LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] **Neural Scene Graphs for Dynamic Scenes
J Ost, F Mannan, N Thuerey, J Knodt, F Heide
[Algolux & Technical University of Munich & Princeton University]
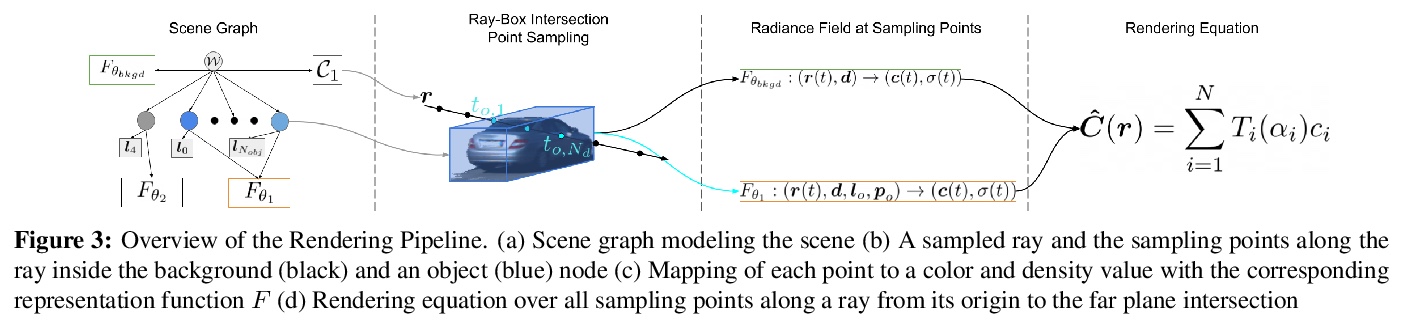
面向动态场景视图合成的神经网络场景图方法。提出一种神经网络渲染方法,将动态场景分解成场景图。提出一种场景图表示学习方法,编码目标转换和亮度,用神经网络隐式表示动态场景,以有效渲染新的编排和新视图场景。该方法利用视频和带标记的跟踪数据,学习多个动态和静态场景元素的图结构化的、连续的空间表示,自动将场景分解为多个独立图节点。通过对模拟数据和真实数据的合成实验,实现了照片级逼真的质量,而在此之前,只有在多视图监督的静态场景下才能实现。**
Recent implicit neural rendering methods have demonstrated that it is possible to learn accurate view synthesis for complex scenes by predicting their volumetric density and color supervised solely by a set of RGB images. However, existing methods are restricted to learning efficient interpolations of static scenes that encode all scene objects into a single neural network, lacking the ability to represent dynamic scenes and decompositions into individual scene objects. In this work, we present the first neural rendering method that decomposes dynamic scenes into scene graphs. We propose a learned scene graph representation, which encodes object transformation and radiance, to efficiently render novel arrangements and views of the scene. To this end, we learn implicitly encoded scenes, combined with a jointly learned latent representation to describe objects with a single implicit function. We assess the proposed method on synthetic and real automotive data, validating that our approach learns dynamic scenes - only by observing a video of this scene - and allows for rendering novel photo-realistic views of novel scene compositions with unseen sets of objects at unseen poses.
https://weibo.com/1402400261/Jvk75osf6

2、[RO] Reactive Human-to-Robot Handovers of Arbitrary Object**s
W Yang, C Paxton, A Mousavian, Y Chao, M Cakmak, D Fox
[NVIDIA & University of Washington]
任意物体的人-机器人移交。提出一个可推广到各种未知目标的基于视觉的人-机器人移交系统,结合闭环运动规划和实时的时间一致的抓取生成,确保反应性和运动平滑性。对用户如何向机器人呈现目标没有硬性限制,只要以机器人能抓取的方式持有它即可。系统对不同的目标位置和方向具有较强的鲁棒性,可抓取刚体和非刚体目标,可适应用户偏好,对用户的动作做出反应,并生成平稳、安全的抓握和动作。**
Human-robot object handovers have been an actively studied area of robotics over the past decade; however, very few techniques and systems have addressed the challenge of handing over diverse objects with arbitrary appearance, size, shape, and rigidity. In this paper, we present a vision-based system that enables reactive human-to-robot handovers of unknown objects. Our approach combines closed-loop motion planning with real-time, temporally-consistent grasp generation to ensure reactivity and motion smoothness. Our system is robust to different object positions and orientations, and can grasp both rigid and non-rigid objects. We demonstrate the generalizability, usability, and robustness of our approach on a novel benchmark set of 26 diverse household objects, a user study with naive users (N=6) handing over a subset of 15 objects, and a systematic evaluation examining different ways of handing objects. More results and videos can be found at > this https URL.
https://weibo.com/1402400261/JvkdO6xAF


