- 1、[CV] High-Performance Large-Scale Image Recognition Without Normalization
- 2、[CV] Neural Re-rendering for Full-frame Video Stabilization
- 3、[CV] Unsupervised Semantic Segmentation by Contrasting Object Mask Proposals
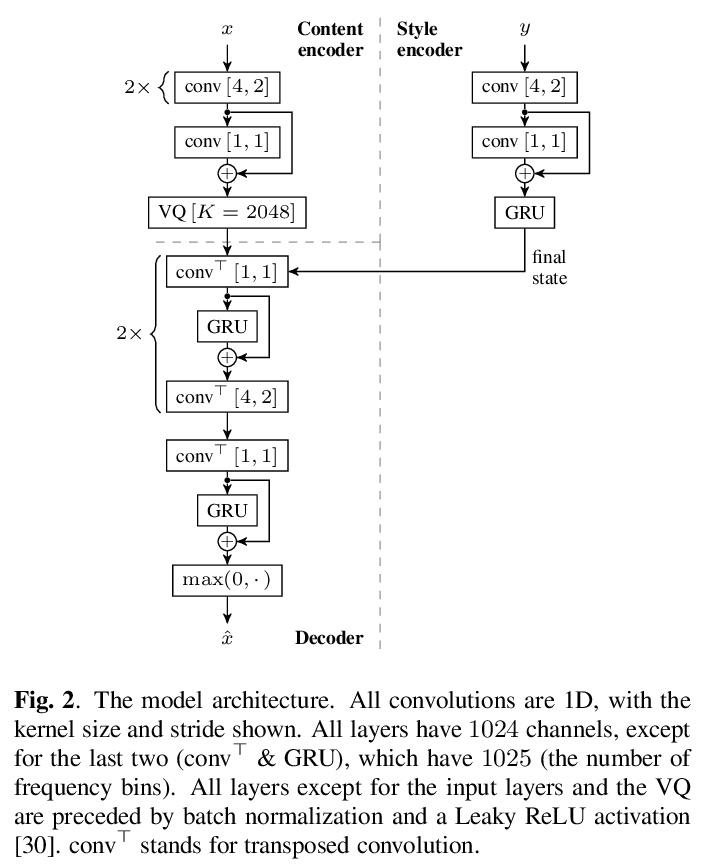
- 4、[LG] Self-Supervised VQ-VAE For One-Shot Music Style Transfer
- 5、[CV] A-NeRF: Surface-free Human 3D Pose Refinement via Neural Rendering
- [CV] SWAGAN: A Style-based Wavelet-driven Generative Model
- [CV] Less is More: ClipBERT for Video-and-Language Learning via Sparse Sampling
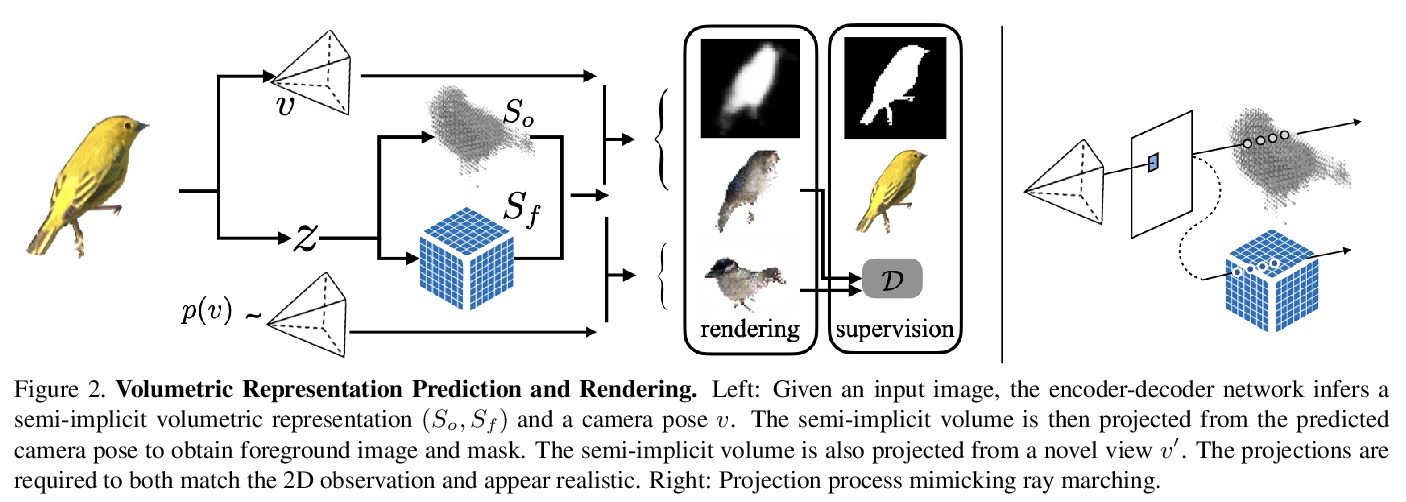
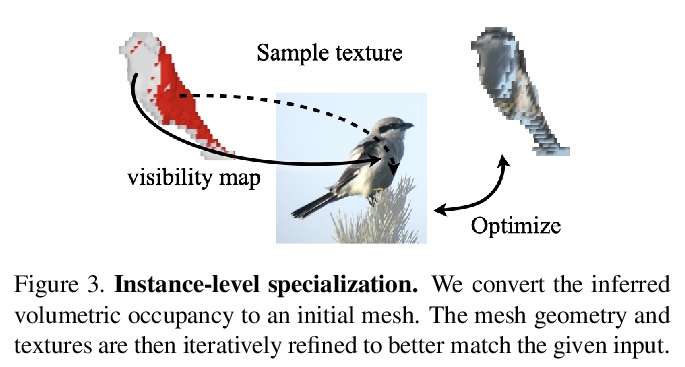
- [CV] Shelf-Supervised Mesh Prediction in the Wild
- [CV] Deep Photo Scan: Semi-supervised learning for dealing with the real-world degradation in smartphone photo scanning
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] High-Performance Large-Scale Image Recognition Without Normalization
A Brock, S De, S L. Smith, K Simonyan
[DeepMind]
无归一化层的高性能大规模图像识别。开发了一种自适应梯度剪裁(Adaptive Gradient Clipping)技术,克服了批量归一化源于对批量大小和实例相互作用的依赖而产生的不稳定性,设计了一类显著改进的无归一化ResNets。在没有归一化层的情况下训练的图像识别模型,在大规模数据集上不仅可达到批量归一化模型的最好分类精度,还可大幅超过它们,训练速度也更快。小型模型与ImageNet上EfficientNet-B7的测试精度相当,训练速度快了8.7倍,最大的模型达到了86.5%的新的最先进的top-1精度。在对3亿张标签图像进行大规模预训练后,在ImageNet上进行微调时,Normalizer-Free模型的性能明显优于批量归一化模型,最佳模型获得了89.2%的精度。
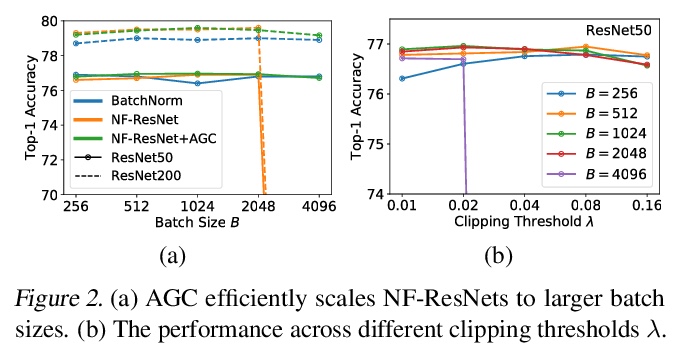
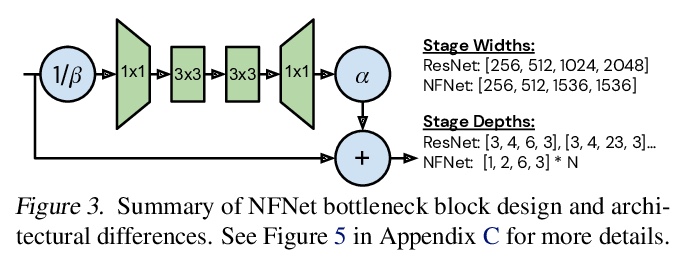
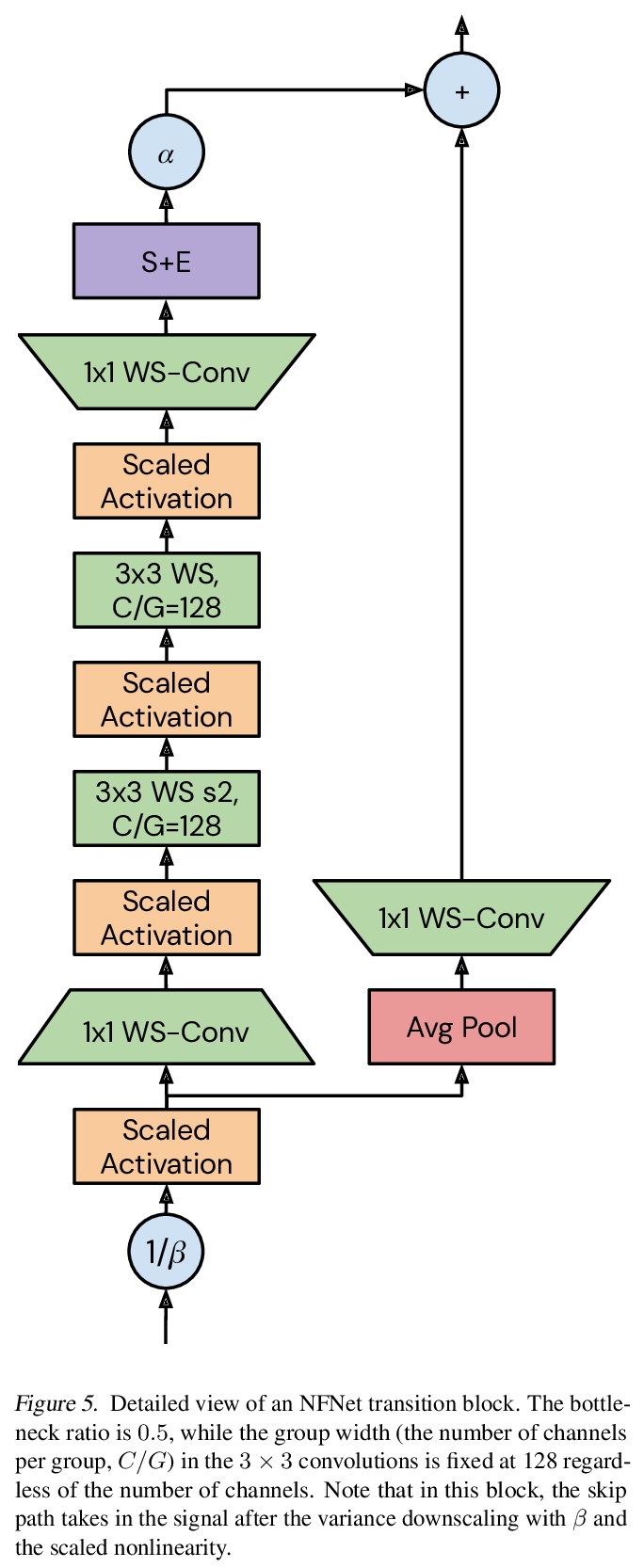
