- 1、[CL] Reliability Testing for Natural Language Processing Systems
- 2、[CV] Computer-Aided Design as Language
- 3、[CV] Function4D: Real-time Human Volumetric Capture from Very Sparse Consumer RGBD Sensors
- 4、[CL] Keep Learning: Self-supervised Meta-learning for Learning from Inference
- 5、[CV] 4DComplete: Non-Rigid Motion Estimation Beyond the Observable Surface
- [LG] On Lottery Tickets and Minimal Task Representations in Deep Reinforcement Learning
- [CL] Scaling End-to-End Models for Large-Scale Multilingual ASR
- [CV] Learned Spatial Representations for Few-shot Talking-Head Synthesis
- [CV] SRDiff: Single Image Super-Resolution with Diffusion Probabilistic Models
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CL] Reliability Testing for Natural Language Processing Systems
S Tan, S Joty, K Baxter, A Taeihagh, G A. Bennett, M Kan
[Salesforce Research & National University of Singapore]
自然语言处理系统的可靠性测试。部署NLP系统前,公平性、鲁棒性和透明度的问题是最重要的。这些问题的核心是可靠性问题。严格的测试对于确保程序在真实世界条件下(可靠性)使用时能按预期工作(功能性)是至关重要的。NLP系统能否可靠地公平对待不同人群,并在多样化和嘈杂的环境中正确运作?为解决该问题,本文论证了可靠性测试的必要性,并将其与现有的改善可追究性的工作结合起来,通过开发可靠性测试框架,展示了如何为这一目标重新设计对抗式攻击。可靠性测试——尤其是在跨学科合作推动下——将使严格的、有针对性的测试成为可能,并有助于行业标准的制定和执行。
Questions of fairness, robustness, and transparency are paramount to address before deploying NLP systems. Central to these concerns is the question of reliability: Can NLP systems reliably treat different demographics fairly and function correctly in diverse and noisy environments? To address this, we argue for the need for reliability testing and contextualize it among existing work on improving accountability. We show how adversarial attacks can be reframed for this goal, via a framework for developing reliability tests. We argue that reliability testing — with an emphasis on interdisciplinary collaboration — will enable rigorous and targeted testing, and aid in the enactment and enforcement of industry standards.
https://weibo.com/1402400261/KeBFdtUAv
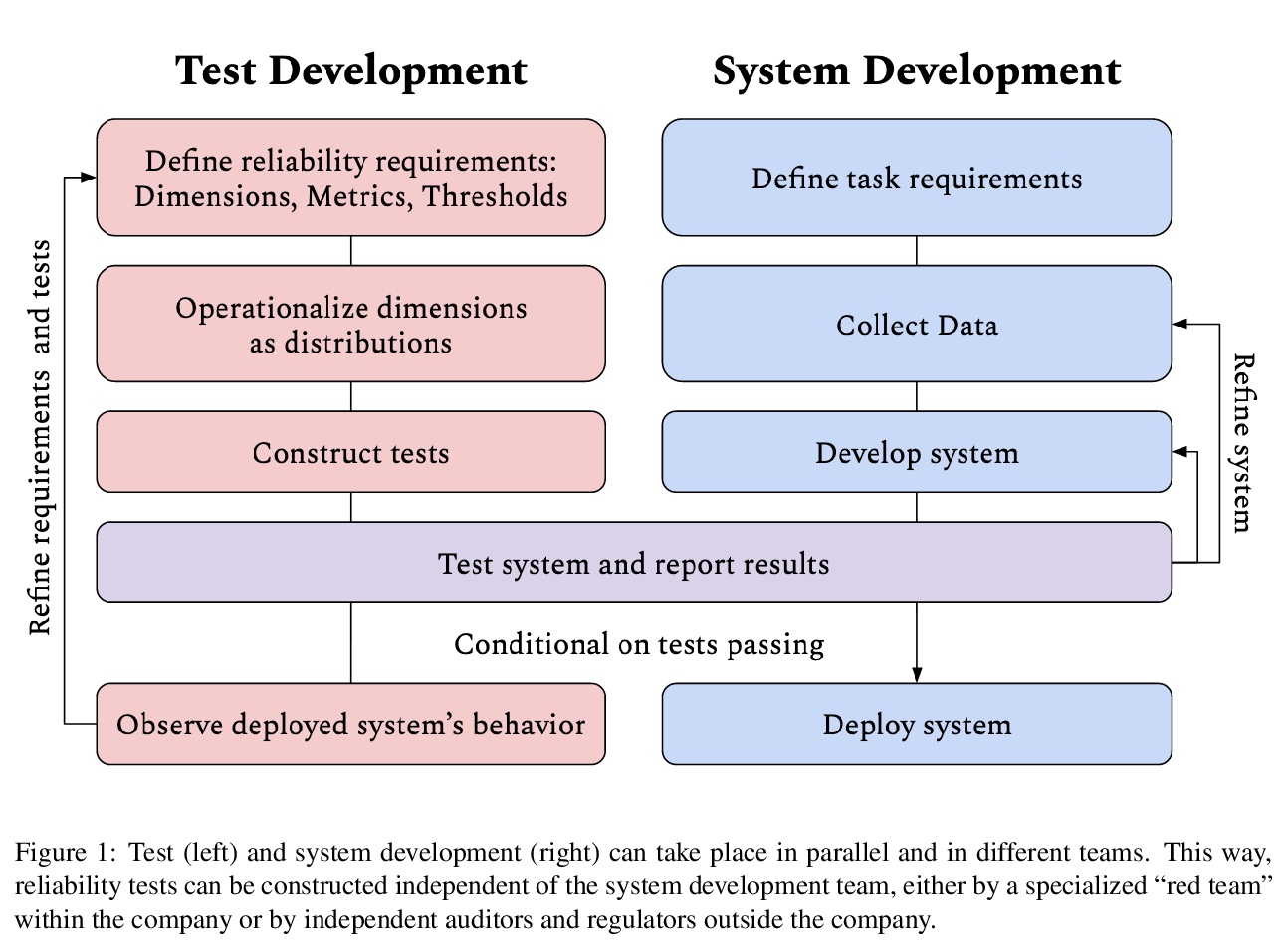

