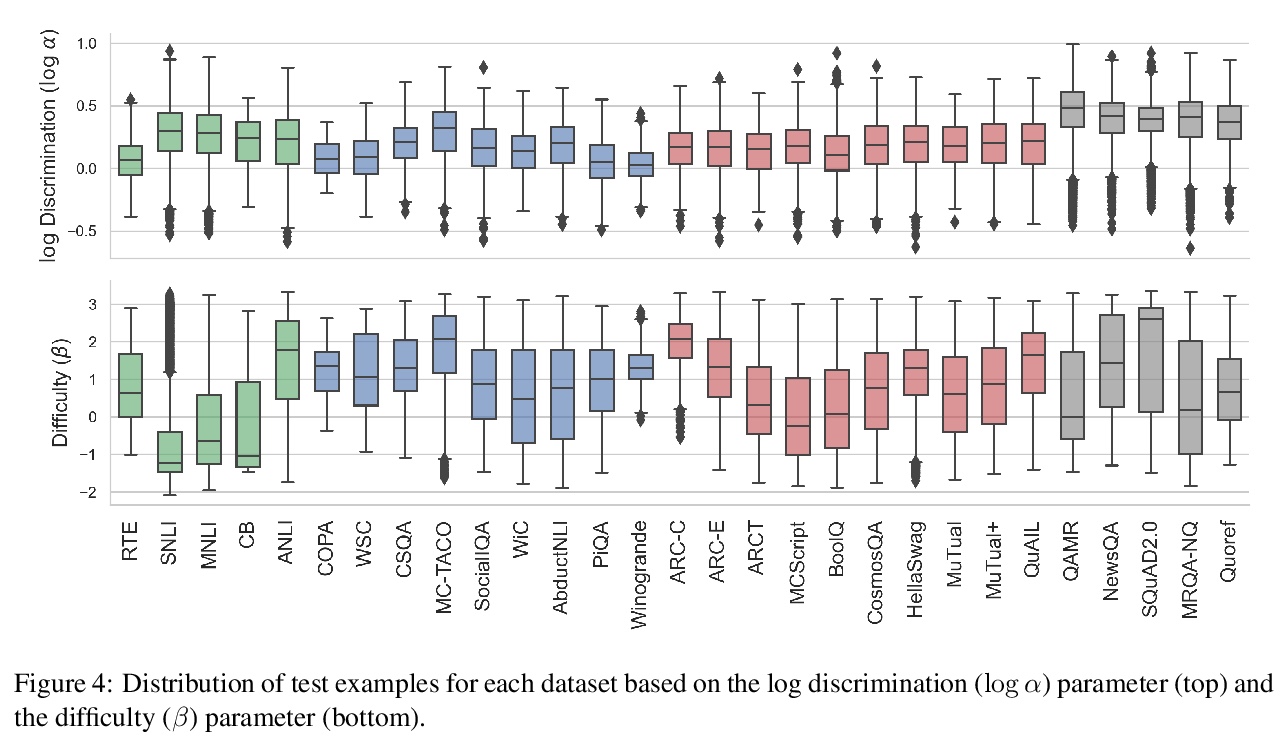
基于项目反应理论的测试集比较。近年来,提出了许多NLP数据集,以评估自然语言理解任务中微调模型的性能。不过,最近来自大型预训练模型的结果表明,许多这样的数据集基本上已经饱和,不太可能检测到进一步的进展。什么样的数据集在分辨强大模型方面仍然有效,应该期待什么样的数据集能检测到未来的改进?为了在不同的数据集上统一衡量,借鉴项目反应理论,用18个预训练的Transformer模型对单独的测试样本预测来评估29个数据集。发现Quoref、HellaSwag和MC-TACO最适合于分辨最先进模型,而SNLI、MNLI和CommitmentBank似乎对当前的强大模型已经饱和。还观察到跨度选择任务格式,用于QAMR或SQuAD2.0等QA数据集,在区分强模型和弱模型方面是有效的。
Recent years have seen numerous NLP datasets introduced to evaluate the performance of fine-tuned models on natural language understanding tasks. Recent results from large pretrained models, though, show that many of these datasets are largely saturated and unlikely to be able to detect further progress. What kind of datasets are still effective at discriminating among strong models, and what kind of datasets should we expect to be able to detect future improvements? To measure this uniformly across datasets, we draw on Item Response Theory and evaluate 29 datasets using predictions from 18 pretrained Transformer models on individual test examples. We find that Quoref, HellaSwag, and MC-TACO are best suited for distinguishing among state-of-the-art models, while SNLI, MNLI, and CommitmentBank seem to be saturated for current strong models. We also observe span selection task format, which is used for QA datasets like QAMR or SQuAD2.0, is effective in differentiating between strong and weak models.