Batch normalization is a key component of most image classification models, but it has many undesirable properties stemming from its dependence on the batch size and interactions between examples. Although recent work has succeeded in training deep ResNets without normalization layers, these models do not match the test accuracies of the best batch-normalized networks, and are often unstable for large learning rates or strong data augmentations. In this work, we develop an adaptive gradient clipping technique which overcomes these instabilities, and design a significantly improved class of Normalizer-Free ResNets. Our smaller models match the test accuracy of an EfficientNet-B7 on ImageNet while being up to 8.7x faster to train, and our largest models attain a new state-of-the-art top-1 accuracy of 86.5%. In addition, Normalizer-Free models attain significantly better performance than their batch-normalized counterparts when finetuning on ImageNet after large-scale pre-training on a dataset of 300 million labeled images, with our best models obtaining an accuracy of 89.2%. Our code is available at > this https URL deepmind-research/tree/master/nfnets
https://weibo.com/1402400261/K1Hb4hPxN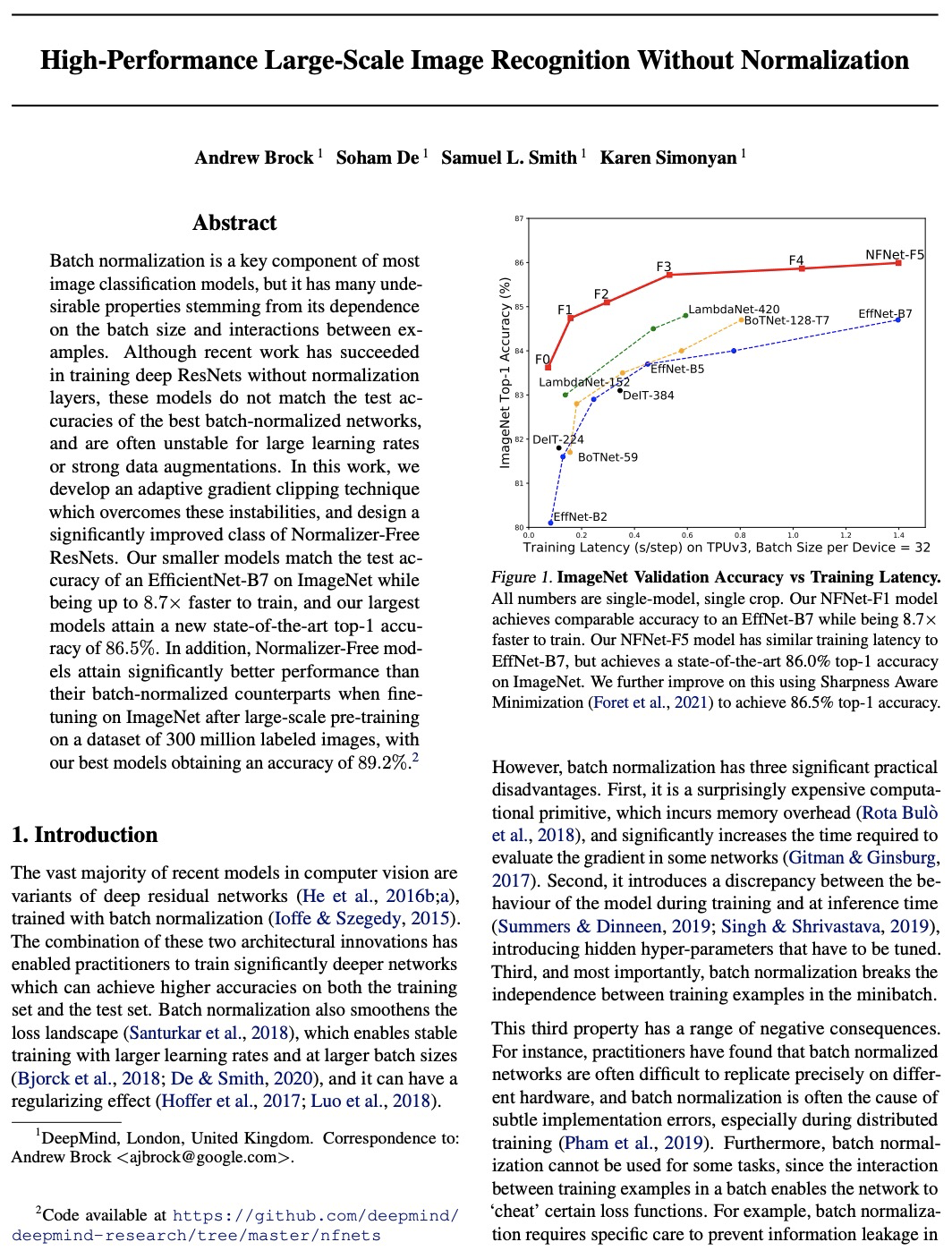
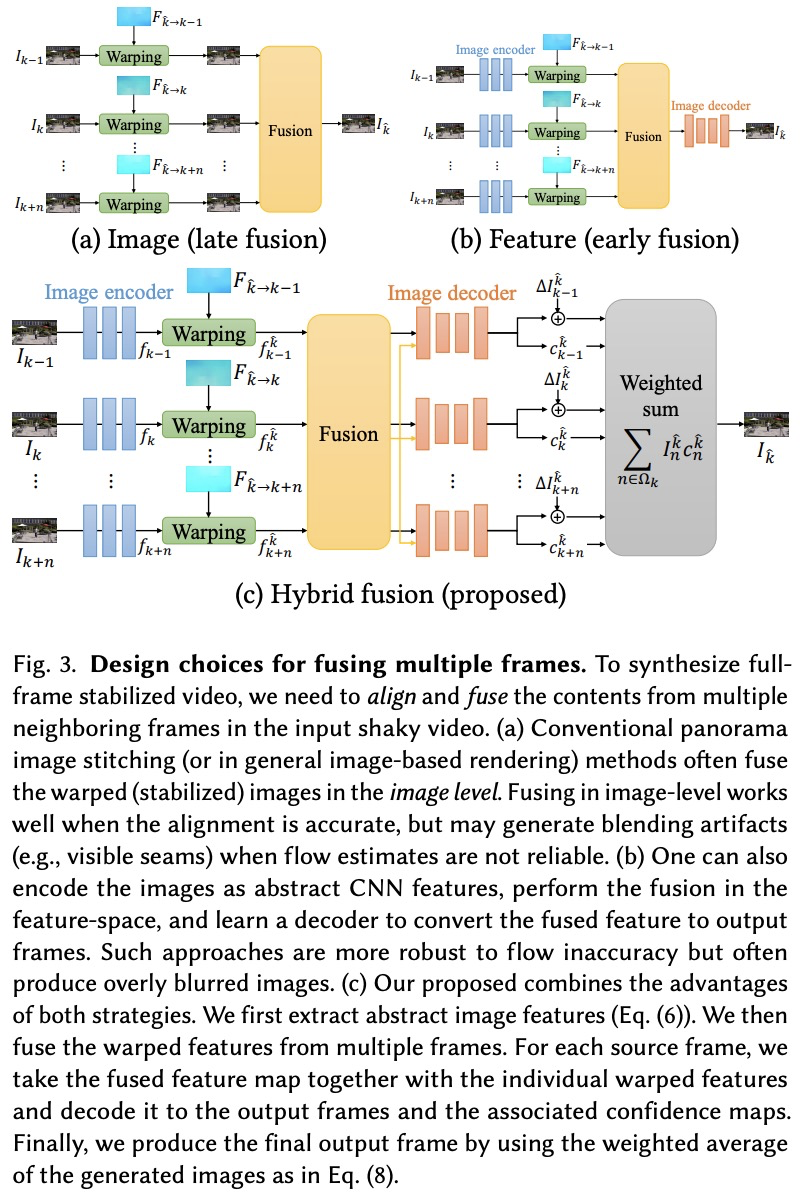
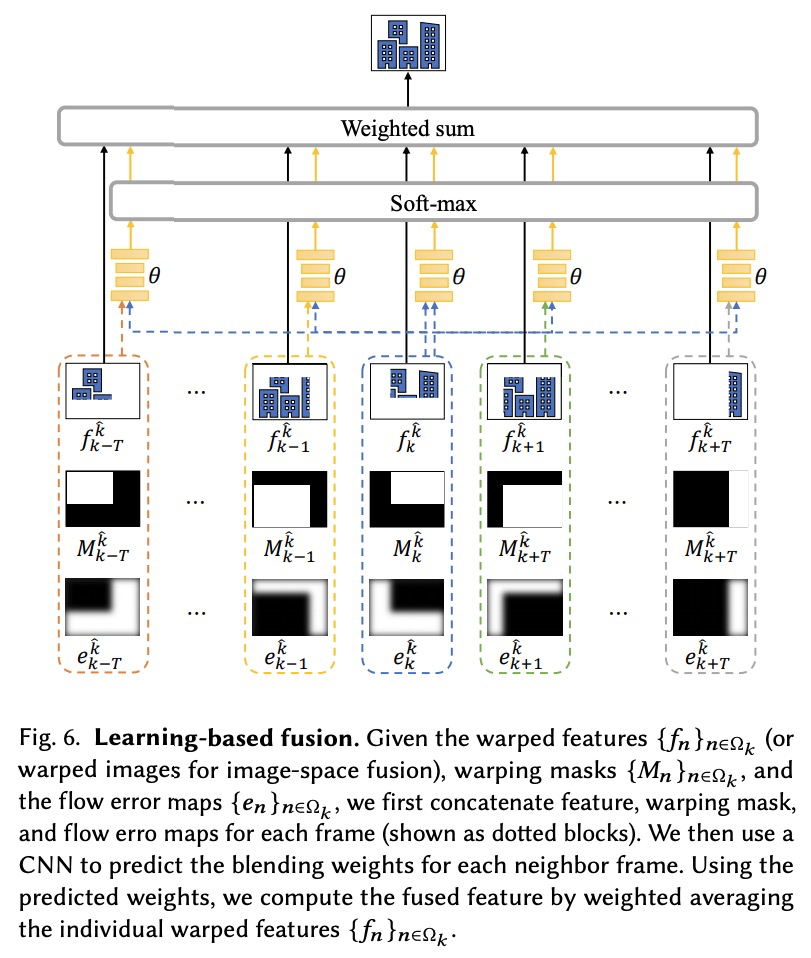
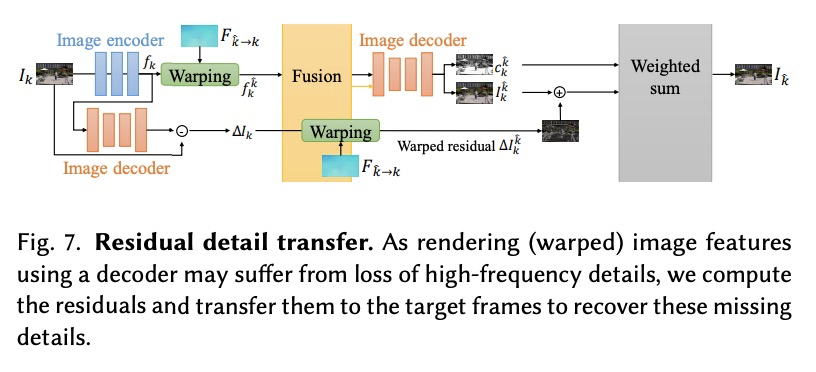
2、[CV] Neural Re-rendering for Full-frame Video Stabilization
