- 1、[LG] Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability
- 2、[CV] Perceiver: General Perception with Iterative Attention
- 3、[LG] Learning Proposals for Probabilistic Programs with Inference Combinators
- 4、[CV] OmniNet: Omnidirectional Representations from Transformers
- 5、[CV] Enhanced 3D Human Pose Estimation from Videos by using Attention-Based Neural Network with Dilated Convolutions
- [CV] Energy-Based Learning for Scene Graph Generation
- [CV] Single-Shot Motion Completion with Transformer
- [AI] Neural Production Systems
- [IR] Simplified Data Wrangling with ir_datasets
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability
J M. Cohen, S Kaur, Y Li, J. Z Kolter, A Talwalkar
[CMU & Bosch AI & Determined AI]
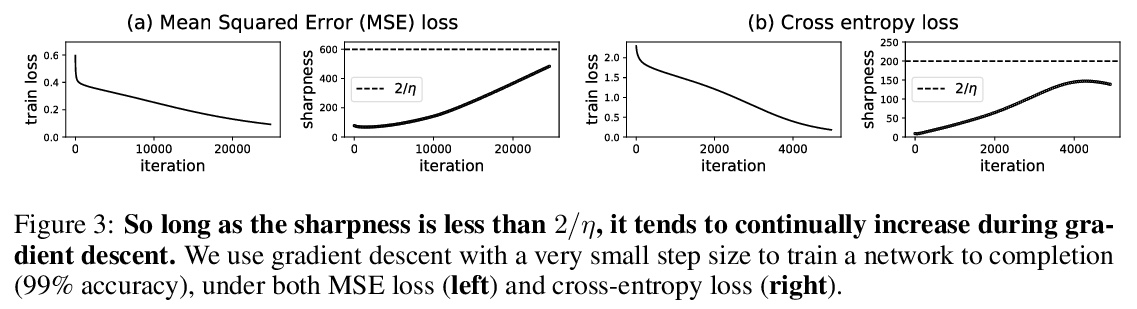
神经网络梯度下降通常发生在稳定边缘。通过实证证明,神经网络训练目标的全批次梯度下降通常运行在一个叫做稳定边缘(Edge of Stability)的体系中,梯度衰减对神经训练目标的行为在不同架构和任务中惊人地一致,训练损失Hessian的最大特征值刚好徘徊在2/(步长大小)之上,训练损失在短时间尺度上表现为非单调性,在长时间尺度上却持续下降。由于这种行为与优化领域几个广泛的预设不一致,提出了这些预设是否与神经网络训练相关的问题。希望该发现能启发未来旨在严格理解稳定边缘优化的努力。
We empirically demonstrate that full-batch gradient descent on neural network training objectives typically operates in a regime we call the Edge of Stability. In this regime, the maximum eigenvalue of the training loss Hessian hovers just above the numerical value > 2/(step size), and the training loss behaves non-monotonically over short timescales, yet consistently decreases over long timescales. Since this behavior is inconsistent with several widespread presumptions in the field of optimization, our findings raise questions as to whether these presumptions are relevant to neural network training. We hope that our findings will inspire future efforts aimed at rigorously understanding optimization at the Edge of Stability. Code is available at > this https URL.
https://weibo.com/1402400261/K51OIuldS

2、[CV] Perceiver: General Perception with Iterative Attention
A Jaegle, F Gimeno, A Brock, A Zisserman, O Vinyals, J Carreira
[DeepMind]
Perceiver:迭代注意力通用感知。提出Perceiver,建立在Transformer基础上,旨在用单一的基于Transformer的架构来处理不同模态的任意配置的模型,对输入之间的关系做了很少的架构假设,可以像ConvNets一样,扩展到数十万个输入。该模型利用非对称注意力机制,迭代地将输入提炼成一个紧密的潜瓶颈,使其能够扩展到处理非常大的输入。该架构在各种模态的分类任务上的表现可以与强大的专业模型相比甚至更好:图像、点云、音频、视频和视频+音频。Perceiver在ImageNet上获得了与ResNet-50相当的性能,不使用卷积,直接关注50,000个像素,还超越了AudioSet上所有模式的最先进结果。
Biological systems understand the world by simultaneously processing high-dimensional inputs from modalities as diverse as vision, audition, touch, proprioception, etc. The perception models used in deep learning on the other hand are designed for individual modalities, often relying on domain-specific assumptions such as the local grid structures exploited by virtually all existing vision models. These priors introduce helpful inductive biases, but also lock models to individual modalities. In this paper we introduce the Perceiver - a model that builds upon Transformers and hence makes few architectural assumptions about the relationship between its inputs, but that also scales to hundreds of thousands of inputs, like ConvNets. The model leverages an asymmetric attention mechanism to iteratively distill inputs into a tight latent bottleneck, allowing it to scale to handle very large inputs. We show that this architecture performs competitively or beyond strong, specialized models on classification tasks across various modalities: images, point clouds, audio, video and video+audio. The Perceiver obtains performance comparable to ResNet-50 on ImageNet without convolutions and by directly attending to 50,000 pixels. It also surpasses state-of-the-art results for all modalities in AudioSet.