https://weibo.com/1402400261/Kj0ZqjZ16
3、[CL] Attention Flows are Shapley Value Explanations
K Ethayarajh, D Jurafsky
[Stanford University]
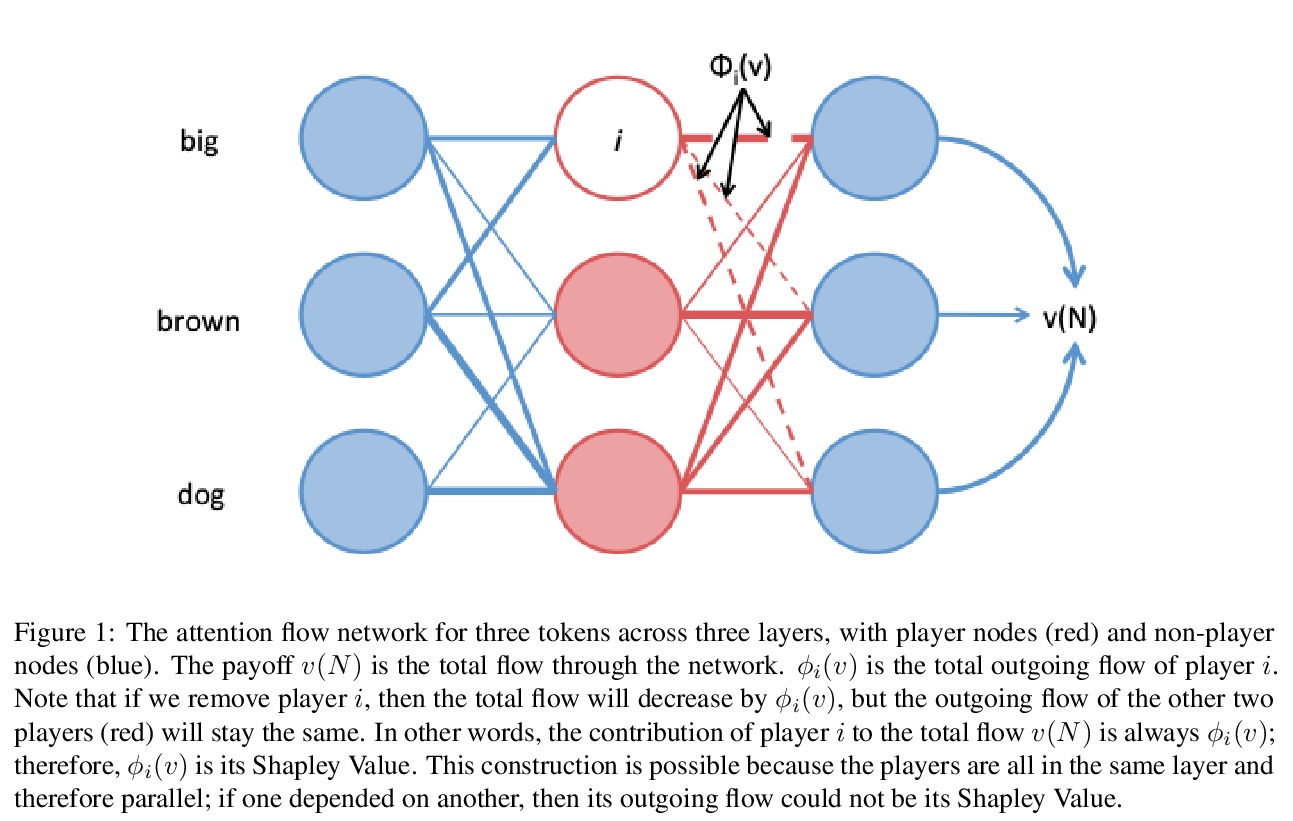
注意力流是Shapley值解释。Shapley值是合作博弈论中信用分配问题的解决方案,是机器学习一种流行的解释类型,用来解释特征、嵌入、甚至神经元的重要性。在NLP中,留一法和基于注意力的解释仍然占主导地位。能在这些不同的方法之间建立起联系吗?本文正式证明——除了退化的情况——注意力权重和留一值不能是Shapley值。注意力流是注意力权重的一个后处理变体,通过在注意力图上运行最大流算法获得。本文证明了注意力流确实是Shapley值,至少在层级上。考虑到Shapley值的许多理想的理论品质——这些品质推动了其在机器学习社区的广泛采用——NLP从业者应该在采用更传统解释的同时,在可能的情况下采用注意力流的解释。
Shapley Values, a solution to the credit assignment problem in cooperative game theory, are a popular type of explanation in machine learning, having been used to explain the importance of features, embeddings, and even neurons. In NLP, however, leave-oneout and attention-based explanations still predominate. Can we draw a connection between these different methods? We formally prove that — save for the degenerate case — attention weights and leave-one-out values cannot be Shapley Values. Attention flow is a post-processed variant of attention weights obtained by running the max-flow algorithm on the attention graph. Perhaps surprisingly, we prove that attention flows are indeed Shapley Values, at least at the layerwise level. Given the many desirable theoretical qualities of Shapley Values — which has driven their adoption among the ML community — we argue that NLP practitioners should, when possible, adopt attention flow explanations alongside more traditional ones.
https://weibo.com/1402400261/Kj12s0ADU
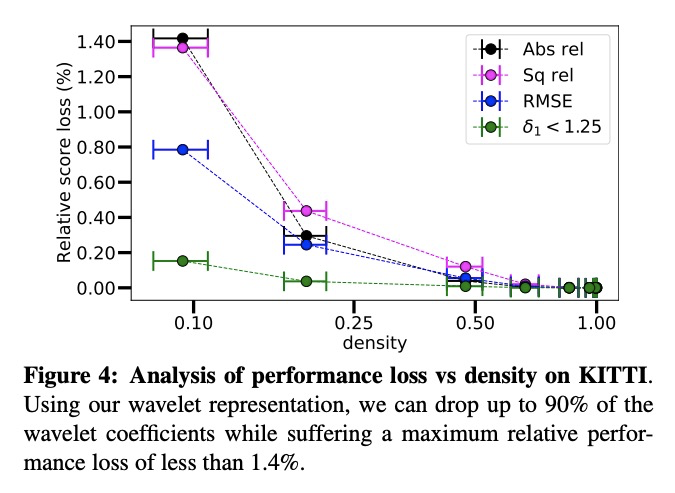
4、[CV] Single Image Depth Estimation using Wavelet Decomposition
M Ramamonjisoa, M Firman, J Watson, V Lepetit, D Turmukhambetov
[Univ Gustave Eiffel & Niantic]
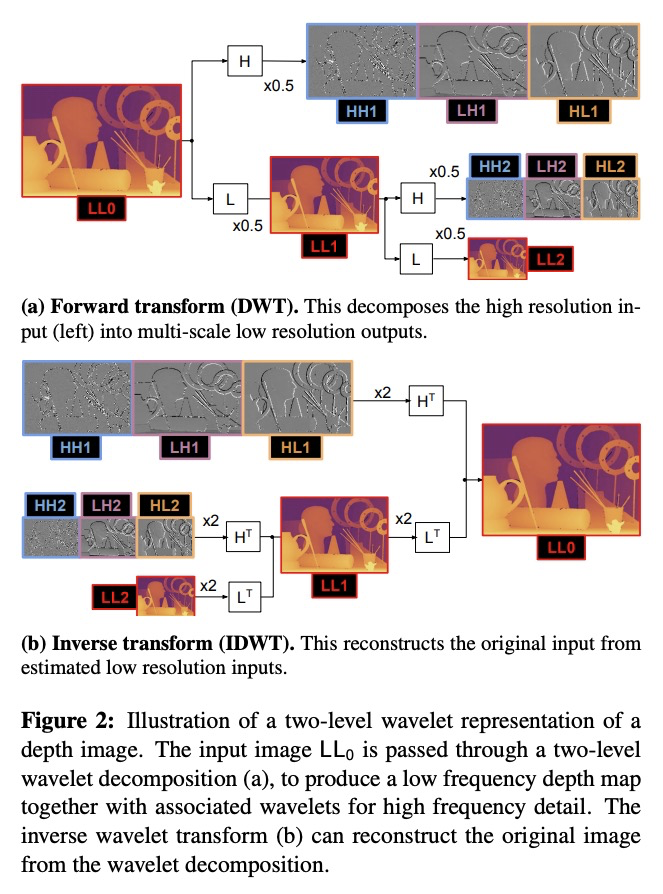
小波分解单目图像深度估计。提出一种通过小波分解实现的高效预测单目图像准确深度的新方法,将小波分解整合到完全可微的编码器-解码器架构中,通过预测稀疏小波系数重建高保真深度图。与之前工作相比,小波系数可在无系数直接监督的情况下学习,只对通过反小波变换重建的最终深度图进行监督。小波系数可以在完全自监督的情况下学习,不需要深度真值。将该方法应用于不同的最先进的单目深度估计模型,在每种情况下,与原始模型相比,都给出了类似或更好的结果,而在解码器网络中只需要不到一半的多重加法。