Y Liu, W Lai, M Yang, Y Chuang, J Huang
[Taiwan University & Google & Virginia Tech]
面向全画幅视频稳定的神经重渲染技术。提出了一种新的全画幅视频稳定方法,核心思想是开发一种基于学习的融合方法,以稳健的方式聚合来自多个相邻帧的扭曲内容。将神经渲染技术应用于视频稳定,以缓解对流不准确的敏感性问题。探索了几种设计选择,包括早/晚期融合、启发式/学习式融合权重和残差细节迁移等,提供了系统的消解研究来验证每个单独组件的贡献。在两个公共基准数据集上的实验结果表明,该方法与最先进的视频稳定算法相比具有优势。
Existing video stabilization methods either require aggressive cropping of frame boundaries or generate distortion artifacts on the stabilized frames. In this work, we present an algorithm for full-frame video stabilization by first estimating dense warp fields. Full-frame stabilized frames can then be synthesized by fusing warped contents from neighboring frames. The core technical novelty lies in our learning-based hybrid-space fusion that alleviates artifacts caused by optical flow inaccuracy and fast-moving objects. We validate the effectiveness of our method on the NUS and selfie video datasets. Extensive experiment results demonstrate the merits of our approach over prior video stabilization methods.
https://weibo.com/1402400261/K1Hi2B5g6

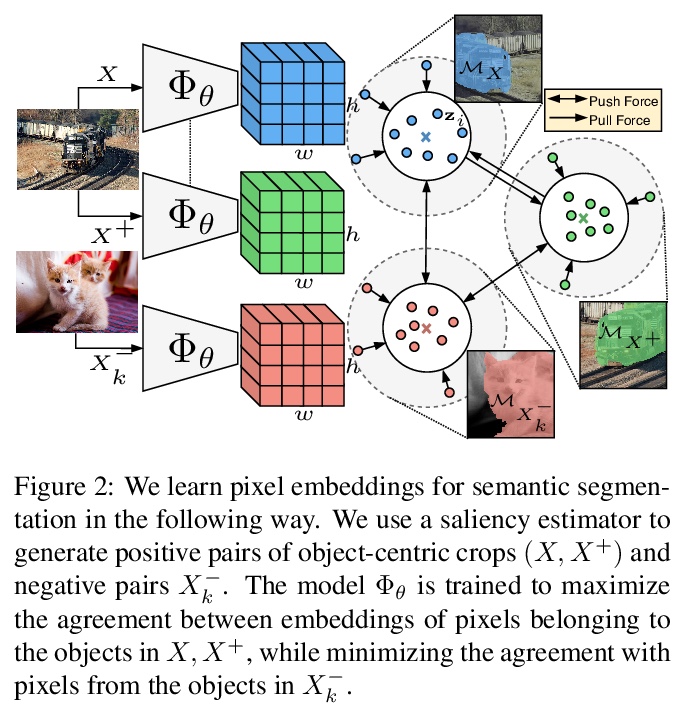
3、[CV] Unsupervised Semantic Segmentation by Contrasting Object Mask Proposals
W V Gansbeke, S Vandenhende, S Georgoulis, L V Gool
[KU Leuven/ESAT-PSI & ETH Zurich/CVL]
基于对比目标掩码候选域的无监督语义分割。提出了一个解决无监督语义分割的通用两步框架,在对比优化目标中采用预定的先验来学习像素嵌入,论证了表示目标及其部件信息的先验的重要性。所提出的方法与现有的工作相比具有明显优势,学到的像素嵌入可直接用K-Means进行语义组聚类,可扩展到其他密集的预测任务,还可作为语义分割任务的有效无监督预训练。
Being able to learn dense semantic representations of images without supervision is an important problem in computer vision. However, despite its significance, this problem remains rather unexplored, with a few exceptions that considered unsupervised semantic segmentation on small-scale datasets with a narrow visual domain. In this paper, we make a first attempt to tackle the problem on datasets that have been traditionally utilized for the supervised case. To achieve this, we introduce a novel two-step framework that adopts a predetermined prior in a contrastive optimization objective to learn pixel embeddings. This marks a large deviation from existing works that relied on proxy tasks or end-to-end clustering. Additionally, we argue about the importance of having a prior that contains information about objects, or their parts, and discuss several possibilities to obtain such a prior in an unsupervised manner.Extensive experimental evaluation shows that the proposed method comes with key advantages over existing works. First, the learned pixel embeddings can be directly clustered in semantic groups using K-Means. Second, the method can serve as an effective unsupervised pre-training for the semantic segmentation task. In particular, when fine-tuning the learned representations using just 1% of labeled examples on PASCAL, we outperform supervised ImageNet pre-training by 7.1% mIoU. The code is available at > this https URL.
