- 1、[AS] MusicBERT: Symbolic Music Understanding with Large-Scale Pre-Training
- 2、[CV] Plan2Scene: Converting Floorplans to 3D Scenes
- 3、[CV] Learning to See by Looking at Noise
- 4、[LG] Does Knowledge Distillation Really Work?
- 5、[CV] Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers
- [LG] Flow-based sampling for fermionic lattice field theories
- [CV] The Medical Segmentation Decathlon
- [CV] Pivotal Tuning for Latent-based Editing of Real Images
- [LG] Transformed CNNs: recasting pre-trained convolutional layers with self-attention
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[AS] MusicBERT: Symbolic Music Understanding with Large-Scale Pre-Training
M Zeng, X Tan, R Wang, Z Ju, T Qin, T Liu
[Microsoft Research Asia]
MusicBERT:基于大规模预训练的符号音乐理解。符号音乐理解,是指从符号数据(如MIDI格式,非音频)中理解音乐,涵盖许多音乐应用,如流派分类、情感分类和音乐作品匹配。虽然好的音乐表征对这些应用是有帮助的,但缺乏训练数据限制了表征学习。受自然语言处理中预训练模型成功的启发,本文开发了MusicBERT,一种用于音乐理解的大规模预训练模型。构建了一个大规模的符号音乐语料库,包含100多万首乐曲。由于符号音乐包含更多的结构性(如小节、位置)和多样性信息(如节奏、乐器和音高),简单将NLP预训练技术用于符号音乐,只能带来边际收益。本文设计了几种机制,包括OctupleMIDI编码和小节级掩蔽策略,以加强对符号音乐数据的预训练。实验证明了MusicBERT在四个音乐理解任务上的优势,包括旋律完成、伴奏生成、流派分类和风格分类。消融研究验证了在MusicBERT中设计的OctupleMIDI编码和小节级掩蔽策略的有效性。
Symbolic music understanding, which refers to the understanding of music from the symbolic data (e.g., MIDI format, but not audio), covers many music applications such as genre classification, emotion classification, and music pieces matching. While good music representations are beneficial for these applications, the lack of training data hinders representation learning. Inspired by the success of pre-training models in natural language processing, in this paper, we develop MusicBERT, a large-scale pre-trained model for music understanding. To this end, we construct a large-scale symbolic music corpus that contains more than 1 million music songs. Since symbolic music contains more structural (e.g., bar, position) and diverse information (e.g., tempo, instrument, and pitch), simply adopting the pre-training techniques from NLP to symbolic music only brings marginal gains. Therefore, we design several mechanisms, including OctupleMIDI encoding and bar-level masking strategy, to enhance pre-training with symbolic music data. Experiments demonstrate the advantages of MusicBERT on four music understanding tasks, including melody completion, accompaniment suggestion, genre classification, and style classification. Ablation studies also verify the effectiveness of our designs of OctupleMIDI encoding and barlevel masking strategy in MusicBERT.
https://weibo.com/1402400261/KjLYGyQ02


2、[CV] Plan2Scene: Converting Floorplans to 3D Scenes
M Vidanapathirana, Q Wu, Y Furukawa, A X. Chang, M Savva
[Simon Fraser University]
Plan2Scene: 将平面设计图转换为带有纹理的3D网格模型。本文的任务,是将住宅平面设计图和一组相关照片,转换成一个有纹理的3D网格模型,称为Plan2Scene。该系统:1)将平面设计图图像,提升为3D网格模型;2)根据输入照片合成表面纹理;3)用图神经网络架构,推断未观察到的表面纹理。为训练和评估该系统,创建了室内表面纹理数据集,并用经过校正的表面材质和附加标记,来扩充之前的平面设计图和照片数据集。该方法处理了为主要表面(如地板、墙壁和天花板)制作可铺设纹理的挑战,这些纹理来自于仅部分覆盖住宅的稀疏未对齐照片集。定性和定量评估表明,该系统产生了逼真的3D室内模型,在一系列纹理质量指标上优于基线方法,并通过全面的用户研究进行了衡量。
We address the task of converting a floorplan and a set of associated photos of a residence into a textured 3D mesh model, a task which we call Plan2Scene. Our system 1) lifts a floorplan image to a 3D mesh model; 2) synthesizes surface textures based on the input photos; and 3) infers textures for unobserved surfaces using a graph neural network architecture. To train and evaluate our system we create indoor surface texture datasets, and augment a dataset of floorplans and photos from prior work with rectified surface crops and additional annotations. Our approach handles the challenge of producing tileable textures for dominant surfaces such as floors, walls, and ceilings from a sparse set of unaligned photos that only partially cover the residence. Qualitative and quantitative evaluations show that our system produces realistic 3D interior models, outperforming baseline approaches on a suite of texture quality metrics and as measured by a holistic user study.
https://weibo.com/1402400261/KjM2x1HxF