We present a novel method for predicting accurate depths from monocular images with high efficiency. This optimal efficiency is achieved by exploiting wavelet decomposition, which is integrated in a fully differentiable encoder-decoder architecture. We demonstrate that we can reconstruct high-fidelity depth maps by predicting sparse wavelet coefficients. In contrast with previous works, we show that wavelet coefficients can be learned without direct supervision on coefficients. Instead we supervise only the final depth image that is reconstructed through the inverse wavelet transform. We additionally show that wavelet coefficients can be learned in fully self-supervised scenarios, without access to ground-truth depth. Finally, we apply our method to different state-of-the-art monocular depth estimation models, in each case giving similar or better results compared to the original model, while requiring less than half the multiply-adds in the decoder network.
https://weibo.com/1402400261/Kj17HmQE4


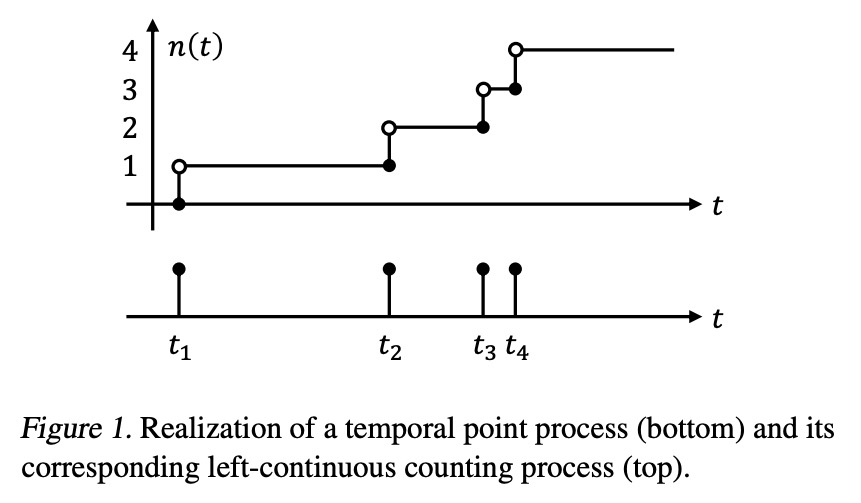
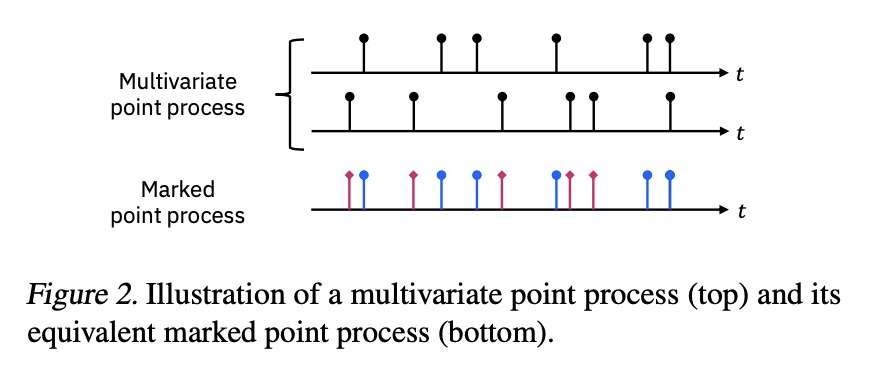
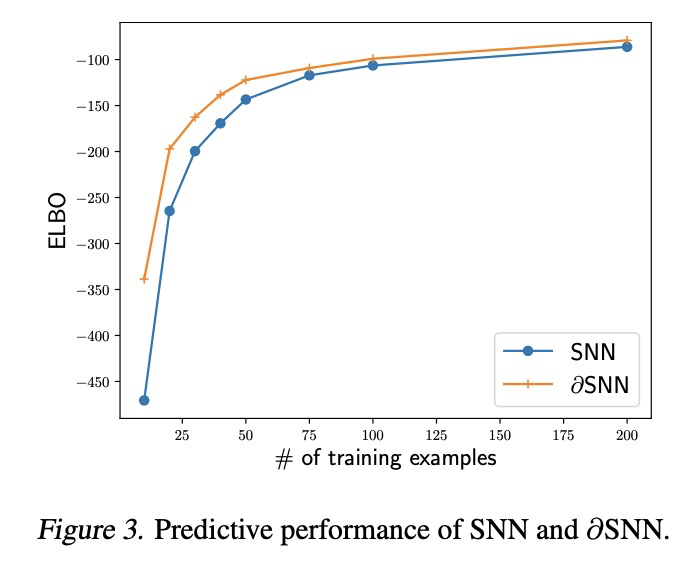
5、[LG] A Differentiable Point Process with Its Application to Spiking Neural Networks
H Kajino
[IBM Research]
一种可微点过程及其在尖峰神经网络中的应用。本文关注的是尖峰神经网络(SNN)的概率模型的学习算法。Jimenez Rezende & Gerstner提出了一种随机变分推理算法,用来训练带有隐藏神经元的SNN。该算法使用分数函数梯度估计器更新变分分布,其高方差往往阻碍了整个学习算法。本文提出一种基于路径级梯度估计器的SNN替代梯度估计器。主要技术难点是缺乏对任意点过程实现进行微分的一般方法,而这是推导路径级梯度估计器的必要条件。提出了一种可微点过程,用它来推导SNN的路径级梯度估计器。通过数值模拟研究了该梯度估计器的有效性。
This paper is concerned about a learning algorithm for a probabilistic model of spiking neural networks (SNNs). Jimenez Rezende & Gerstner (2014) proposed a stochastic variational inference algorithm to train SNNs with hidden neurons. The algorithm updates the variational distribution using the score function gradient estimator, whose high variance often impedes the whole learning algorithm. This paper presents an alternative gradient estimator for SNNs based on the path-wise gradient estimator. The main technical difficulty is a lack of a general method to differentiate a realization of an arbitrary point process, which is necessary to derive the path-wise gradient estimator. We develop a differentiable point process, which is the technical highlight of this paper, and apply it to derive the path-wise gradient estimator for SNNs. We investigate the effectiveness of our gradient estimator through numerical simulation.
