- 1、[LG] A Bayesian neural network predicts the dissolution of compact planetary systems
- 2、[CV] Neural Non-Rigid Tracking
- 3、[CL] A Distributional Approach to Controlled Text Generation
- 4、[CV] Superpixel-based Refinement for Object Proposal Generation
- 5、[CV] Fine-grained Semantic Constraint in Image Synthesis
- [CL] BERT-GT: Cross-sentence n-ary relation extraction with BERT and Graph Transformer
- [LG] A Tale of Fairness Revisited: Beyond Adversarial Learning for Deep Neural Network Fairness
- [CV] Learning Temporal Dynamics from Cycles in Narrated Video
- [CL] Implicit Unlikelihood Training: Improving Neural Text Generation with Reinforcement Learning
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] A Bayesian neural network predicts the dissolution of compact planetary systems
M Cranmer, D Tamayo, H Rein, P Battaglia, S Hadden, P J. Armitage, S Ho, D N. Spergel
[Princeton University & University of Toronto at Scarborough & DeepMind]
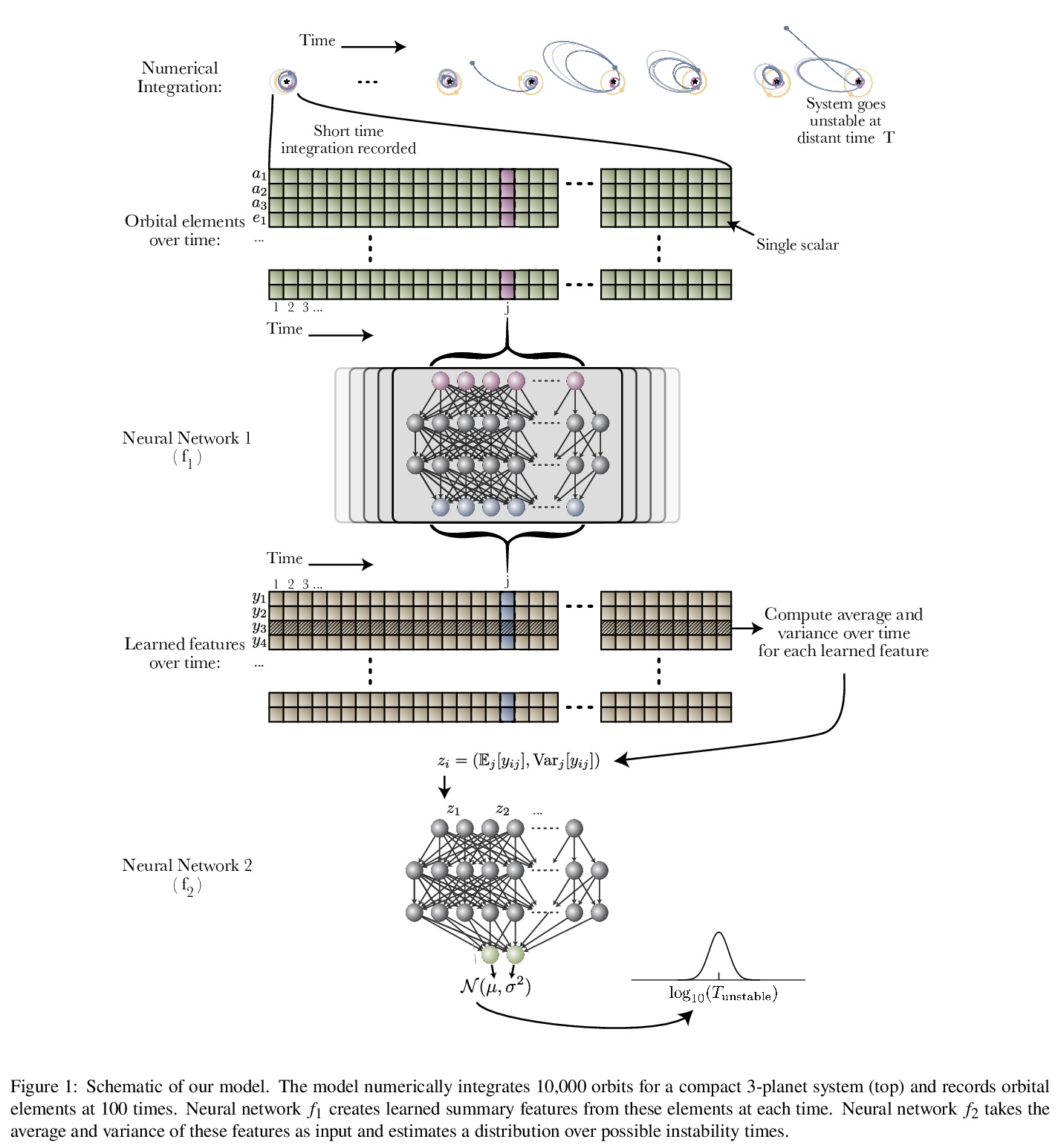
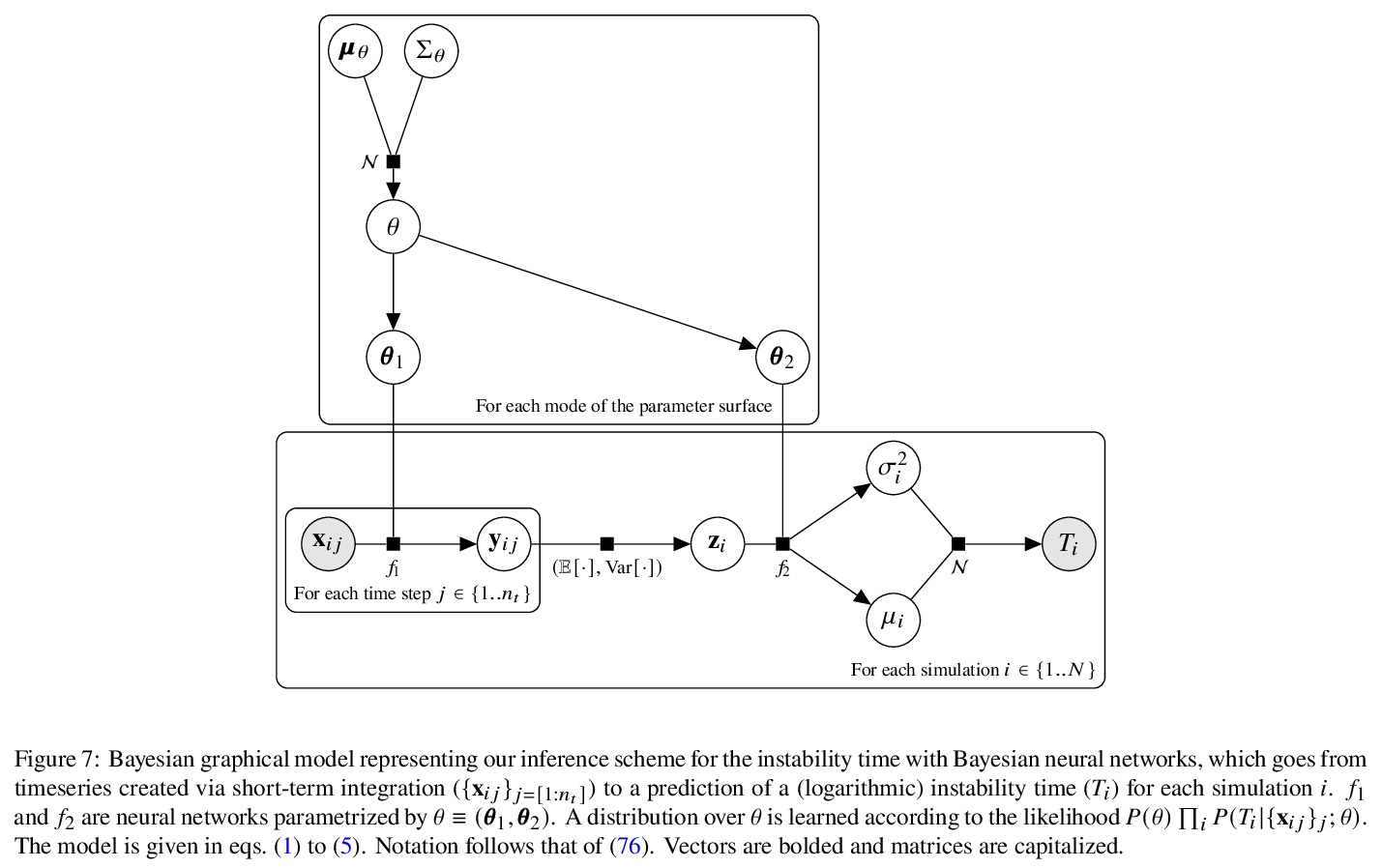
贝叶斯神经网络致密行星系统解体预测。描述了一种概率机器学习模型——贝叶斯神经网络,可准确预测给定的致密多行星系外行星系统在时间上可能的不稳定性分布。模型用多行星系统的原始轨道参数的短积分进行训练,学习自身的不稳定性指标,在预测不稳定时间方面比解析估计器精确两个数量级以上,同时也将现有机器学习算法的偏差降低了近3倍,计算不稳定性估计值的速度比数值积分器快5个数量级,而且不同于以往的方法,该模型还提供了预测的置信区间。
Despite over three hundred years of effort, no solutions exist for predicting when a general planetary configuration will become unstable. We introduce a deep learning architecture to push forward this problem for compact systems. While current machine learning algorithms in this area rely on scientist-derived instability metrics, our new technique learns its own metrics from scratch, enabled by a novel internal structure inspired from dynamics theory. Our Bayesian neural network model can accurately predict not only