3、[LG] **It’s Not What Machines Can Learn, It’s What We Cannot Teach
G Yehuda, M Gabel, A Schuster
[Israel Institute of Technology & University of Toronto]
不是机器学不会,是我们没法教。文中表示,仅考虑网络的表示能力和损失表面的特性是不够的,还需要考虑产生训练数据的过程。在NP≠coNP这一常见假设下,证明了NP-hard问题的任何多项式时间样本生成器实际上都是从一个较简单的子问题中得到的。通过实证探索,展示了常见的数据生成技术是如何生成有偏的数据集,从而导致从业者高估模型的准确性。结果表明,需要在目标分布的密集均匀采样上进行训练的机器学习方法,不能用于解决计算上困难的问题,原因是难以生成足够大且无偏的训练集。对于NP-hard问题的任何有效采样技术都是无可避免地有偏的:从问题空间的某些部分采样概率为零——没有哪一种有效的采样器是完备的。更糟的是,采样得到的子问题比原来的NP-hard问题更简单。因此,增加训练集大小的常用方法(如数据增广)会导致训练集不能反映全部问题,在这样的数据集上训练的任何机器学习模型,都不能学会解决或近似整个NP-hard问题——只能学会更容易的子问题。**
Can deep neural networks learn to solve any task, and in particular problems of high complexity? This question attracts a lot of interest, with recent works tackling computationally hard tasks such as the traveling salesman problem and satisfiability. In this work we offer a different perspective on this question. Given the common assumption that > NP≠coNP we prove that any polynomial-time sample generator for an > NP-hard problem samples, in fact, from an easier sub-problem. We empirically explore a case study, Conjunctive Query Containment, and show how common data generation techniques generate biased datasets that lead practitioners to over-estimate model accuracy. Our results suggest that machine learning approaches that require training on a dense uniform sampling from the target distribution cannot be used to solve computationally hard problems, the reason being the difficulty of generating sufficiently large and unbiased training sets.
https://weibo.com/1402400261/Jvkido0vE
4、[CV] **Exploring Simple Siamese Representation Learning
X Chen, K He
[Facebook AI Research (FAIR)]
简单孪生表示学习探索。探索了简单设计的孪生网络,证明没有负样本对、大批量和动量编码器的简单孪生网络就可以学习有意义的表示,并进一步表明,最新方法的孪生结构是有效性的一个关键原因。建模不变性是表示学习的焦点问题,而孪生网络是建模不变性的天然和有效的工具。**
Siamese networks have become a common structure in various recent models for unsupervised visual representation learning. These models maximize the similarity between two augmentations of one image, subject to certain conditions for avoiding collapsing solutions. In this paper, we report surprising empirical results that simple Siamese networks can learn meaningful representations even using none of the following: (i) negative sample pairs, (ii) large batches, (iii) momentum encoders. Our experiments show that collapsing solutions do exist for the loss and structure, but a stop-gradient operation plays an essential role in preventing collapsing. We provide a hypothesis on the implication of stop-gradient, and further show proof-of-concept experiments verifying it. Our “SimSiam” method achieves competitive results on ImageNet and downstream tasks. We hope this simple baseline will motivate people to rethink the roles of Siamese architectures for unsupervised representation learning. Code will be made available.
https://weibo.com/1402400261/JvkoZ06tn


其他几篇值得关注的论文:
[LG] Policy Gradient Methods for the Noisy Linear Quadratic Regulator over a Finite Horizon
有限时域噪声线性二次调节器的策略梯度方法
B Hambly, R Xu, H Yang
[University of Oxford]
https://weibo.com/1402400261/JvkzvpBqP

[CV] Leveraging Temporal Joint Depths for Improving 3D Human Pose Estimation in Video
用时间联合深度改善视频3D人体姿态估计
N Kato, H Honda, Y Uchida
[Mobility Technologies Co., Ltd]
https://weibo.com/1402400261/JvkukAMTk
[LG] Contrastive Topographic Models: Energy-based density models applied to the understanding of sensory coding and cortical topography
(博士论文)对比地形模型:用于感觉编码和皮层地形理解的能量密度模型
S Osindero
[University College London]
https://weibo.com/1402400261/Jvkx6uZhj


若有收获,就点个赞吧
0 人点赞