https://weibo.com/1402400261/Kj1c6EjnN
另外几篇值得关注的论文:
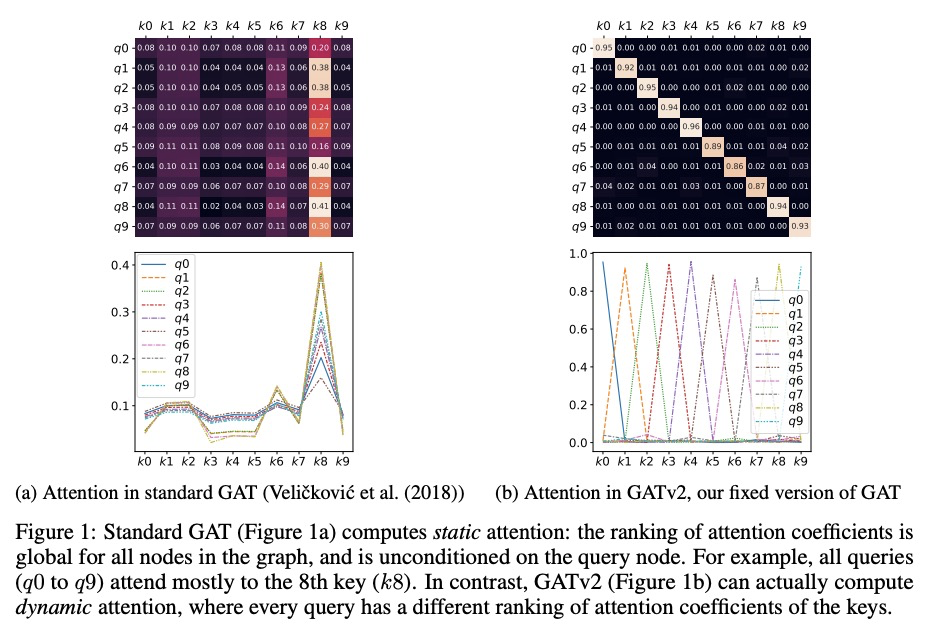
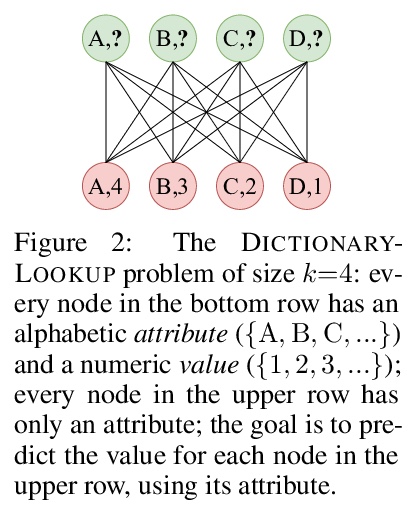
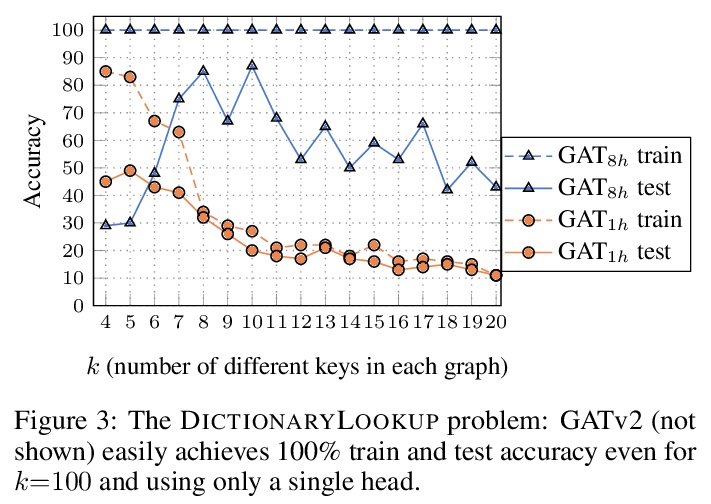
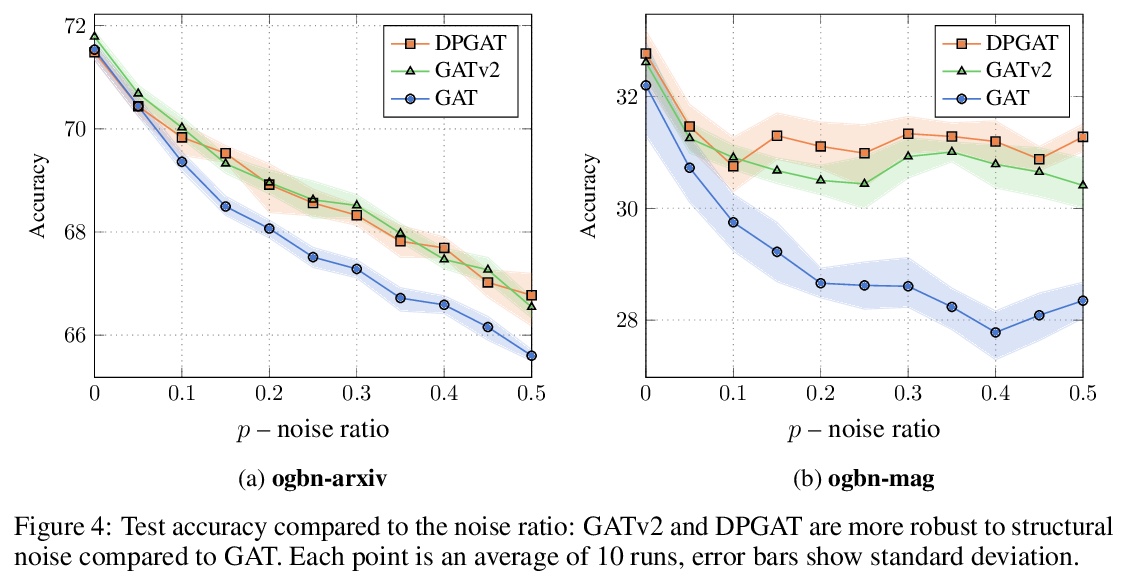
[LG] How Attentive are Graph Attention Networks?