if, but also when a compact planetary system with three or more planets will go unstable. Our model, trained directly from short N-body time series of raw orbital elements, is more than two orders of magnitude more accurate at predicting instability times than analytical estimators, while also reducing the bias of existing machine learning algorithms by nearly a factor of three. Despite being trained on compact resonant and near-resonant three-planet configurations, the model demonstrates robust generalization to both non-resonant and higher multiplicity configurations, in the latter case outperforming models fit to that specific set of integrations. The model computes instability estimates up to five orders of magnitude faster than a numerical integrator, and unlike previous efforts provides confidence intervals on its predictions. Our inference model is publicly available in the SPOCK package, with training code open-sourced.
https://weibo.com/1402400261/JD50hgCcK
2、[CV] Neural Non-Rigid Tracking
A Božič, P Palafox, M Zollhöfer, A Dai, J Thies, M Nießner
[Technical University of Munich & Stanford University]
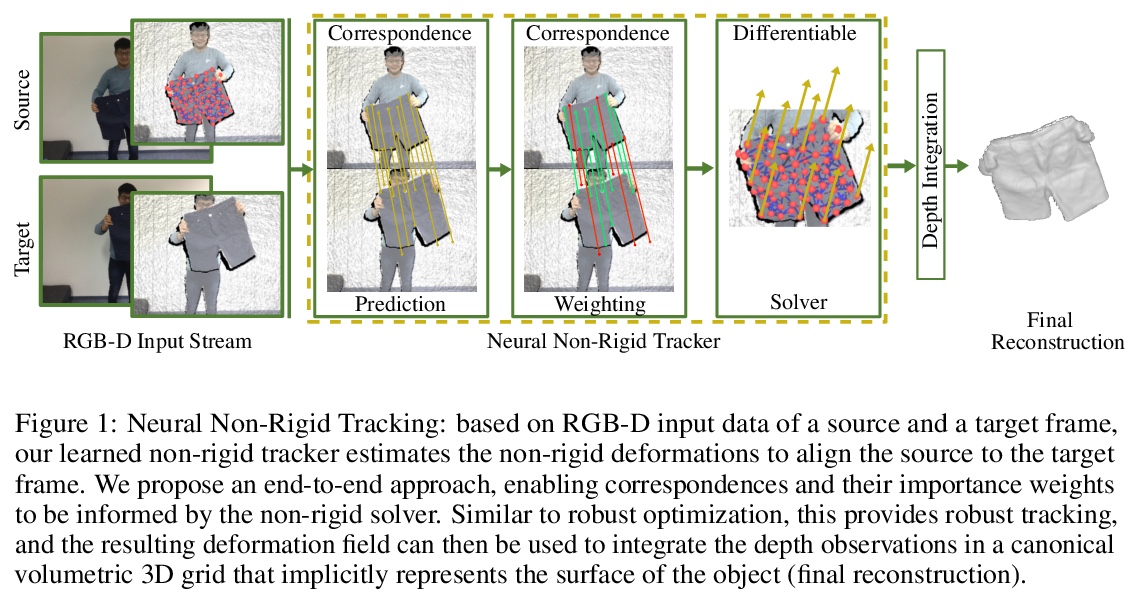
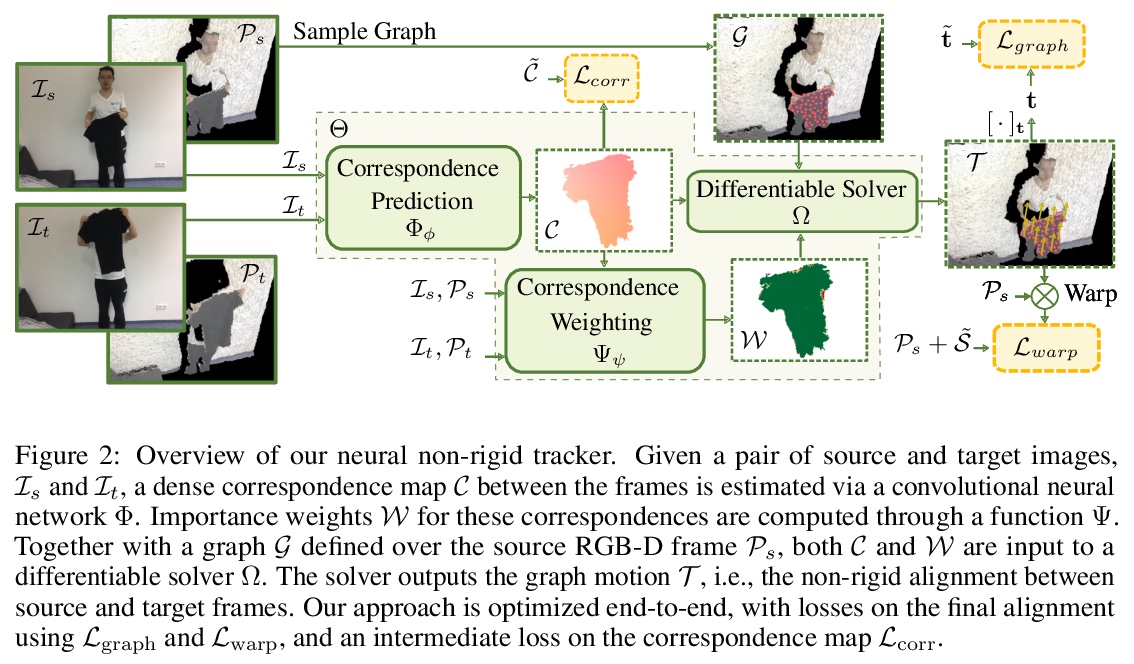
神经网络非刚性追踪。提出一种端到端、可学习、可微的非刚性追踪器,可通过习得的鲁棒优化,实现最先进的非刚性重建。给定非刚性运动物体的两帧RGB-D输入帧,用卷积神经网络来预测密集的对应关系及其置信度。这些对应关系被用作刚性似然(ARAP)优化问题的约束条件,通过加权非线性最小二乘法求解器实现梯度反向传播,以端到端方式学习对应关系和置信度,使其在非刚性追踪任务中达到最优。通过自监督学习对应的置信度,为习得鲁棒优化提供信息,离群值和错误的对应置信度被自动降权,以实现有效跟踪。与最先进方法相比,该算法显示出了改进的重建性能,同时实现了比同类基于深度学习的方法快85倍的对应关系预测。
We introduce a novel, end-to-end learnable, differentiable non-rigid tracker that enables state-of-the-art non-rigid reconstruction by a learned robust optimization. Given two input RGB-D frames of a non-rigidly moving object, we employ a convolutional neural network to predict