LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 SI - 社交网络 (*表示值得重点关注)
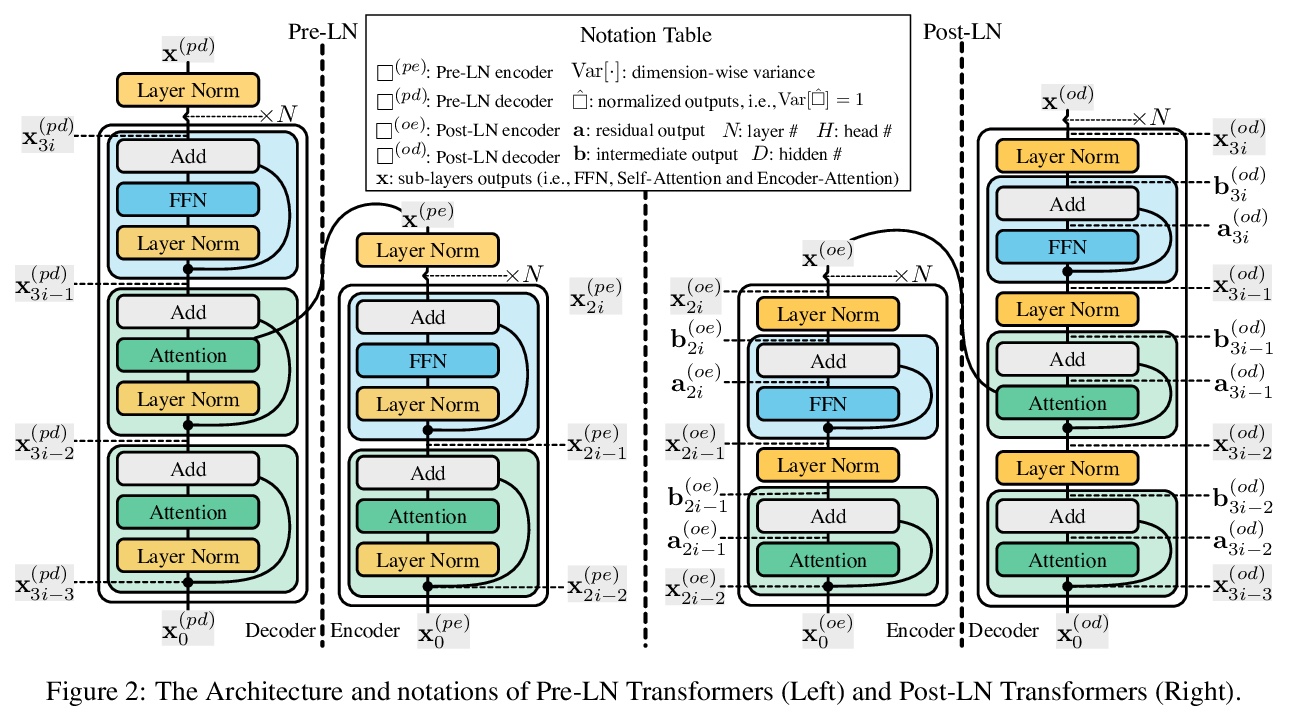
1、[LG] **Understanding the Difficulty of Training Transformers
L Liu, X Liu, J Gao, W Chen, J Han
[University of Illinois at Urbana-Champaign & Microsoft Research & Microsoft Dynamics 365 AI]
从理论和实证两方面研究Transformer训练的难点。分析表明,梯度消失问题、不平衡梯度并非导致训练不稳定的根本原因。发现一个显著影响训练的放大效应——对于Transformer模型中的每一层,对其残差分支的严重依赖使得训练不稳定,因为它放大了小的参数扰动(例如,参数更新),并导致模型输出中显著的扰动。提出Admin (Adaptive model initialization),一种自适应初始化方法,用来稳定早期训练,并在后期释放其全部潜力。实验表明,在不引入额外的超参数的情况下,Admin实现了更稳定的训练,更快的收敛,以及更好的性能。
Transformers have proved effective in many NLP tasks. However, their training requires non-trivial efforts regarding designing cutting-edge optimizers and learning rate schedulers carefully (e.g., conventional SGD fails to train Transformers effectively). Our objective here is to understand > what complicates Transformer training from both empirical and theoretical perspectives. Our analysis reveals that unbalanced gradients are not the root cause of the instability of training. Instead, we identify an amplification effect that influences training substantially — for each layer in a multi-layer Transformer model, heavy dependency on its residual branch makes training unstable, since it amplifies small parameter perturbations (e.g., parameter updates) and results in significant disturbances in the model output. Yet we observe that a light dependency limits the model potential and leads to inferior trained models. Inspired by our analysis, we propose Admin (> Adaptive > model > in**itialization) to stabilize stabilize the early stage’s training and unleash its full potential in the late stage. Extensive experiments show that Admin is more stable, converges faster, and leads to better performance. Implementations are released at: > this https URL.