2、[CV] Computer-Aided Design as Language
Y Ganin, S Bartunov, Y Li, E Keller, S Saliceti
[DeepMind & Onshape]
计算机辅助设计(CAD)的2D草图自动生成。计算机辅助设计(CAD)程序被用于制造从汽车到机器人再到发电厂的一切模型,这些程序很复杂,需要多年的培训和经验才能掌握。所有CAD模型中,特别难以制作的部分,是高度结构化的2D草图,也是每个3D结构的核心。本文提出一种能自动生成这种草图的机器学习模型,将通用语言建模技术与数据序列化协议结合,以有效解决复杂结构化对象的生成问题,有足够的灵活性来适应领域的复杂性,并且在无条件合成和图像到草图的转换中表现良好。该方法为开发智能工具铺平了道路,这些工具将帮助工程师以更少的努力创造更好的设计。
Computer-Aided Design (CAD) applications are used in manufacturing to model everything from coffee mugs to sports cars. These programs are complex and require years of training and experience tomaster. A component of all CAD models particularly difficult to make are the highly structured 2D sketches that lie at the heart of every 3D construction. In this work, we propose a machine learning model capable of automatically generating such sketches. Through this, we pave the way for developing intelligent tools that would help engineers create better designs with less effort. Our method is a combination of a general-purpose language modeling technique alongside an off-the-shelf data serialization protocol. We show that our approach has enough flexibility to accommodate the complexity of the domain and performs well for both unconditional synthesis and image-to-sketch translation.
https://weibo.com/1402400261/KeBNPbMtH




3、[CV] Function4D: Real-time Human Volumetric Capture from Very Sparse Consumer RGBD Sensors
T Yu, Z Zheng, K Guo, P Liu, Q Dai, Y Liu
[Tsinghua University & Google & Chinese Academy of Sciences]
Function4D: 用非常稀疏的消费级RGBD传感器实时捕捉人体数据。人体捕捉是计算机视觉和计算机图形学领域的一个长期课题。尽管使用复杂的离线系统可以获得高质量的结果,但对复杂场景下的实时人体捕捉,尤其是使用轻量级的设置,仍然具有挑战性。本文中提出一种结合时体融合和深度隐函数的人体捕捉方法。为实现高质量和时间连续重建,提出了动态滑动融合,将相邻的深度观测值与拓扑结构一致性融合起来。为生成详细和完整的表面,为RGBD输入提出了保留细节的深度隐函数,不仅可保留深度输入的几何细节,还可生成更合理的纹理结果。实验表明,该方法在视图稀疏度、泛化能力、重建质量和运行时间效率方面都优于现有方法。
https://weibo.com/1402400261/KeBTExIEV