图注意力网络注意力有多强?
S Brody, U Alon, E Yahav
[Technion]
https://weibo.com/1402400261/Kj1f1gy2s
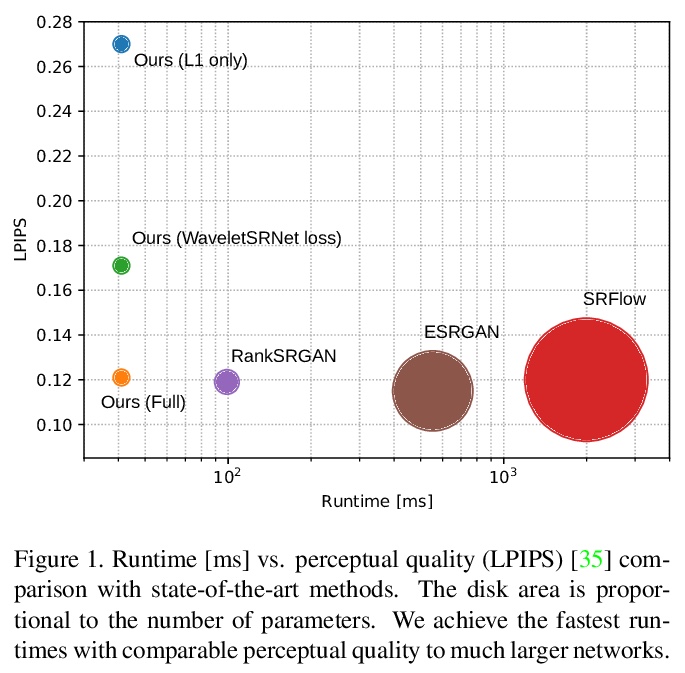
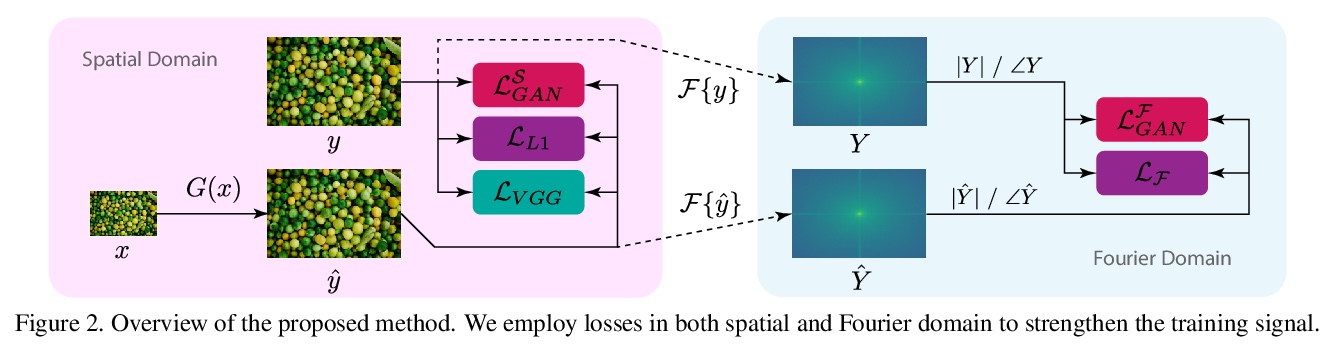
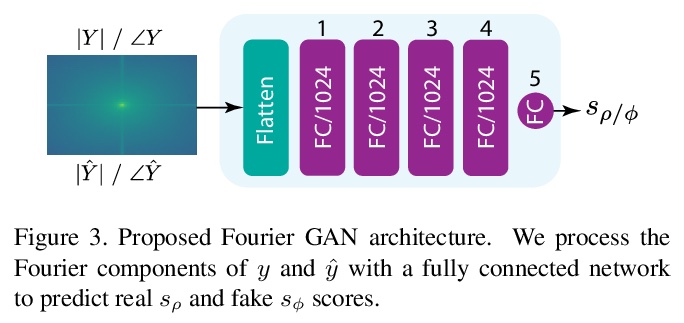
[CV] Fourier Space Losses for Efficient Perceptual Image Super-Resolution
基于傅里叶空间损失的高效感知图像超分辨率