https://weibo.com/1402400261/K1Hmb8K1H


4、[LG] Self-Supervised VQ-VAE For One-Shot Music Style Transfer
O Cífka, A Ozerov, U Şimşekli, G Richard
[Telecom Paris & InterDigital R&D & Inria/ENS]
基于自监督VQ-VAE的单样本音乐风格迁移。提出用于单样本乐器音色迁移的神经模型,基于向量量化变分自编码器(VQ-VAE)扩展,以自监督方式进行学习,无需人工标注,通过简单的自监督学习策略,获得音色和音高的解耦表示。在一个数据集上训练和测试该模型,每个录音都包含一个单一的,可能是多声部的乐器。使用一组客观指标对该方法进行了评价,表明其性能优于选定的基线。
Neural style transfer, allowing to apply the artistic style of one image to another, has become one of the most widely showcased computer vision applications shortly after its introduction. In contrast, related tasks in the music audio domain remained, until recently, largely untackled. While several style conversion methods tailored to musical signals have been proposed, most lack the ‘one-shot’ capability of classical image style transfer algorithms. On the other hand, the results of existing one-shot audio style transfer methods on musical inputs are not as compelling. In this work, we are specifically interested in the problem of one-shot timbre transfer. We present a novel method for this task, based on an extension of the vector-quantized variational autoencoder (VQ-VAE), along with a simple self-supervised learning strategy designed to obtain disentangled representations of timbre and pitch. We evaluate the method using a set of objective metrics and show that it is able to outperform selected baselines.
https://weibo.com/1402400261/K1HrRyles
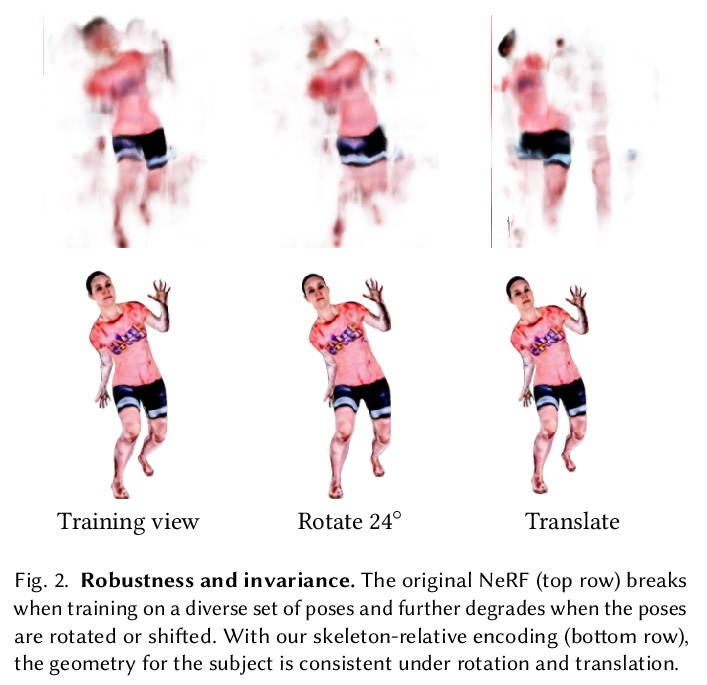
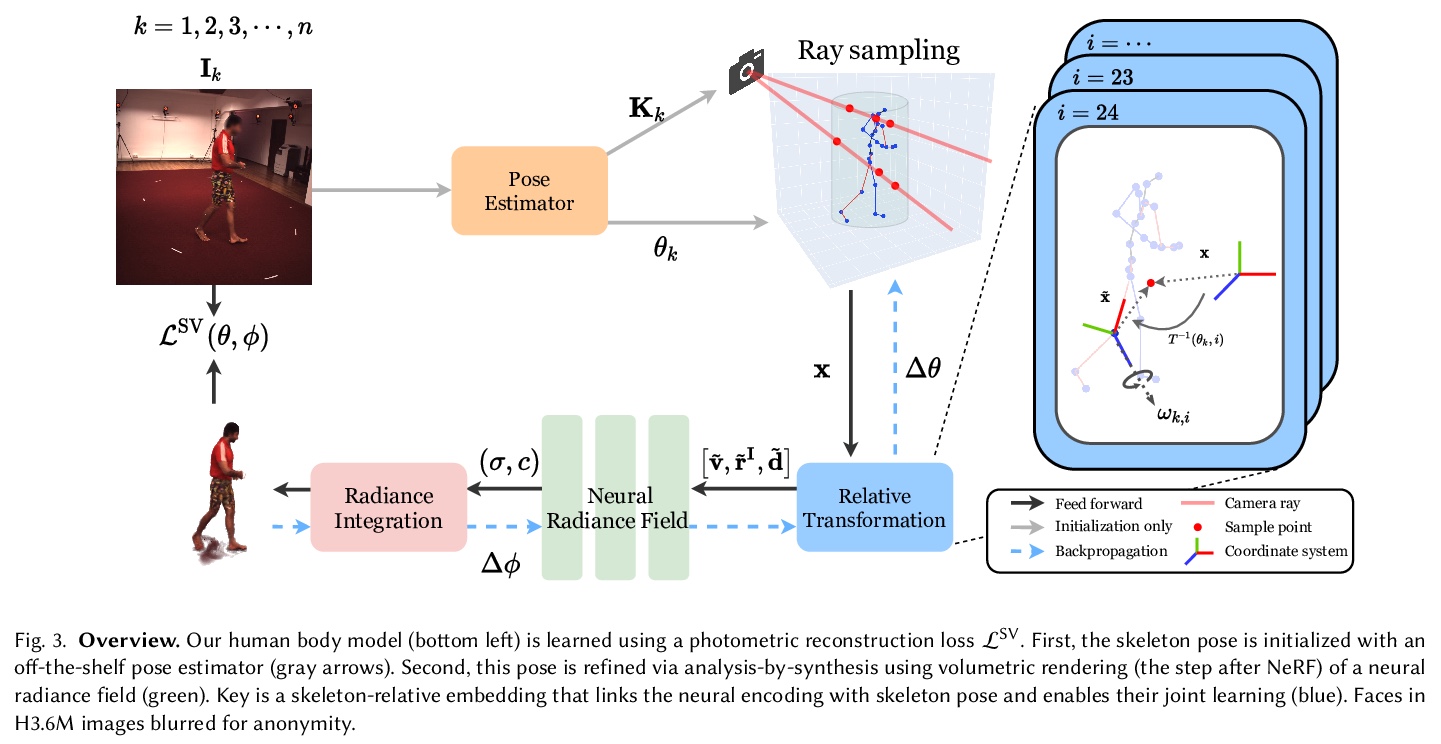
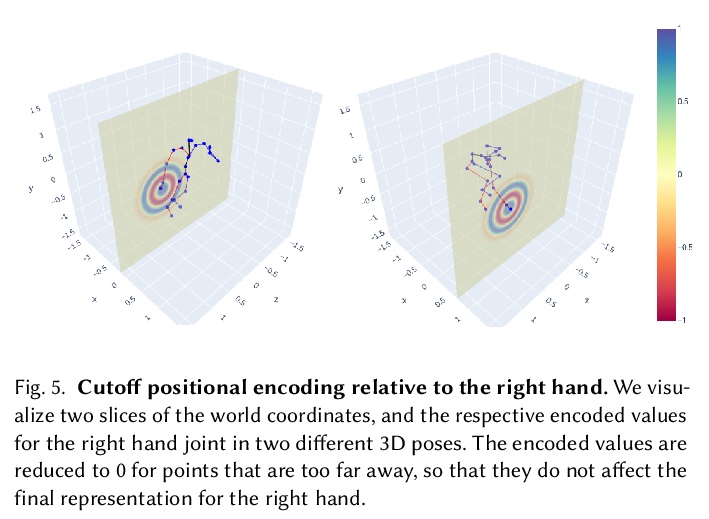
5、[CV] A-NeRF: Surface-free Human 3D Pose Refinement via Neural Rendering
S Su, F Yu, M Zollhoefer, H Rhodin
[University of British Columbia & Facebook Reality Labs Research]
A-NeRF:基于神经渲染的无表面人体3D姿态细化。提出了一种全自动方法,用于估计体演员模型,结合了神经辐射场与关节骨架表示的优势,从单目或多视角视频中联合完善骨架姿态,以自我监督方式联合学习体身体模型和初始3D骨骼姿态估计的姿态细化。提出的骨架嵌入作为一个共同的参考,链接跨时间的约束,从而减少了所需的相机视图的数量,从传统的几十个校准相机,下降到单一未校准相机。采用一个现成的模型的输出,预测3D骨架姿势。然后从头开始学习体形态和外观,同时共同完善初始姿态估计。
While deep learning has reshaped the classical motion capture pipeline, generative, analysis-by-synthesis elements are still in use to recover fine details if a high-quality 3D model of the user is available. Unfortunately, obtaining such a model for every user a priori is challenging, time-consuming, and limits the application