dense correspondences and their confidences. These correspondences are used as constraints in an as-rigid-as-possible (ARAP) optimization problem. By enabling gradient back-propagation through the weighted non-linear least squares solver, we are able to learn correspondences and confidences in an end-to-end manner such that they are optimal for the task of non-rigid tracking. Under this formulation, correspondence confidences can be learned via self-supervision, informing a learned robust optimization, where outliers and wrong correspondences are automatically down-weighted to enable effective tracking. Compared to state-of-the-art approaches, our algorithm shows improved reconstruction performance, while simultaneously achieving 85 times faster correspondence prediction than comparable deep-learning based methods. We make our code available.
https://weibo.com/1402400261/JD5fiDTV4

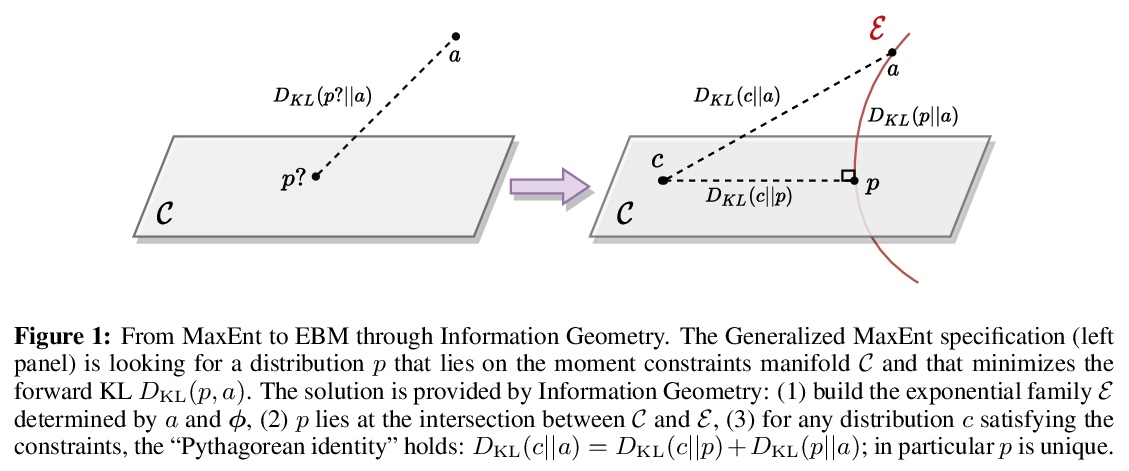
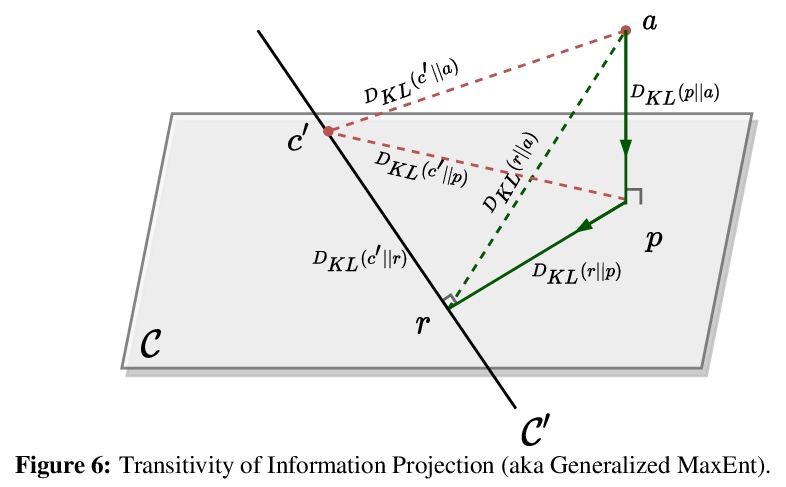
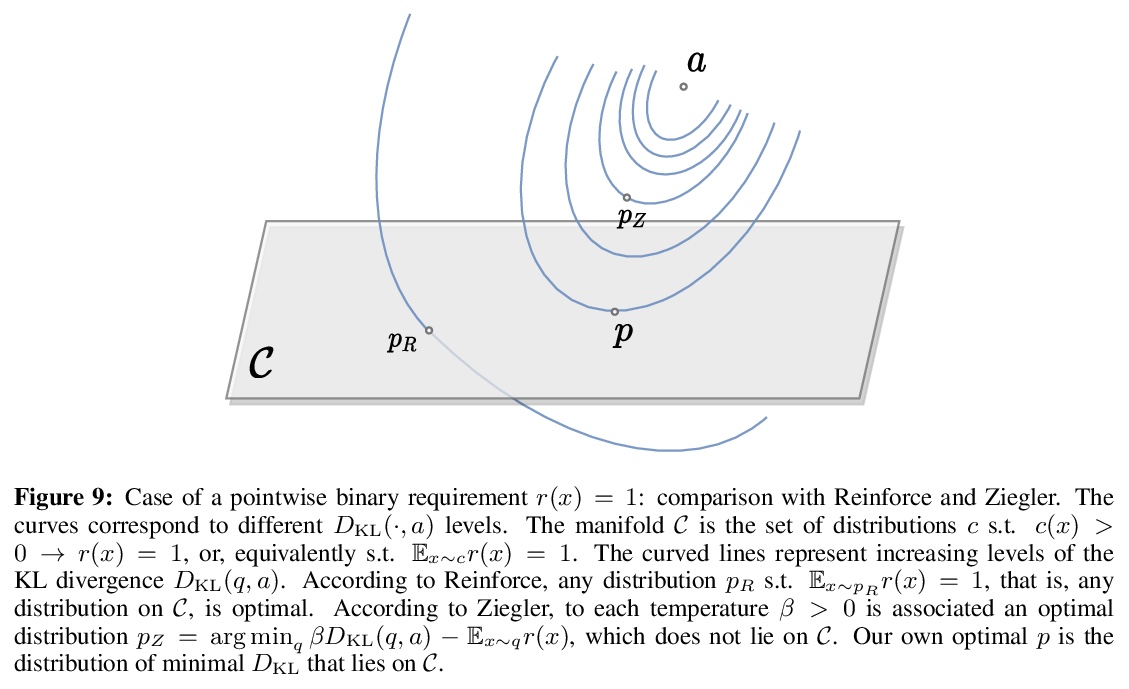
3、[CL] A Distributional Approach to Controlled Text Generation
(ICLR 2021 Conference Blind Submission)
受控文本生成的分布式方法。提出一种分布式方法,来解决基于预训练语言模型的受控文本生成问题。该观点允许在单一的形式框架中定义目标语言模型的”单点”和”分布式”约束,在初始语言模型分布下最小化KL散度,最佳的目标分布被唯一确定为明确的EBM(基于能量的模型)表示,利用该优化表示,通过策略梯度的自适应分布式变体,训练目标受控自回归语言模型。实验证明,所提出的自适应技术可获得更快的收敛性和有效性。
We propose a Distributional Approach to address Controlled Text Generation from pre-trained Language Models (LMs). This view permits to define, in a single formal framework, “pointwise” and “distributional” constraints over the target LM —- to our knowledge, this is the first approach with such generality —- while minimizing KL divergence with the initial LM distribution. The optimal target distribution is then uniquely determined as an explicit EBM (Energy-Based