https://weibo.com/1402400261/JtNSf4m2l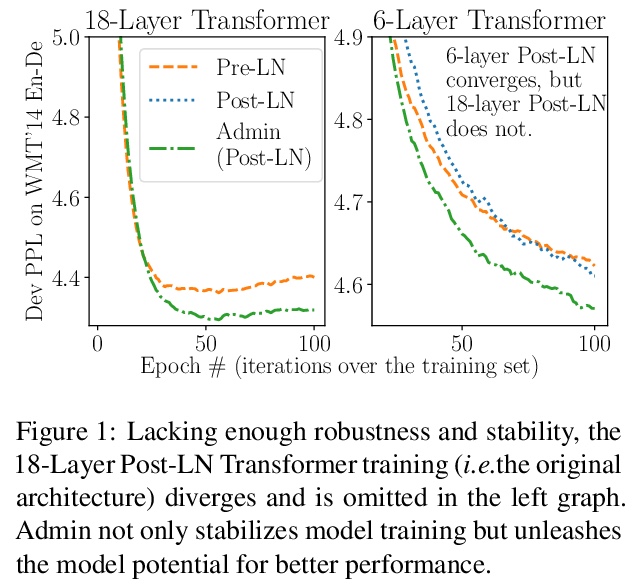
2、[SI] Sentiment Diffusion in Financial News Networks and Associated Market Movements
X Wan, J Yang, S Marinov, J Calliess, S Zohren, X Dong
[University of Oxford & Harvard University & Man AHL]
金融新闻网络的情绪扩散和相关市场动向。用NLP技术,对路透社7年来报道最多的87家公司的新闻情绪进行了分析,研究了这种情绪在公司网络中的传播,并评估了股票价格和波动性方面的相关市场动态。结果表明,在某些领域,媒体对某家公司的强烈情绪可能表明,在由新闻共现构建的金融网络中,媒体对相关共现公司的情绪可能发生了显著变化。此外,强烈的媒体情绪与异常的市场回报和波动性之间存在微弱但在统计上显著的关联。这种关联在单个公司的层面上更为显著,但在部门或公司集团的层面上仍然可见。
In an increasingly connected global market, news sentiment towards one company may not only indicate its own market performance, but can also be associated with a broader movement on the sentiment and performance of other companies from the same or even different sectors. In this paper, we apply NLP techniques to understand news sentiment of 87 companies among the most reported on Reuters for a period of seven years. We investigate the propagation of such sentiment in company networks and evaluate the associated market movements in terms of stock price and volatility. Our results suggest that, in certain sectors, strong media sentiment towards one company may indicate a significant change in media sentiment towards related companies measured as neighbours in a financial network constructed from news co-occurrence. Furthermore, there exists a weak but statistically significant association between strong media sentiment and abnormal market return as well as volatility. Such an association is more significant at the level of individual companies, but nevertheless remains visible at the level of sectors or groups of companies.