3、[CV] Learning to See by Looking at Noise
M Baradad, J Wulff, T Wang, P Isola, A Torralba
[MIT CSAIL]
基于噪声图像观察的视觉学习。目前的视觉系统是在巨大的数据集上训练的,而这些数据集是有成本的:策划是昂贵的,它们继承了人工的偏见,还有对隐私和使用权的担忧。为应对这些成本,人们对从更廉价数据源(如未标记图像)中学习的兴趣大大增加。本文更进一步,探讨是否可以完全摒弃真实的图像数据集,而是从噪声过程中学习。研究了一套图像生成模型,从简单随机过程中产生图像,将这些图像用作具有对比损失的视觉表征学习器的训练数据。研究了两类噪声过程,统计图像模型和不同的随机初始化下的深度生成模型。研究结果表明,噪声捕捉真实数据的某些结构属性是很重要的,但即使是与现实相差甚远的过程,也能取得良好的性能。多样性是学习良好表征的一个关键属性。
Current vision systems are trained on huge datasets, and these datasets come with costs: curation is expensive, they inherit human biases, and there are concerns over privacy and usage rights. To counter these costs, interest has surged in learning from cheaper data sources, such as unlabeled images. In this paper we go a step further and ask if we can do away with real image datasets entirely, instead learning from noise processes. We investigate a suite of image generation models that produce images from simple random processes. These are then used as training data for a visual representation learner with a contrastive loss. We study two types of noise processes, statistical image models and deep generative models under di erent random initializations. Our ndings show that it is important for the noise to capture certain structural properties of real data but that good performance can be achieved even with processes that are far from realistic. We also nd that diversity is a key property to learn good representations.
https://weibo.com/1402400261/KjMa60G4v




4、[LG] Does Knowledge Distillation Really Work?
S Stanton, P Izmailov, P Kirichenko, A A. Alemi, A G Wilson
[New York University & Google Research]
知识蒸馏确实有效吗?知识蒸馏是一种流行技术,用于训练小的学生网络,来模仿更大的教师模型,如多网络集成。本文表明,虽然知识蒸馏可提高学生的泛化能力,但通常并不像人们所理解的那样起作用:教师和学生的预测分布之间,往往存在惊人的巨大差异,甚至在学生有能力完全匹配教师的情况下也是如此。优化方面的困难是学生无法与教师匹配的关键原因。展示了用于蒸馏的数据集的细节,是如何在学生与老师的匹配程度上发挥作用的——与老师更紧密的匹配并不总是能带来更好的学生的泛化能力。
Knowledge distillation is a popular technique for training a small student network to emulate a larger teacher model, such as an ensemble of networks. We show that while knowledge distillation can improve student generalization, it does not typically work as it is commonly understood: there often remains a surprisingly large discrepancy between the predictive distributions of the teacher and the student, even in cases when the student has the capacity to perfectly match the teacher. We identify difficulties in optimization as a key reason for why the student is unable to match the teacher. We also show how the details of the dataset used for distillation play a role in how closely the student matches the teacher — and that more closely matching the teacher paradoxically does not always lead to better student generalization.
https://weibo.com/1402400261/KjMkldw4l