4、[CL] Keep Learning: Self-supervised Meta-learning for Learning from Inference
A Kedia, S C Chinthakindi
[Samsung Research]
保持学习:从推理中学习的自监督元学习。机器学习算法一种常见方法,是在下游任务中进行微调之前,在大量无标签数据上进行自监督学习,以进一步提高性能。动态评价是一种新的语言建模方法,在推理过程中用零散给出的真实标签进一步微调训练过的模型,使性能得到大幅提高。但这种方法不容易扩展到分类任务中,因为在推理过程中没有真实标签。本文通过利用自训练和反向传播模型自身的类平衡预测(伪标签)损失,自适应元学习中的Reptile算法,结合对预训练权重的归纳偏见来提高泛化性,来解决这个问题。该方法提高了BERT、Electra和ResNet-50等标准骨干在各种任务上的性能,无需对基础模型做任何改变。所提出的方法优于之前的方法,能在任何分类器模型的推理过程中进行自监督微调,以更好地适应目标域,可以很容易地适用于任何模型,并且在在线和迁移学习场景中也是有效的。
A common approach in many machine learning algorithms involves self-supervised learning on large unlabeled data before fine-tuning on downstream tasks to further improve performance. A new approach for language modelling, called dynamic evaluation, further fine-tunes a trained model during inference using trivially-present ground-truth labels, giving a large improvement in performance. However, this approach does not easily extend to classification tasks, where ground-truth labels are absent during inference. We propose to solve this issue by utilizing self-training and back-propagating the loss from the model’s own class-balanced predictions (pseudo-labels), adapting the Reptile algorithm from meta-learning, combined with an inductive bias towards pre-trained weights to improve generalization. Our method improves the performance of standard backbones such as BERT, Electra, and ResNet-50 on a wide variety of tasks, such as question answering on SQuAD and NewsQA, benchmark task SuperGLUE, conversation response selection on Ubuntu Dialog corpus v2.0, as well as image classification on MNIST and ImageNet without any changes to the underlying models. Our proposed method outperforms previous approaches, enables self-supervised finetuning during inference of any classifier model to better adapt to target domains, can be easily adapted to any model, and is also effective in online and transfer-learning settings.
https://weibo.com/1402400261/KeC1QtGVV


5、[CV] 4DComplete: Non-Rigid Motion Estimation Beyond the Observable Surface
Y Li, H Takehara, T Taketomi, B Zheng, M Nießner
[The University of Tokyo & Huawei & Technical University Munich]
4DComplete: 超越可观察表面的非刚性运动估计。用测距传感器跟踪非刚性变形有许多应用,包括计算机视觉、AR/VR和机器人技术。然而,由于遮挡和距离传感器的物理限制,现有方法只处理可见表面,从而导致运动场的不连续和不完整。本文提出4DComplete,一种新的数据驱动方法,可以估计未观察到的几何体的非刚性运动。4DComplete将部分形状和运动观测作为输入,提取4D时间空间嵌入,用稀疏全卷积网络联合推断出缺失的几何体和运动场。构建了大规模的非刚性的4D数据集DeformingThings4D,用于训练和基准测试。该数据集由1,972个动画序列和122,365帧组成,横跨31个不同的动物或人形类别,具有密集的4D标注。
Tracking non-rigidly deforming scenes using range sensors has numerous applications including computer vision, AR/VR, and robotics. However, due to occlusions and physical limitations of range sensors, existing methods only handle the visible surface, thus causing discontinuities and incompleteness in the motion field. To this end, we introduce 4DComplete, a novel data-driven approach that estimates the non-rigid motion for the unobserved geometry. 4DComplete takes as input a partial shape and motion observation, extracts 4D time-space embedding, and jointly infers the missing geometry and motion field using a sparse fully-convolutional network. For network training, we constructed a large-scale synthetic dataset called DeformingThings4D, which consists of 1,972 animation sequences spanning 31 different animals or humanoid categories with dense 4D annotation. Experiments show that 4DComplete 1) reconstructs high-resolution volumetric shape and motion field from a partial observation, 2) learns an entangled 4D feature representation that benefits both shape and motion estimation, 3) yields more accurate and natural deformation than classic non-rigid priors such as As-RigidAs-Possible (ARAP) deformation, and 4) generalizes well to unseen objects in real-world sequences.
https://weibo.com/1402400261/KeCb7i8cN




另外几篇值得关注的论文:
[LG] On Lottery Tickets and Minimal Task Representations in Deep Reinforcement Learning
深度强化学习中的彩票和最小任务表示
M A Vischer, R T Lange, H Sprekeler
[Technical University Berlin]
https://weibo.com/1402400261/KeCiOvdbs




[CL] Scaling End-to-End Models for Large-Scale Multilingual ASR
面向大规模多语言自动语音识别的端到端模型扩展
B Li, R Pang, T N. Sainath, A Gulati, Y Zhang, J Qin, P Haghani, W. R Huang, M Ma
[Google LLC]
https://weibo.com/1402400261/KeCksoCHB