https://weibo.com/1402400261/JtNYpDoGB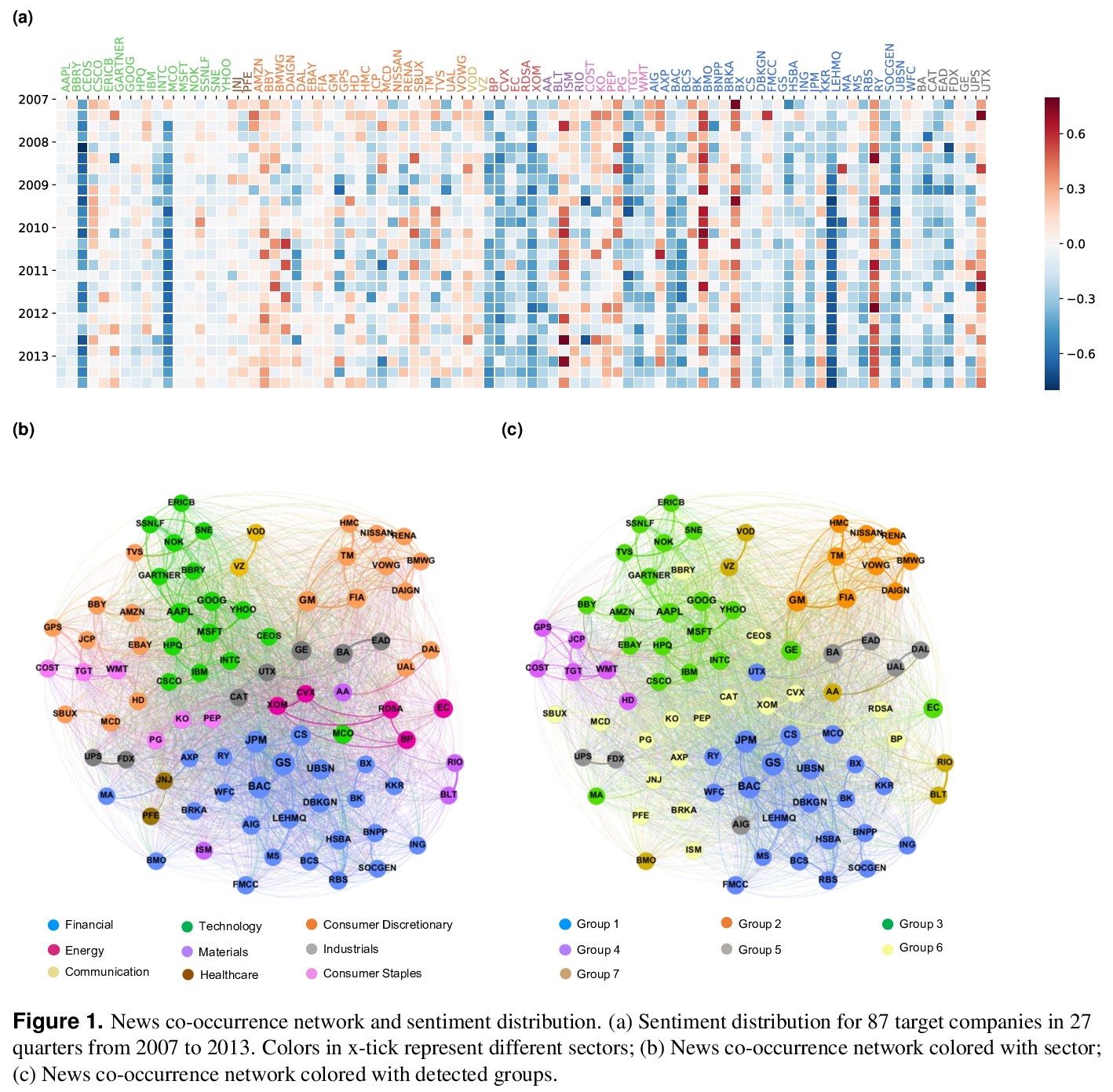
3、[CV] Few-shot Image Generation with Elastic Weight Consolidation
Y Li, R Zhang, JC Lu, E Shechtman
[Adobe Research]
弹性权重合并少样本图像生成。在只给出目标域少量实例的情况下,采用预训练的生成模型,在数据丰富的源域进行学习,生成更多的目标域数据。受持续学习的启发,分析权重重要性并将其量化,有选择地对自适应过程中的权重变化进行正则化,既实现了对源域多样性的继承,又实现了对目标域新外观的自适应,避免了数据有限时易出现的过拟合问题。
Few-shot image generation seeks to generate more data of a given domain, with only few available training examples. As it is unreasonable to expect to fully infer the distribution from just a few observations (e.g., emojis), we seek to leverage a large, related source domain as pretraining (e.g., human faces). Thus, we wish to preserve the diversity of the source domain, while adapting to the appearance of the target. We adapt a pretrained model, without introducing any additional parameters, to the few examples of the target domain. Crucially, we regularize the changes of the weights during this adaptation, in order to best preserve the information of the source dataset, while fitting the target. We demonstrate the effectiveness of our algorithm by generating high-quality results of different target domains, including those with extremely few examples (e.g., 10). We also analyze the performance of our method with respect to some important factors, such as the number of examples and the similarity between the source and target domain.