5、[CV] Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers
M Patrick, D Campbell, Y M. Asano, I M F Metze, C Feichtenhofer, A Vedaldi, J F. Henriques
[Facebook AI & University of Oxford]
盯紧球:视频Transformer的轨迹注意力。视频Transformer中,时间维度通常与两个空间维度的处理方式相同。然而,在物体或摄像机可能移动的场景中,在第t帧的某个位置成像的物理点,可能与在第t+k帧的那个位置发现的东西完全没有关系。本文为视频Transformer提出一种新的即插即用式组块——轨迹注意力,沿隐含确定运动路径聚集信息。提出一种用来解决计算和内存对输入大小二次依赖的新方法,大大降低了内存需求,对高分辨率或长视频非常重要。这些想法在一系列环境中都有用,将其用在基于Transformer模型的视频动作识别的具体任务,在Kinetics、Something V2和Epic-Kitchens数据集上获得最先进的结果。
In video transformers, the time dimension is often treated in the same way as the two spatial dimensions. However, in a scene where objects or the camera may move, a physical point imaged at one location in frame t may be entirely unrelated to what is found at that location in frame t + k. These temporal correspondences should be modeled to facilitate learning about dynamic scenes. To this end, we propose a new drop-in block for video transformers—trajectory attention—that aggregates information along implicitly determined motion paths. We additionally propose a new method to address the quadratic dependence of computation and memory on the input size, which is particularly important for high resolution or long videos. While these ideas are useful in a range of settings, we apply them to the specific task of video action recognition with a transformer model and obtain state-of-the-art results on the Kinetics, Something–Something V2, and Epic-Kitchens datasets.
https://weibo.com/1402400261/KjMnYEWoA



另外几篇值得关注的论文:
[LG] Flow-based sampling for fermionic lattice field theories
费米子晶格场理论基于流的采样
M S. Albergo, G Kanwar, S Racanière, D J. Rezende, J M. Urban, D Boyda, K Cranmer, D C. Hackett, P E. Shanahan
[New York University & MIT & DeepMind & Universitat Heidelberg]
https://weibo.com/1402400261/KjMdZ2pPB




[CV] The Medical Segmentation Decathlon
医学分割十项全能竞赛
M Antonelli, A Reinke, S Bakas, K Farahani, AnnetteKopp-Schneider…
[King’s College London & German Cancer Research Center (DKFZ) & University of Pennsylvania…]
https://weibo.com/1402400261/KjMrN9e4u





[CV] Pivotal Tuning for Latent-based Editing of Real Images
基于枢轴微调的真实(人脸)图像隐特征编辑
D Roich, R Mokady, A H. Bermano, D Cohen-Or
[Tel Aviv University]
https://weibo.com/1402400261/KjMuQwzle




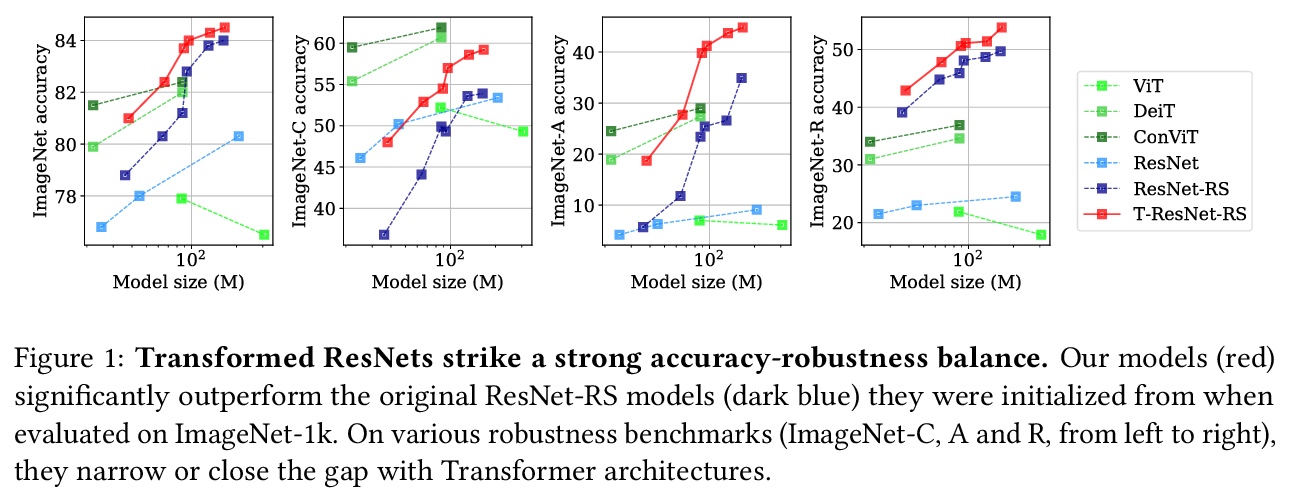
[LG] Transformed CNNs: recasting pre-trained convolutional layers with self-attention
Transformed CNNs:用自注意力再造预训练卷积层
S d’Ascoli, L Sagun, G Biroli, A Morcos
[Sorbonne Université & Facebook AI Research]
https://weibo.com/1402400261/KjMxNbMHU




若有收获,就点个赞吧
0 人点赞