D Fuoli, L V Gool, R Timofte
[ETH Zurich]
https://weibo.com/1402400261/Kj1i1DhoZ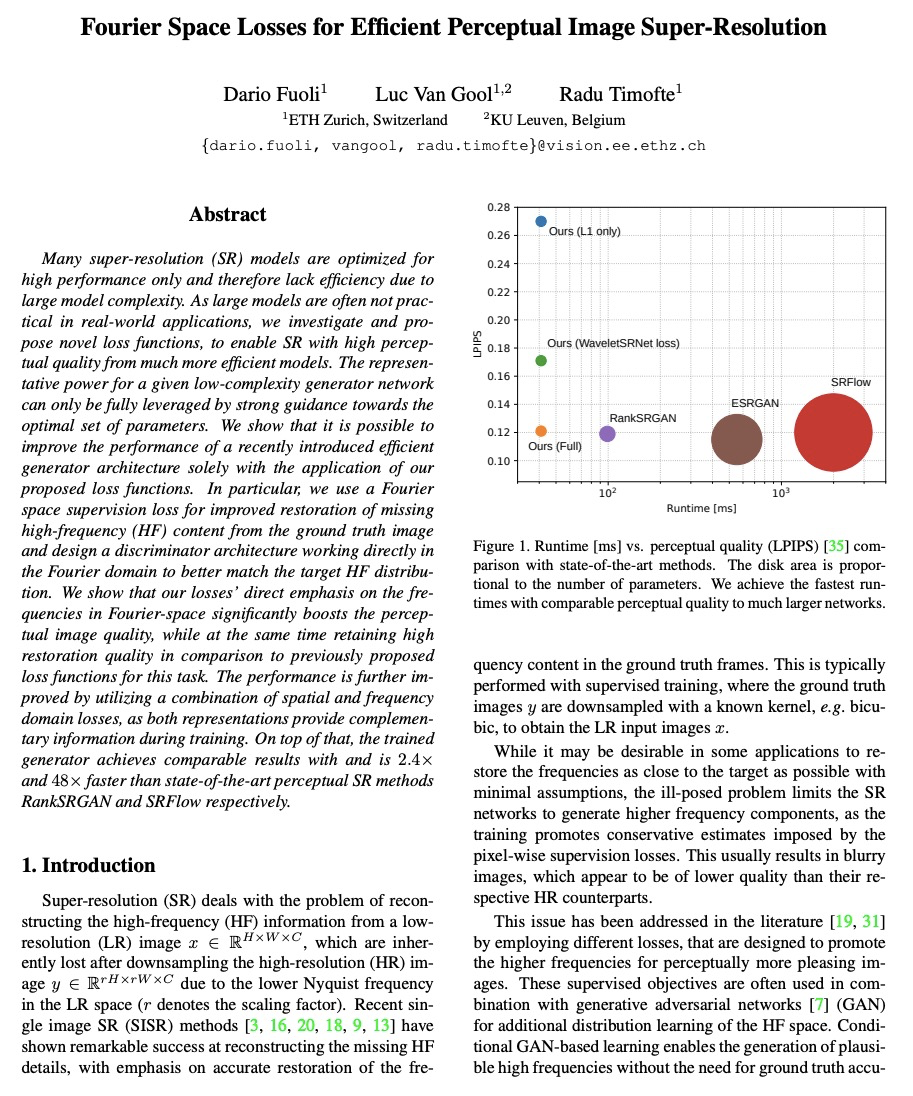

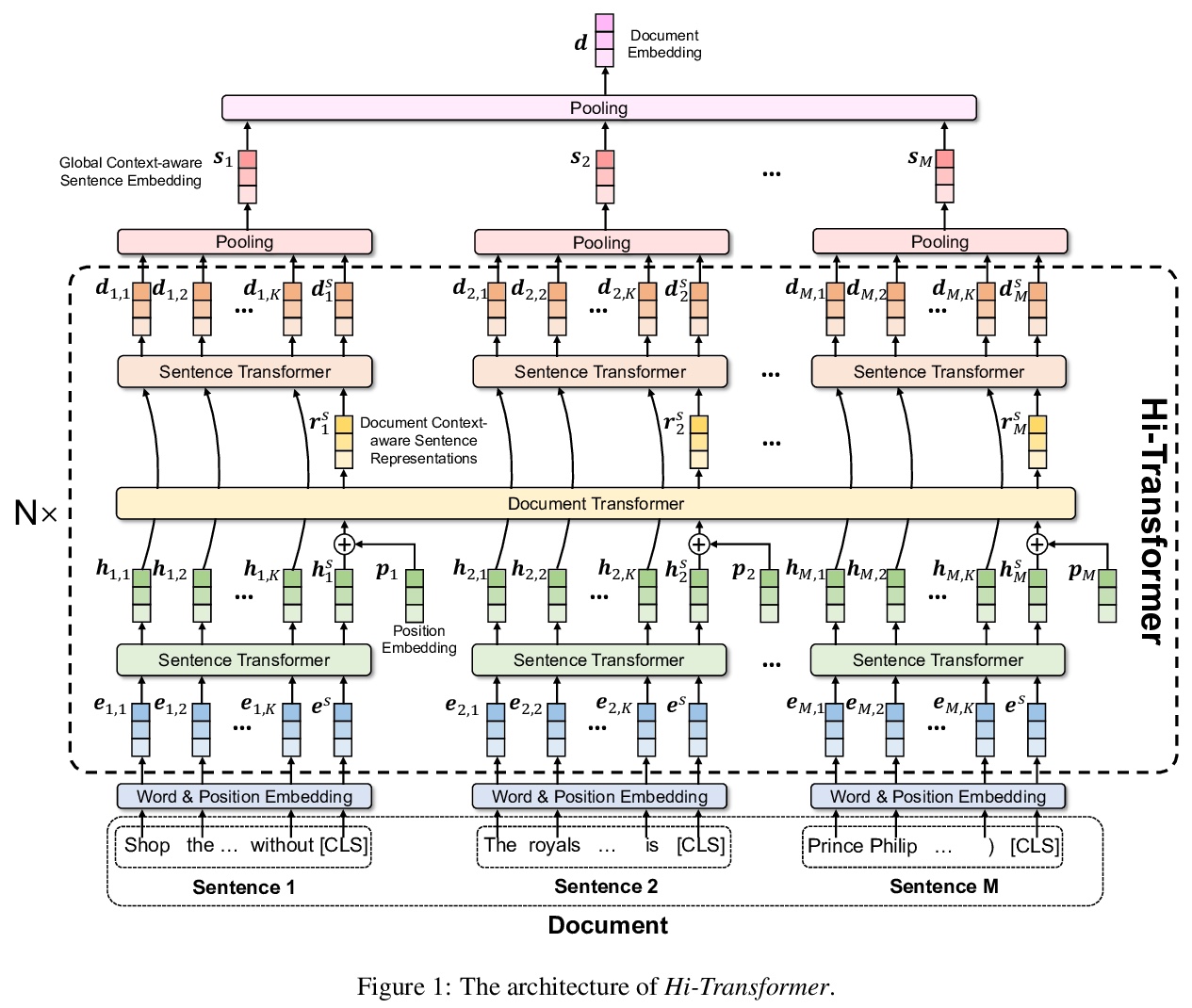
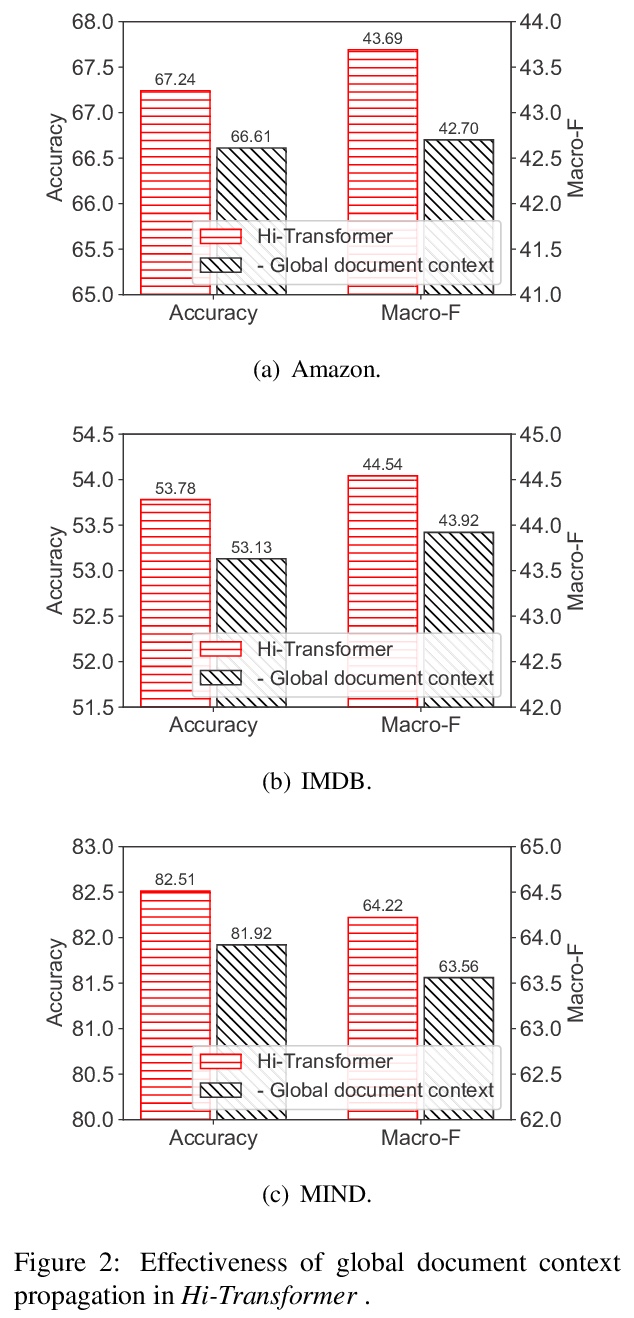
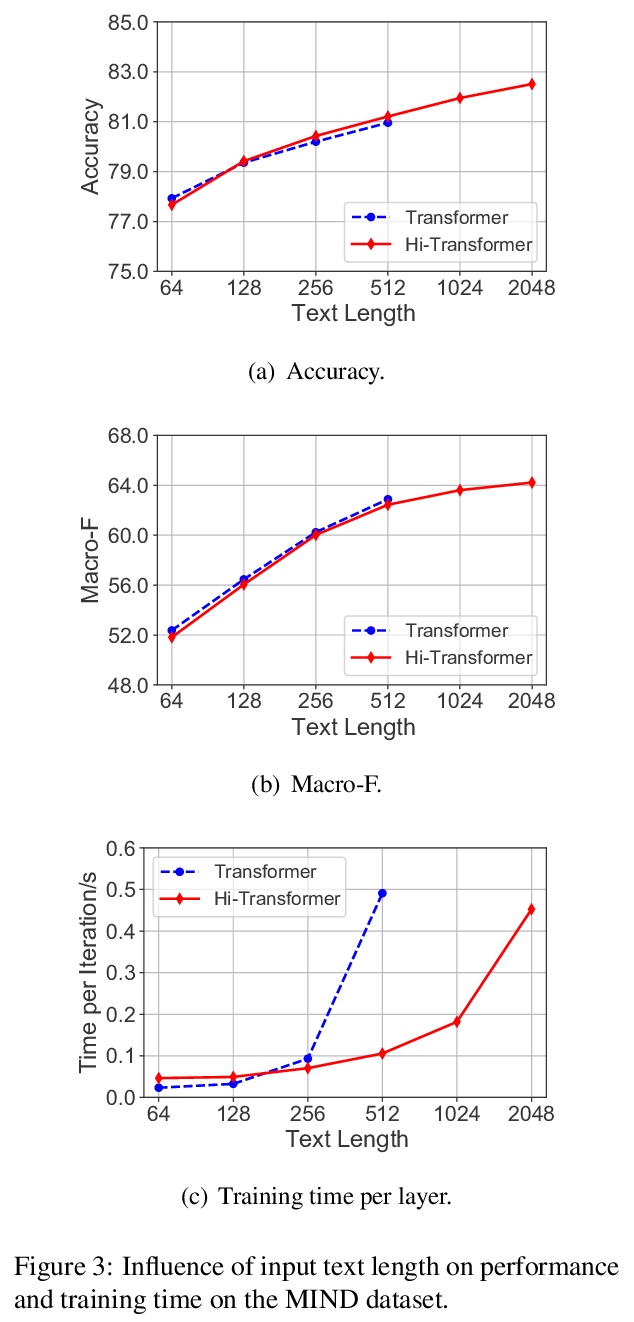
[CL] Hi-Transformer: Hierarchical Interactive