https://weibo.com/1402400261/K520C2kuG



3、[LG] Learning Proposals for Probabilistic Programs with Inference Combinators
S Stites, H Zimmermann, H Wu, E Sennesh, J v d Meent
[Northeastern University]
推理组合器概率编程学习方案。开发了用于在概率编程中构建方案的运算符,称为推理组合器。推理组合器在重要性采样器上定义了一个语法,这些采样器组成了诸如过渡核应用和重要性重采样等元操作。采样器方案可使用神经网络进行参数化,而神经网络可通过优化变量目标来训练。其结果是一个构造正确且可根据特定模型进行定制的用户可编程变分方法框架。通过实现基于摊开吉布斯抽样和退火的高级变分方法证明了该框架的灵活性。
We develop operators for construction of proposals in probabilistic programs, which we refer to as inference combinators. Inference combinators define a grammar over importance samplers that compose primitive operations such as application of a transition kernel and importance resampling. Proposals in these samplers can be parameterized using neural networks, which in turn can be trained by optimizing variational objectives. The result is a framework for user-programmable variational methods that are correct by construction and can be tailored to specific models. We demonstrate the flexibility of this framework by implementing advanced variational methods based on amortized Gibbs sampling and annealing.
https://weibo.com/1402400261/K526a3ULo


4、[CV] OmniNet: Omnidirectional Representations from Transformers
Y Tay, M Dehghani, V Aribandi, J Gupta, P Pham, Z Qin, D Bahri, D Juan, D Metzler