https://weibo.com/1402400261/JtO65txL6
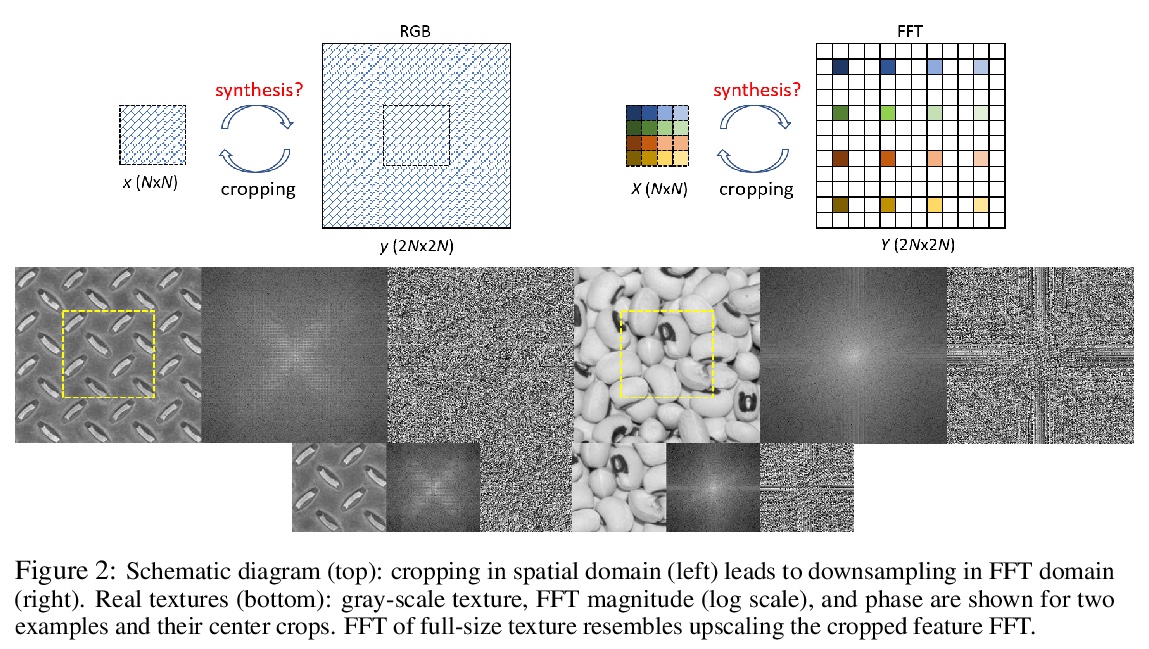
4、[CV] Neural FFTs for Universal Texture Image Synthesis
M Mardani, G Liu, A Dundar, S Liu, A Tao, B Catanzaro
[NVIDIA]
神经网络快速傅里叶变换(FFT)通用纹理图像合成。在快速傅里叶变换(FFT)域中,纹理合成可看作是(局部)上采样,但自然图像FFT具有较高动态范围,缺乏局部相关性,本文提出一种新的基于FFT的通用纹理合成CNN框架,用可变形卷积在特征空间执行FFT上采样,可泛化到不可见图像,实现单次合成纹理。
Synthesizing larger texture images from a smaller exemplar is an important task in graphics and vision. The conventional CNNs, recently adopted for synthesis, require to train and test on the same set of images and fail to generalize to unseen images. This is mainly because those CNNs fully rely on convolutional and upsampling layers that operate locally and not suitable for a task as global as texture synthesis. In this work, inspired by the repetitive nature of texture patterns, we find that texture synthesis can be viewed as (local) \textit{upsampling} in the Fast Fourier Transform (FFT) domain. However, FFT of natural images exhibits high dynamic range and lacks local correlations. Therefore, to train CNNs we design a framework to perform FFT upsampling in feature space using deformable convolutions. Such design allows our framework to generalize to unseen images, and synthesize textures in a single pass. Extensive evaluations confirm that our method achieves state-of-the-art performance both quantitatively and qualitatively.