Model) representation. From that optimal representation, we then train the target controlled autoregressive LM through an adaptive distributional variant of Policy Gradient. We conduct a first set of experiments over pointwise constraints showing the advantages of our approach over a set of baselines, in terms of obtaining a controlled LM balancing constraint satisfaction with divergence from the initial LM (GPT-2). We then perform experiments over distributional constraints, a unique feature of our approach, demonstrating its potential as a remedy to the problem of Bias in Language Models. Through an ablation study, we show the effectiveness of our adaptive technique for obtaining faster convergence.
https://weibo.com/1402400261/JD5kIlSwh
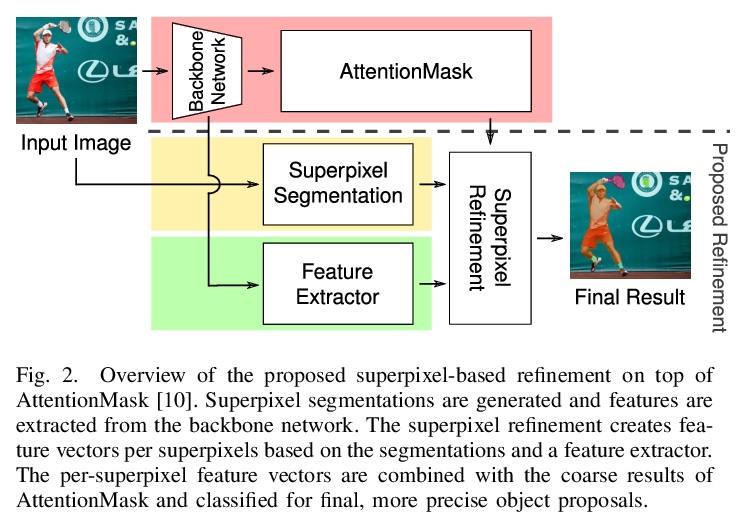
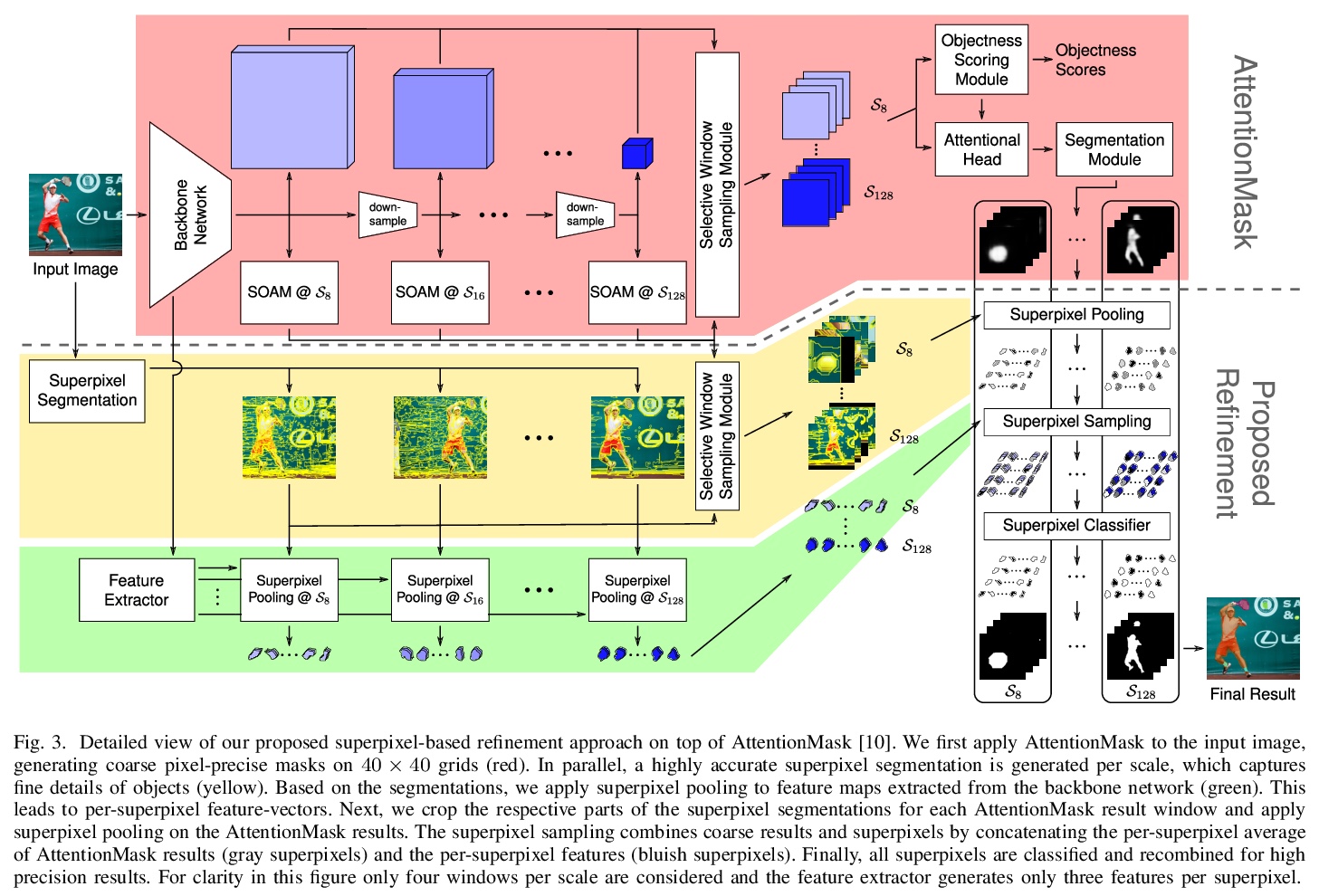
4、[CV] Superpixel-based Refinement for Object Proposal Generation
C Wilms, S Frintrop
[University of Hamburg]
基于超像素细化的目标候选框生成。为解决基于CNN的目标候选框生成中,由于下采样导致的目标分割不精确的问题,在最先进的AttentionMask基础上,提出基于超像素的细化方法,利用高度精确的超像素分割、超像素池化和新的超像素分类器来改善生成结果,利用超像素池化进行特征提取,用超像素分类器判断一个高精度超像素是否属于一个目标。实验表明,与原始AttentionMask相比,平均召回率提高了26.0%,具有较低的过分割误差。
Precise segmentation of objects is an important problem in tasks like class-agnostic object proposal generation or instance segmentation. Deep learning-based systems usually generate segmentations of objects based on coarse feature maps, due to the inherent downsampling in CNNs. This leads to segmentation boundaries not adhering well to the object boundaries in the image. To tackle this problem, we introduce a new superpixel-based refinement approach on top of the state-of-the-art object proposal system AttentionMask. The refinement utilizes superpixel pooling for feature extraction and a novel superpixel classifier