[CV] Learned Spatial Representations for Few-shot Talking-Head Synthesis
面向少样本说话人头部合成的空间表示学习
M Meshry, S Suri, L S. Davis, A Shrivastava
[University of Maryland]
https://weibo.com/1402400261/KeCokl1z1




[CV] SRDiff: Single Image Super-Resolution with Diffusion Probabilistic Models
SRDiff:基于扩散概率模型的单图像超分辨率
H Li, Y Yang, M Chang, H Feng, Z Xu, Q Li, Y Chen
[Zhejiang University]
https://weibo.com/1402400261/KeCqsbMGN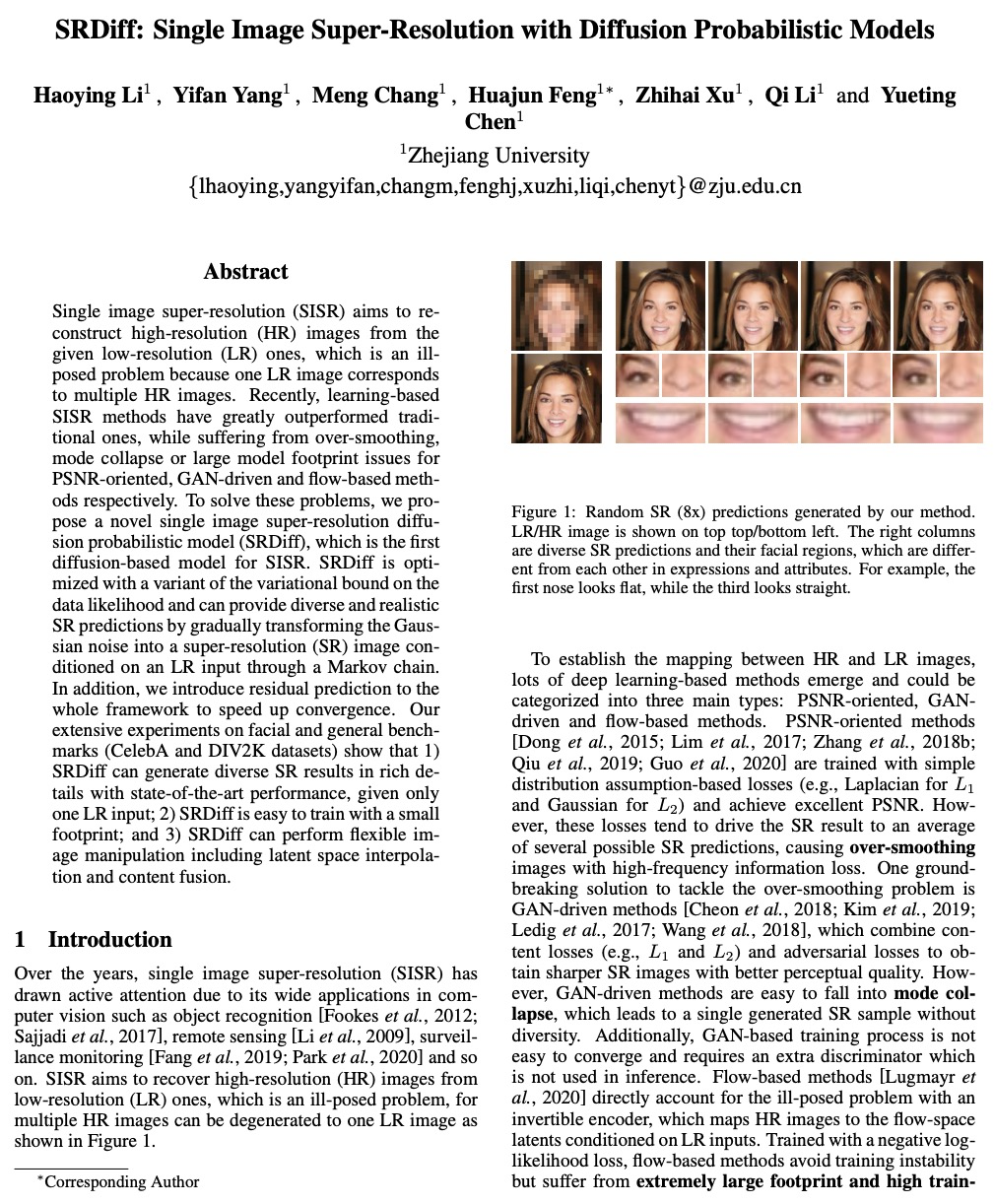




若有收获,就点个赞吧
0 人点赞