https://weibo.com/1402400261/JtOeuovZQ
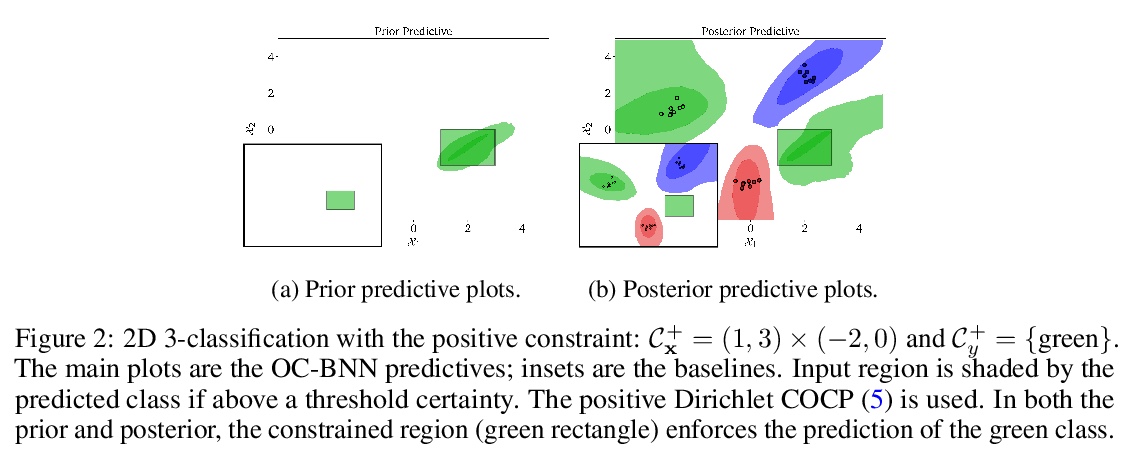
5、[LG] **Incorporating Interpretable Output Constraints in Bayesian Neural Networks
W Yang, L Lorch, M A. Graule, H Lakkaraju, F Doshi-Velez
[Harvard University & ETH Zürich]
在贝叶斯神经网络中加入可解释输出约束。提出OC-BNN,以输出约束的形式将可解释和直观的先验知识合并到贝叶斯神经网络中。通过一系列低维仿真和现实世界应用的现实约束,验证了OC-BNN在真实数据集上的有效性,在满足特定约束条件的同时,保持了BNN的理想特性。**
Domains where supervised models are deployed often come with task-specific constraints, such as prior expert knowledge on the ground-truth function, or desiderata like safety and fairness. We introduce a novel probabilistic framework for reasoning with such constraints and formulate a prior that enables us to effectively incorporate them into Bayesian neural networks (BNNs), including a variant that can be amortized over tasks. The resulting Output-Constrained BNN (OC-BNN) is fully consistent with the Bayesian