to determine if a high precision superpixel belongs to an object or not. Our experiments show an improvement of up to 26.0% in terms of average recall compared to original AttentionMask. Furthermore, qualitative and quantitative analyses of the segmentations reveal significant improvements in terms of boundary adherence for the proposed refinement compared to various deep learning-based state-of-the-art object proposal generation systems.
https://weibo.com/1402400261/JD5tMpCq7


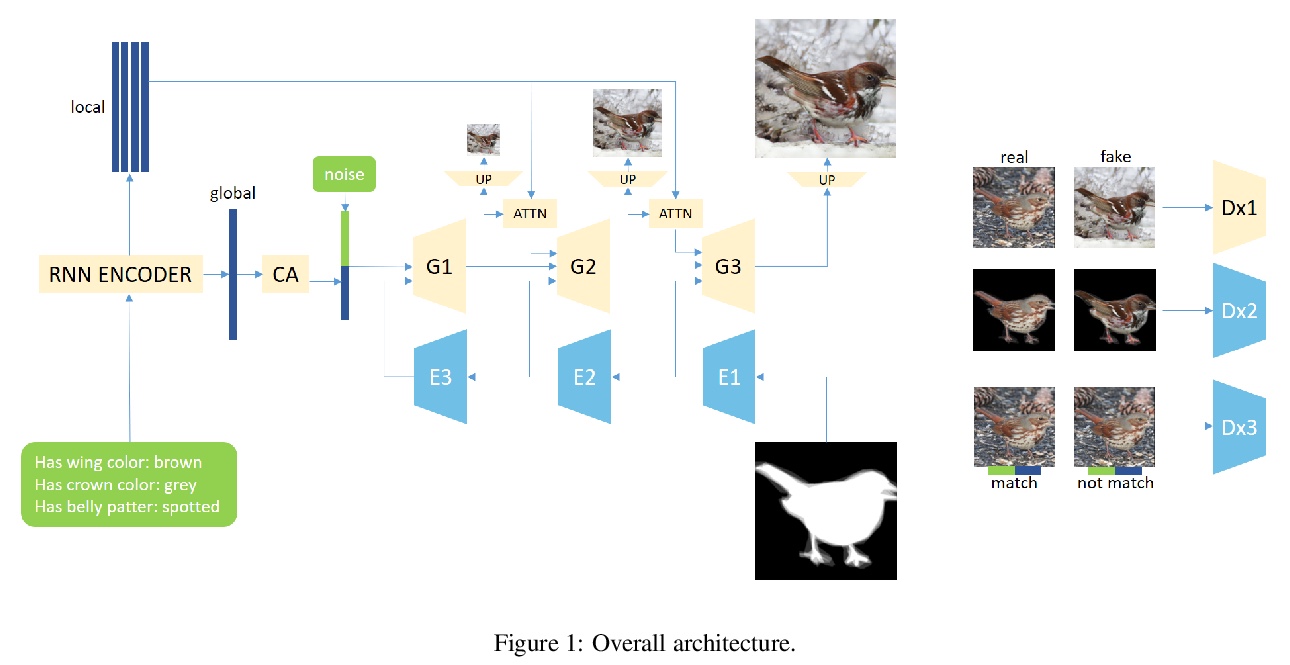
5、[CV] Fine-grained Semantic Constraint in Image Synthesis
P Li, D Wang
[Zhejiang University]
图像合成中的细粒度语义约束。提出一种以细粒度属性和掩膜为输入的多阶段高分辨率图像合成模型,可通过属性中丰富而细粒度的语义信息,对生成图像的特征进行细致约束。以掩膜作为先验约束,生成的图像符合视觉感官,能减少生成式对抗网络生成样本的意外多样性。提出了改进生成式对抗网络判别器的方案,同时对图像的全区域和子区域进行判别。提出了优化数据集中标注属性的方法,降低了人工标注的噪声。实验结果表明,所提出的图像合成模型能生成更真实的图像。
In this paper, we propose a multi-stage and high-resolution model for image synthesis that uses fine-grained attributes and masks as input. With a fine-grained attribute, the proposed model can detailedly constrain the features of the generated image through rich and fine-grained semantic information in the attribute. With mask as prior, the model in this paper is constrained so that the generated images conform to visual senses, which will reduce the unexpected diversity of samples generated from the generative adversarial network. This paper also proposes a scheme to improve the discriminator of the generative adversarial network by simultaneously discriminating the total image and sub-regions of the image. In addition, we propose a method for optimizing the labeled attribute in datasets, which reduces the manual labeling noise. Extensive quantitative results show that our image synthesis model generates more realistic images.