Transformer for Efficient and Effective Long Document Modeling
Hi-Transformer:面向高效长文档建模的分层交互Transformer
C Wu, F Wu, T Qi, Y Huang
[Tsinghua University & Microsoft Research Asia]
https://weibo.com/1402400261/Kj1jxBhn7
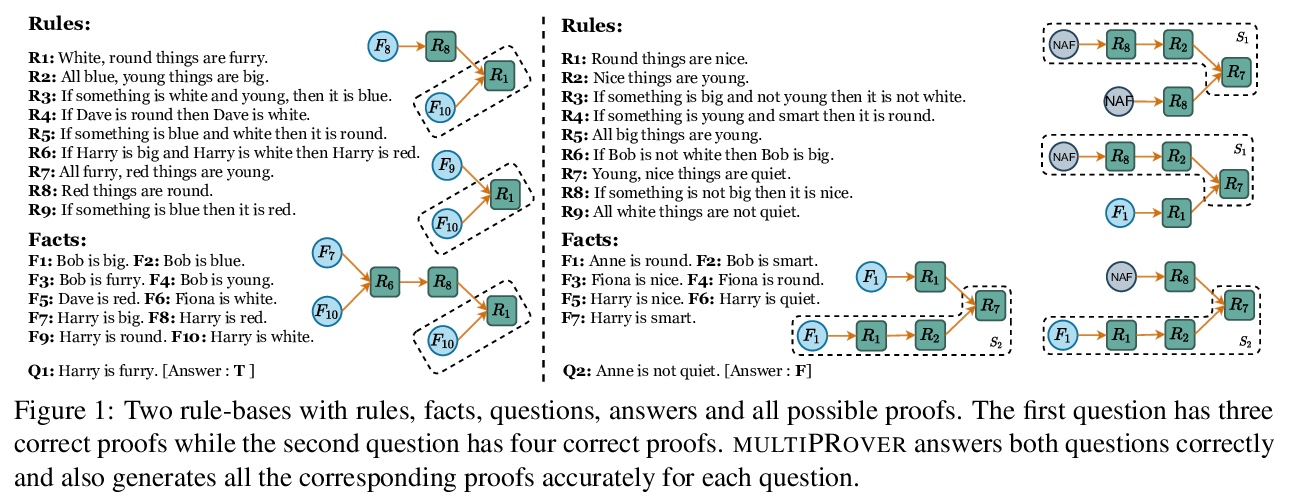
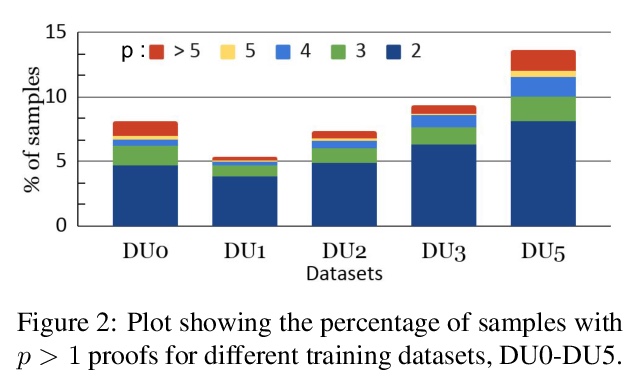