framework for uncertainty quantification and is amenable to black-box inference. Unlike typical BNN inference in uninterpretable parameter space, OC-BNNs widen the range of functional knowledge that can be incorporated, especially for model users without expertise in machine learning. We demonstrate the efficacy of OC-BNNs on real-world datasets, spanning multiple domains such as healthcare, criminal justice, and credit scoring.
https://weibo.com/1402400261/JtOjkyjuY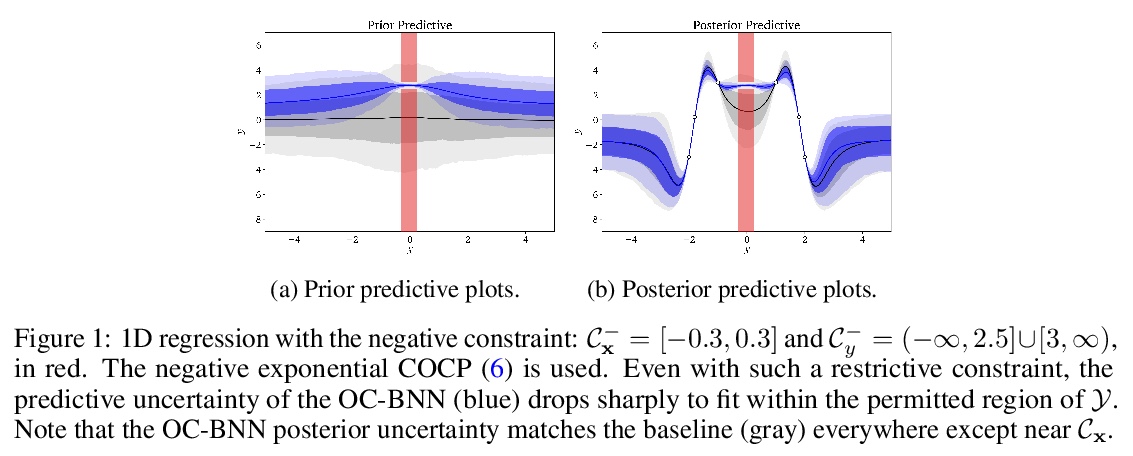
其他几篇值得关注的论文:
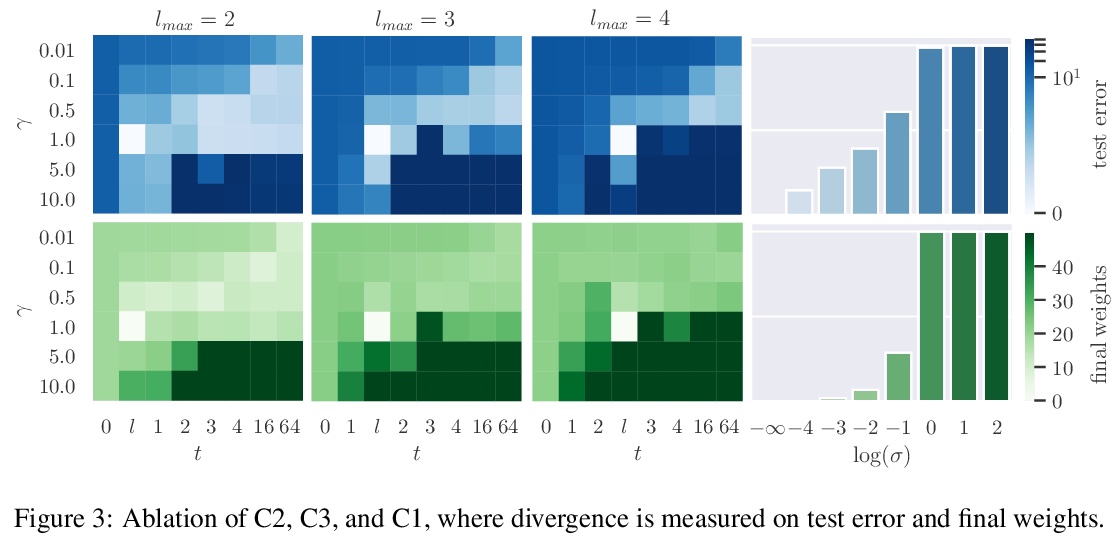
[LG] Can the Brain Do Backpropagation? —- Exact Implementation of Backpropagation in Predictive Coding Networks
大脑能反向传播吗? ——预测编码网络中反向传播的精确实现
Y Song, T Lukasiewicz, Z Xu, R Bogacz
[University of Oxford & Hebei University of Technology]
https://weibo.com/1402400261/JtOs1BncR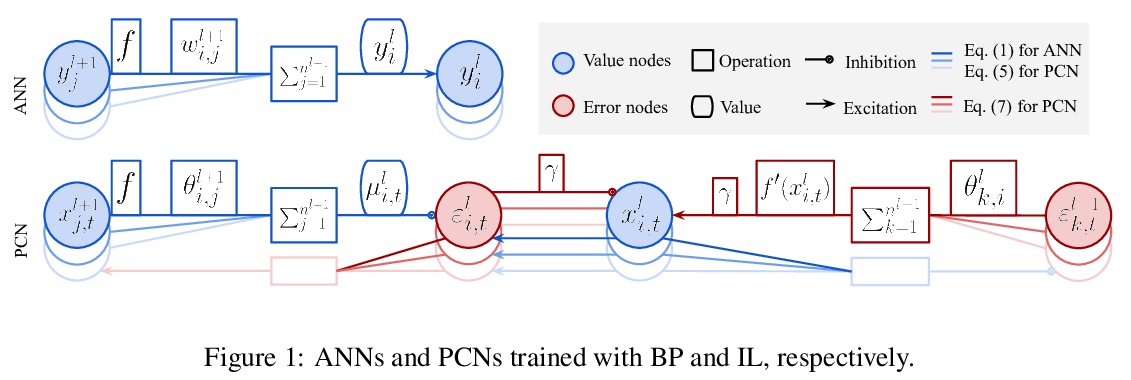


若有收获,就点个赞吧
0 人点赞