https://weibo.com/1402400261/JD5E91Y3V
另外几篇值得关注的论文:
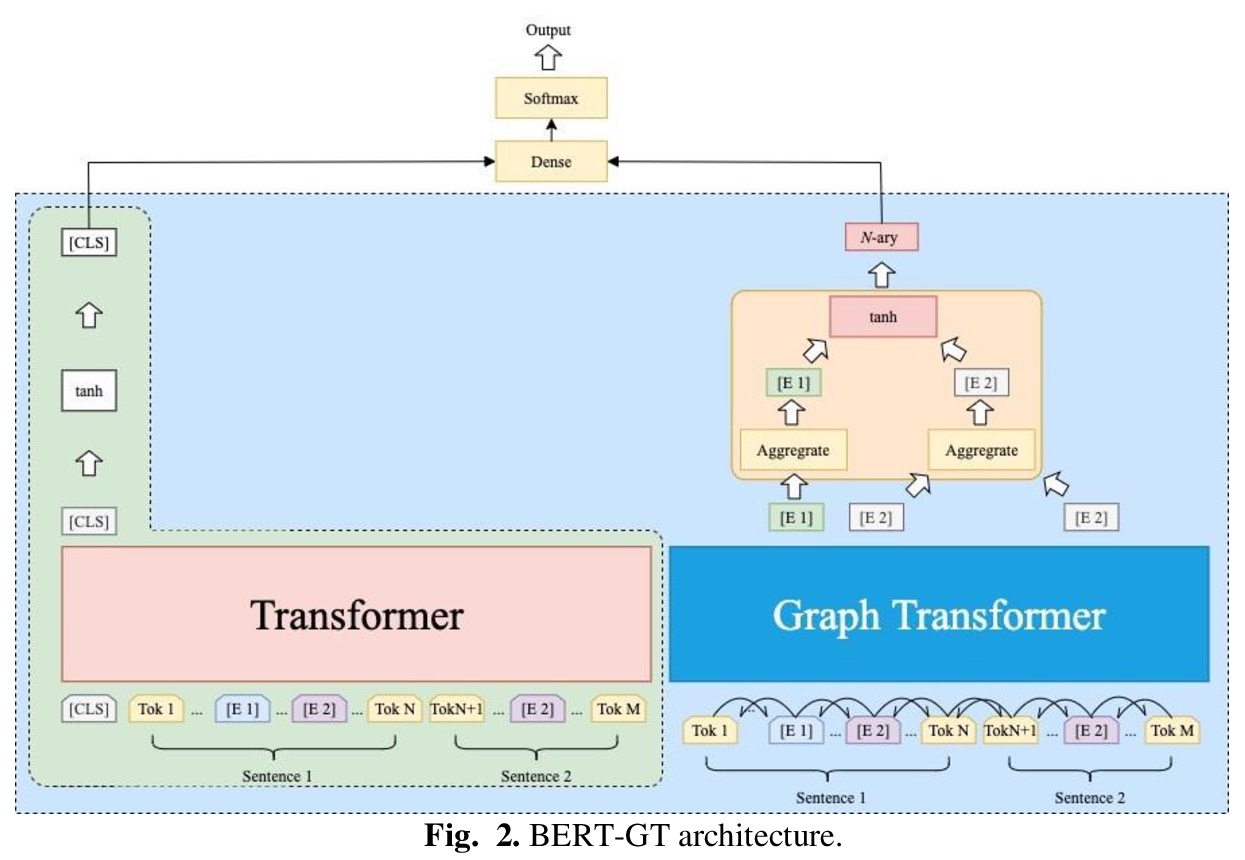
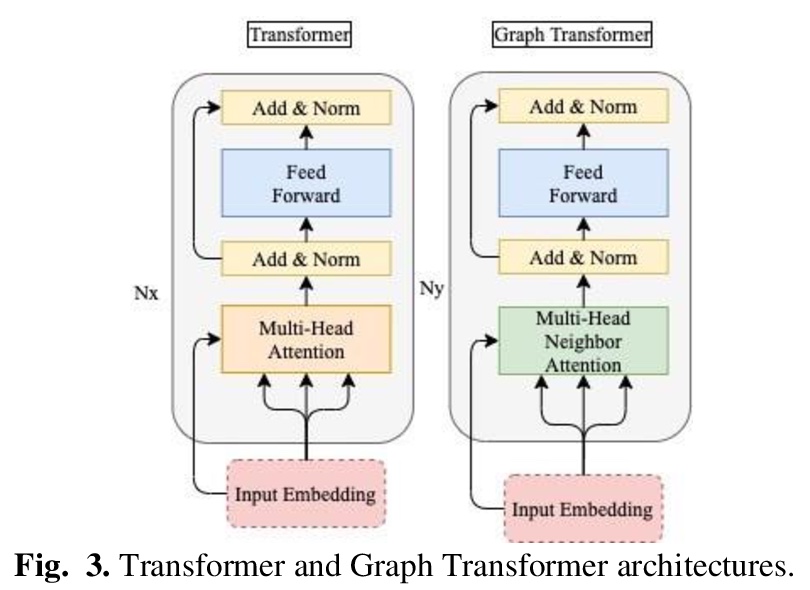
[CL] BERT-GT: Cross-sentence n-ary relation extraction with BERT and Graph Transformer
BERT-GT:基于BERT和图Transformer的跨句n元关系抽取
P Lai, Z Lu
[National Institutes of Health (NIH)]
https://weibo.com/1402400261/JD5HSbVt5

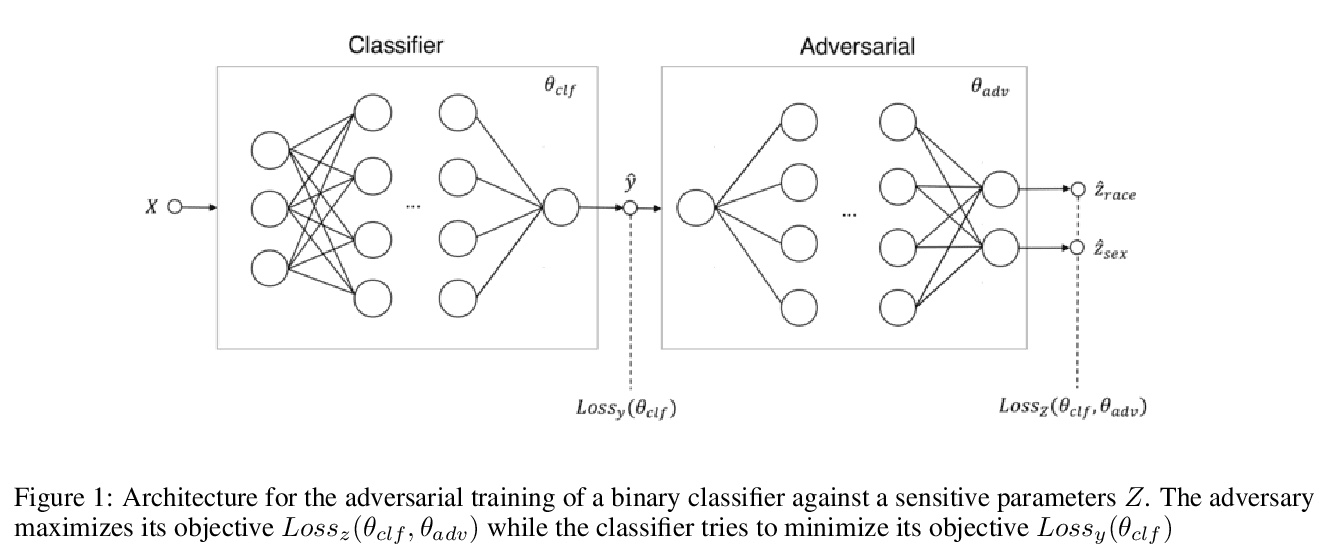