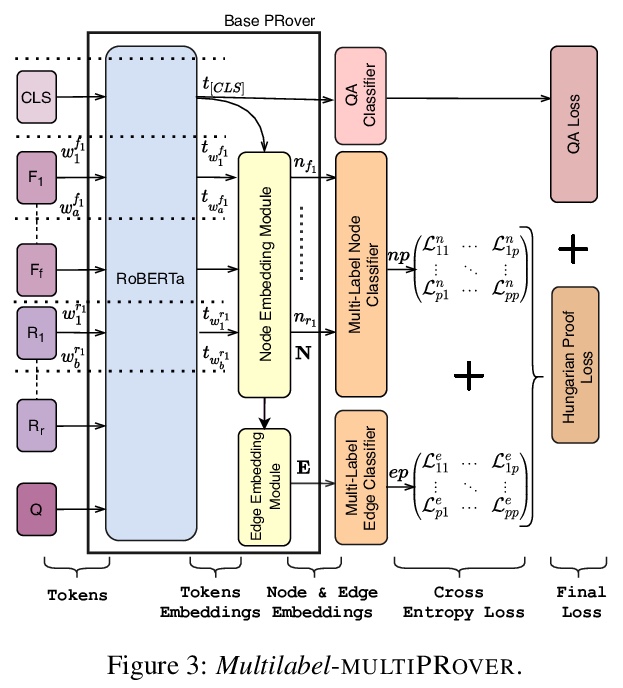
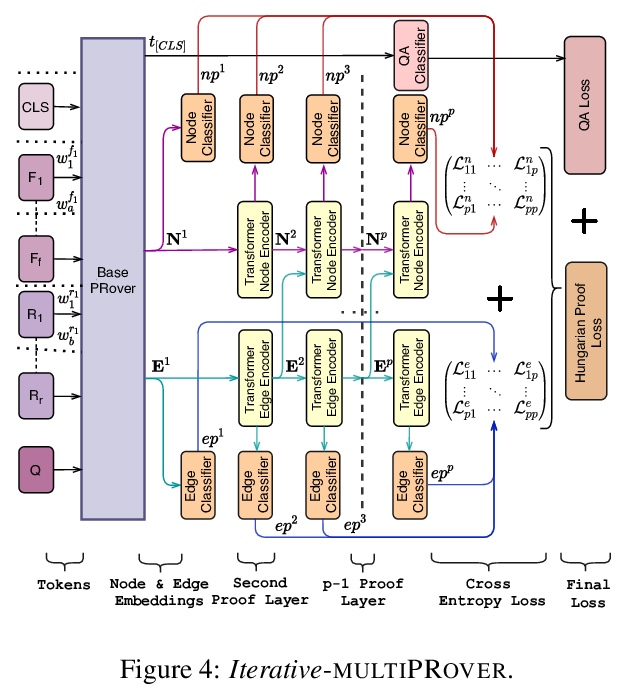
[CL] multiPRover: Generating Multiple Proofs for Improved Interpretability in Rule Reasoning
multiPRover:生成多重证明以提高规则推理的可解释性
S Saha, P Yadav, M Bansal
[UNC Chapel Hill]
https://weibo.com/1402400261/Kj1kUqQcm

若有收获,就点个赞吧
0 人点赞