scenarios. We propose a novel test-time optimization approach for monocular motion capture that learns a volumetric body model of the user in a self-supervised manner. To this end, our approach combines the advantages of neural radiance fields with an articulated skeleton representation. Our proposed skeleton embedding serves as a common reference that links constraints across time, thereby reducing the number of required camera views from traditionally dozens of calibrated cameras, down to a single uncalibrated one. As a starting point, we employ the output of an off-the-shelf model that predicts the 3D skeleton pose. The volumetric body shape and appearance is then learned from scratch, while jointly refining the initial pose estimate. Our approach is self-supervised and does not require any additional ground truth labels for appearance, pose, or 3D shape. We demonstrate that our novel combination of a discriminative pose estimation technique with surface-free analysis-by-synthesis outperforms purely discriminative monocular pose estimation approaches and generalizes well to multiple views.
https://weibo.com/1402400261/K1HBd2b92

另外几篇值得关注的论文:
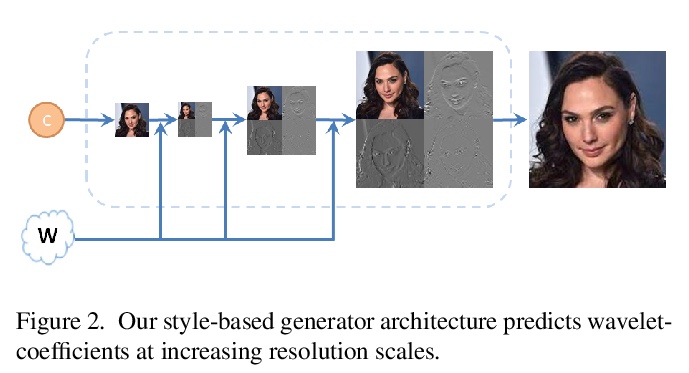
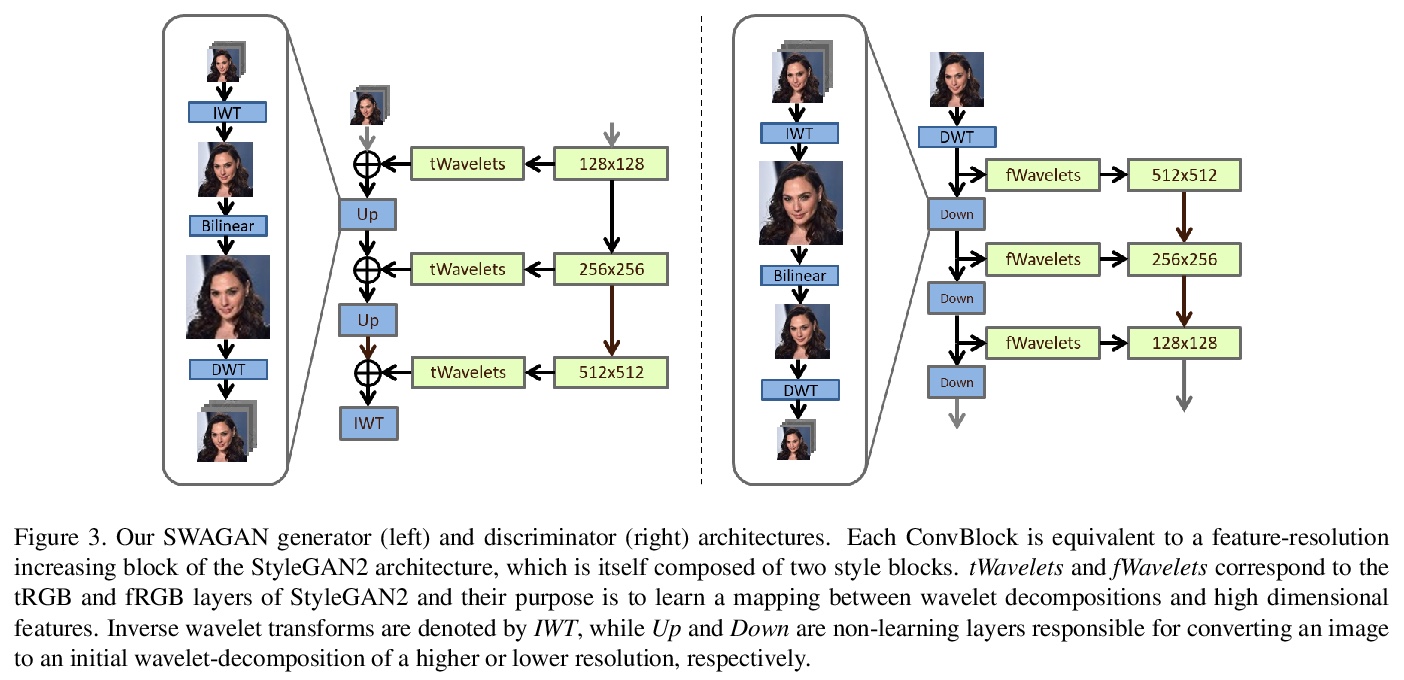
[CV] SWAGAN: A Style-based Wavelet-driven Generative Model
SWAGAN:基于风格的小波驱动生成模型
R Gal, D Cohen, A Bermano, D Cohen-Or
[Tel-Aviv University]
https://weibo.com/1402400261/K1HFJ9GBb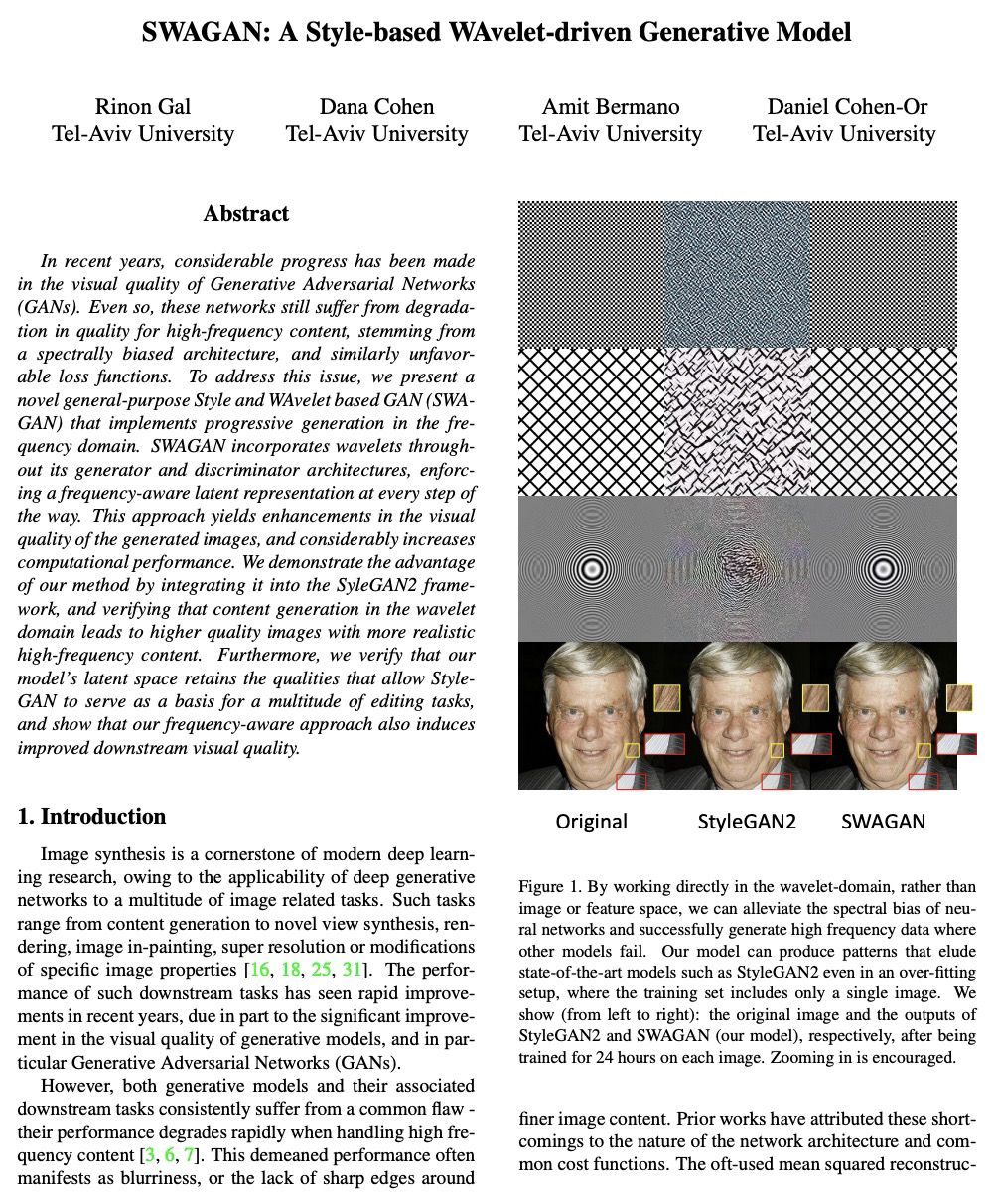

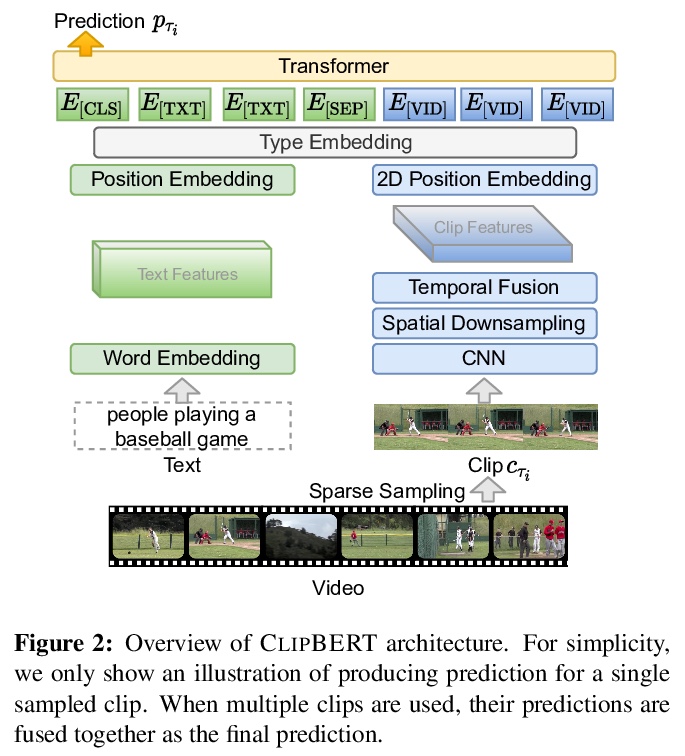
[CV] Less is More: ClipBERT for Video-and-Language Learning via Sparse Sampling
少即是多:基于稀疏采样的ClipBERT视频-语言学习
J Lei, L Li, L Zhou, Z Gan, T L. Berg, M Bansal, J Liu
[UNC Chapel Hill & Microsoft Dynamics 365 AI Research]
https://weibo.com/1402400261/K1HHFuZvT
[CV] Shelf-Supervised Mesh Prediction in the Wild
实际场景的shelf监督网格预测
Y Ye, S Tulsiani, A Gupta
[CMU & Facebook AI Research]
https://weibo.com/1402400261/K1HKyz2Dd

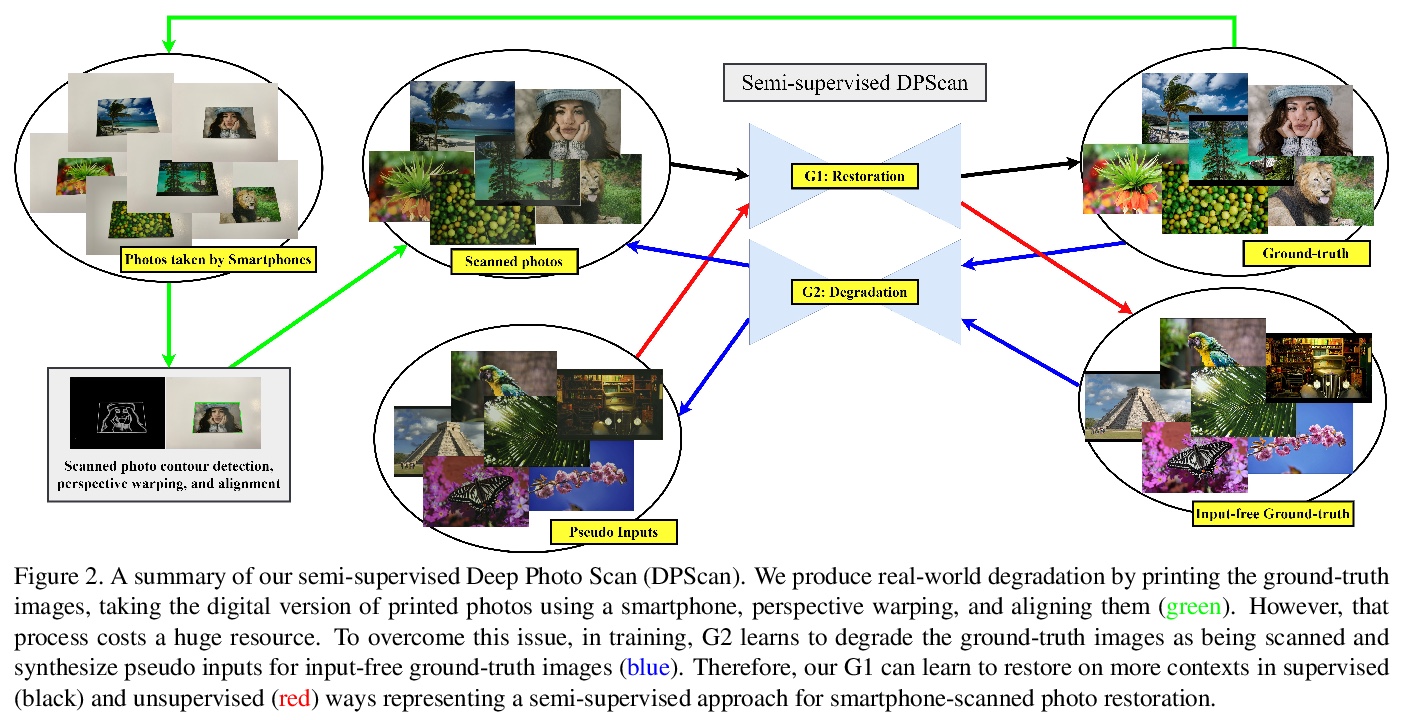
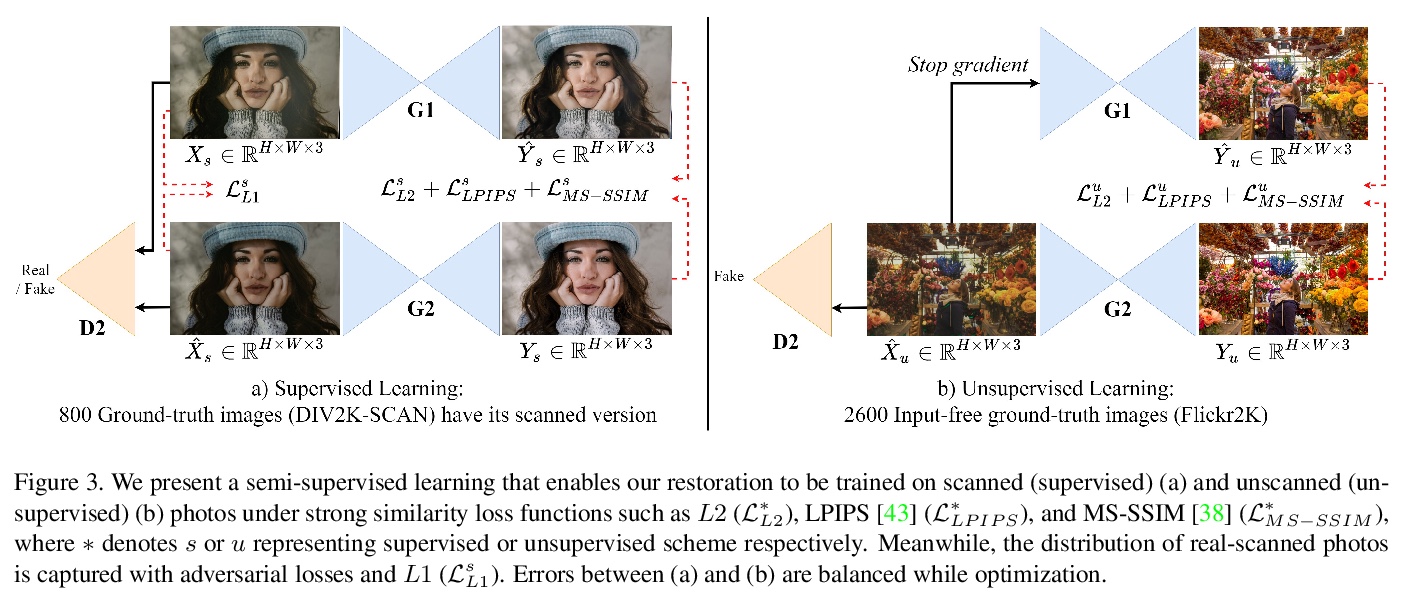
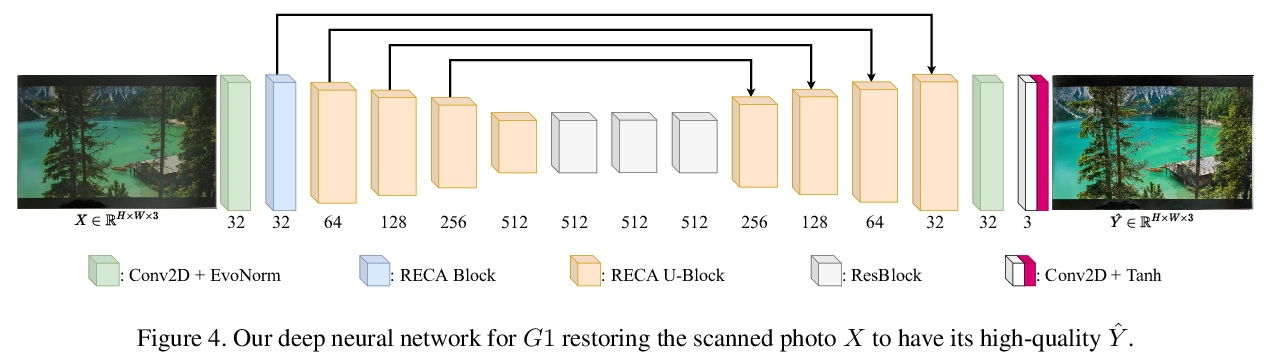
[CV] Deep Photo Scan: Semi-supervised learning for dealing with the real-world degradation in smartphone photo scanning
深度照片扫描:用于处理智能手机照片扫描中真实世界退化的半监督学习
M M. Ho, J Zhou
[Hosei University]
https://weibo.com/1402400261/K1HOwoYuI

若有收获,就点个赞吧
0 人点赞