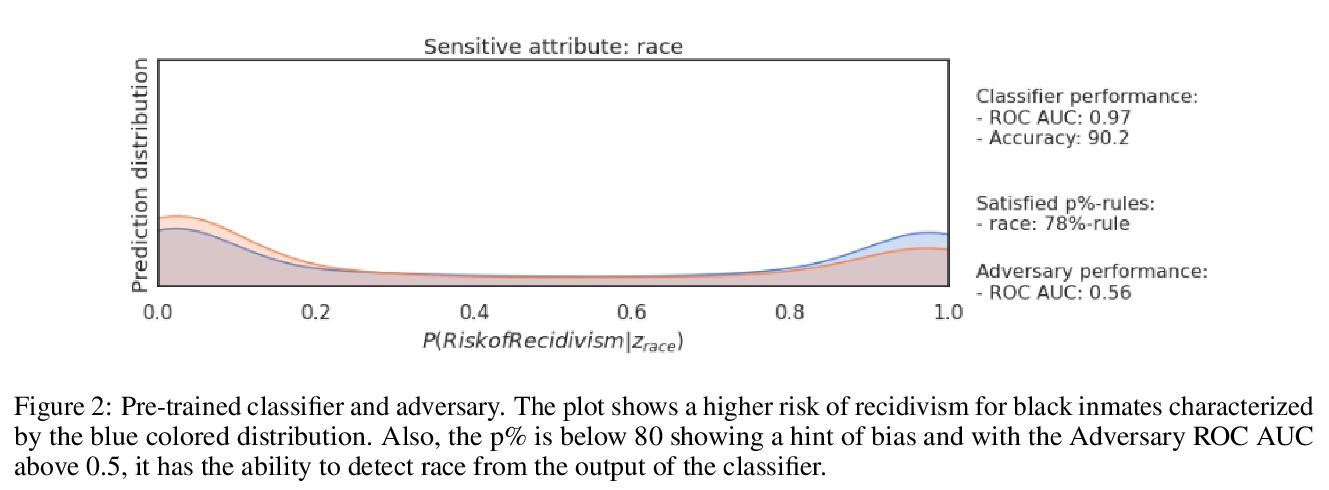
[LG] A Tale of Fairness Revisited: Beyond Adversarial Learning for Deep Neural Network Fairness
深度学习的公平对抗性训练
B Mashaido, W M Tangongho
[Northeastern University]
https://weibo.com/1402400261/JD5JR48Me
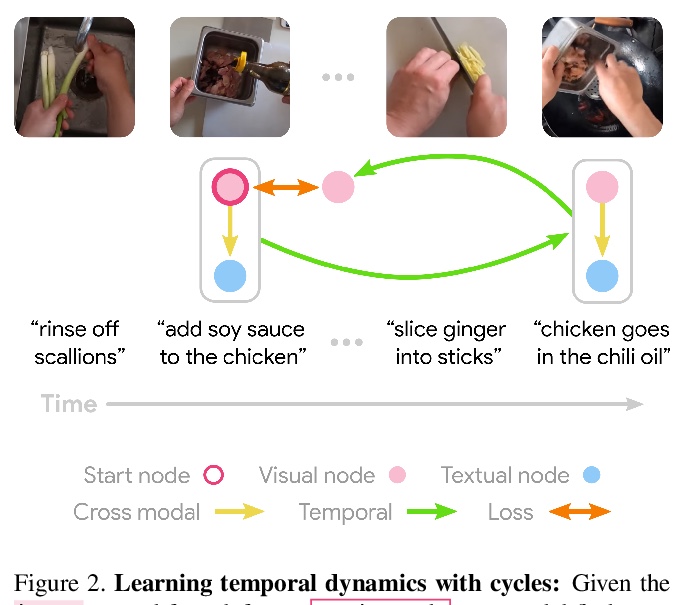
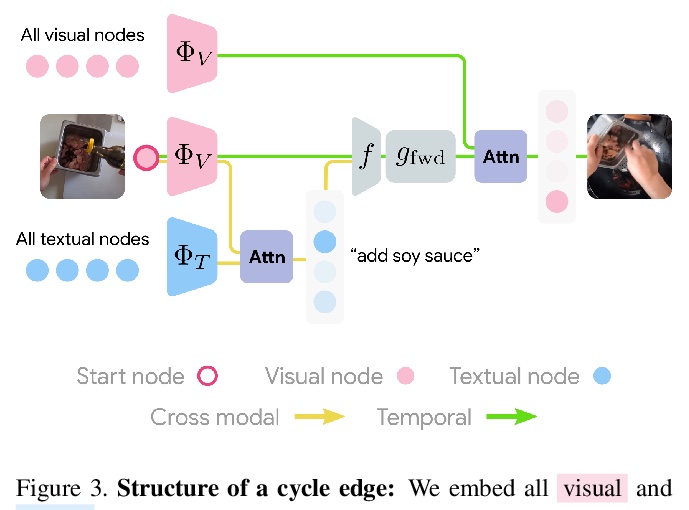
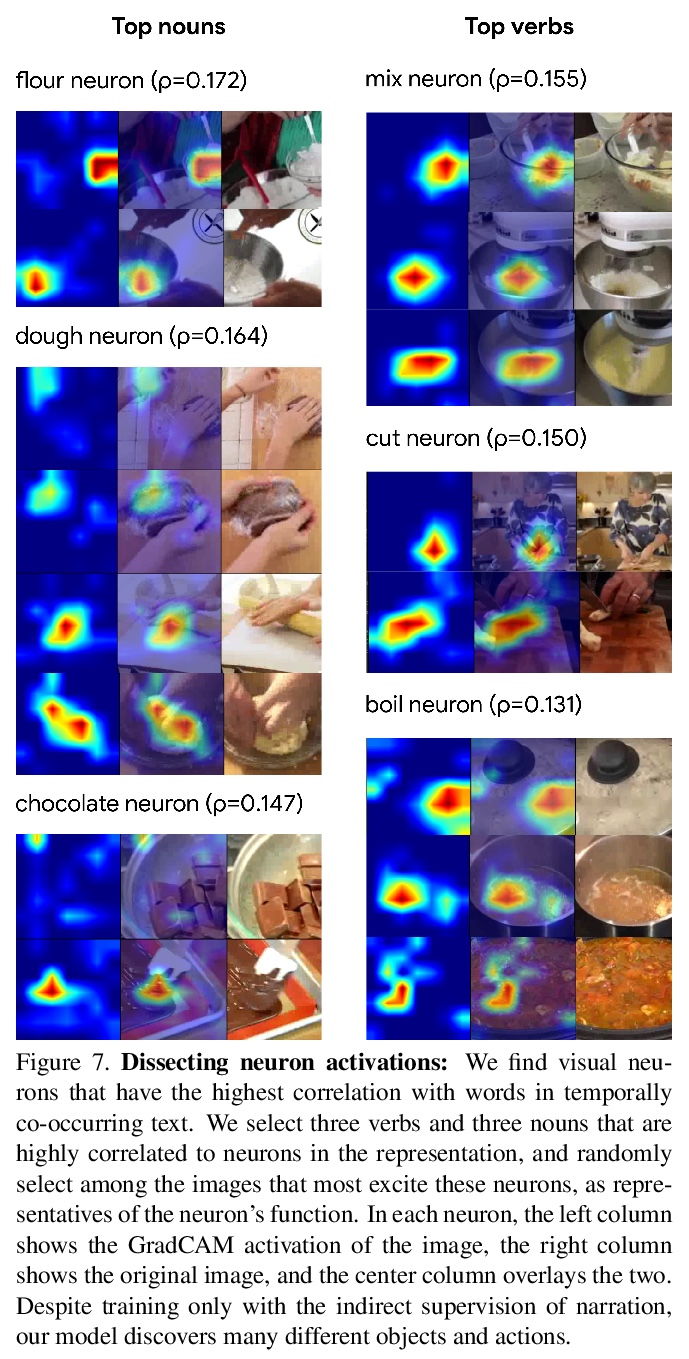
[CV] Learning Temporal Dynamics from Cycles in Narrated Video
基于叙事视频周期性的时间变化动态学习
D Epstein, J Wu, C Schmid, C Sun
[UC Berkeley & Stanford University & Google]
https://weibo.com/1402400261/JD5QH5Zi0
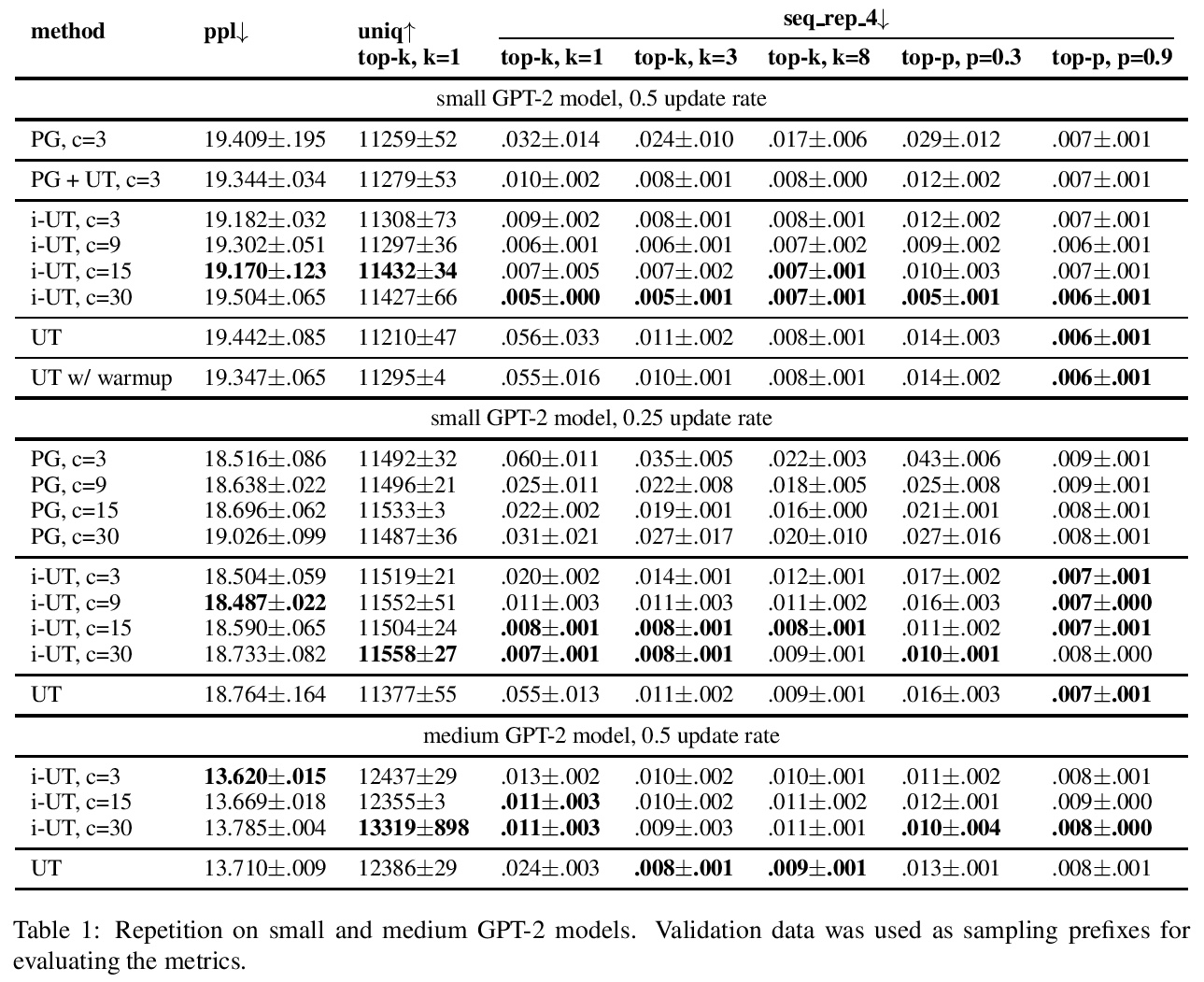
[CL] Implicit Unlikelihood Training: Improving Neural Text Generation with Reinforcement Learning
隐性不似然训练:用强化学习改善神经网络文本生成
E Lagutin, D Gavrilov, P Kalaidin
[VK]
https://weibo.com/1402400261/JD5XRcjHE


若有收获,就点个赞吧
0 人点赞