[Google]
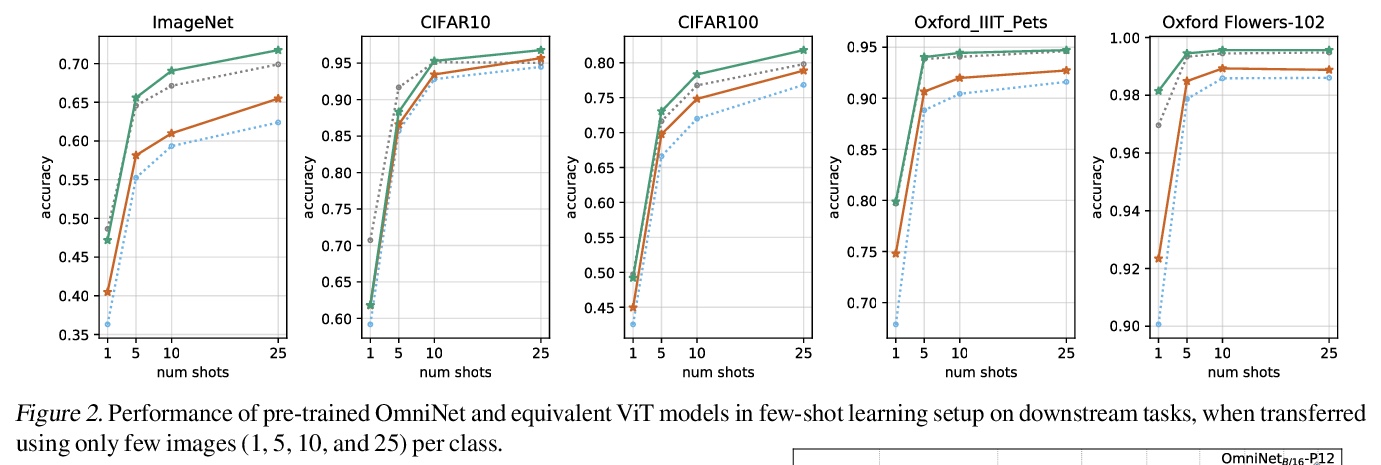
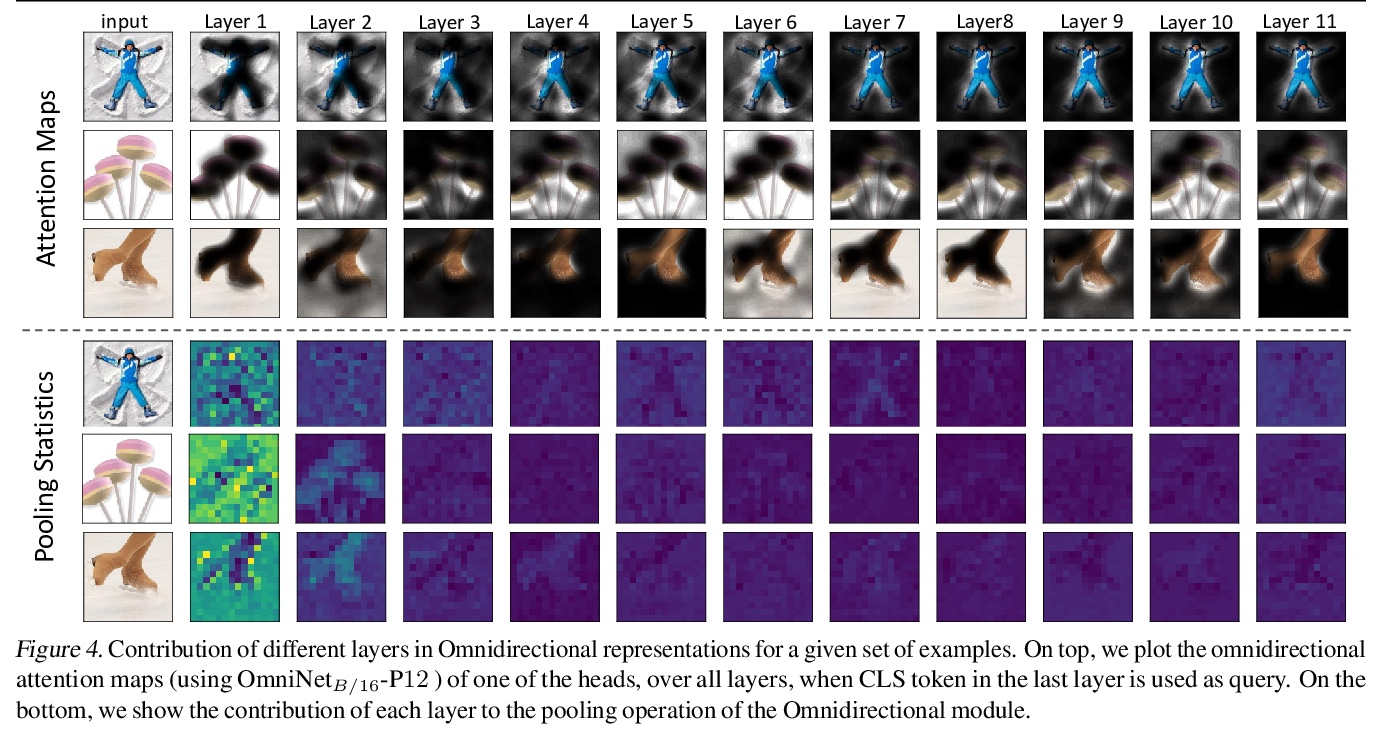
OmniNet: Transformer全向表示。提出了OmniNet,使用全向注意力通过自注意力将整个网络所有token连接起来。OmniNet中,不再保持一个严格的水平感受野,而是允许每个token关注整个网络中的所有token。这个过程也可以解释为一种极端或密集的注意力机制,其感受野是整个网络的宽度和深度。全向注意力是通过元学习器来学习的,本质上是另一种基于自注意力的模型。为了减轻全感受野注意力的计算成本,利用高效的自注意力模型作为元学习器。所提出方法在大量的语言和视觉任务上取得了出色的性能,在WMT EnDe和EnFr上实现了最先进性能,优于60层深度transformer,在图像识别任务上也表现出相比ViT的大幅改进。
This paper proposes Omnidirectional Representations from Transformers (OmniNet). In OmniNet, instead of maintaining a strictly horizontal receptive field, each token is allowed to attend to all tokens in the entire network. This process can also be interpreted as a form of extreme or intensive attention mechanism that has the receptive field of the entire width and depth of the network. To this end, the omnidirectional attention is learned via a meta-learner, which is essentially another self-attention based model. In order to mitigate the computationally expensive costs of full receptive field attention, we leverage efficient self-attention models such as kernel-based (Choromanski et al.), low-rank attention (Wang et al.) and/or Big Bird (Zaheer et al.) as the meta-learner. Extensive experiments are conducted on autoregressive language modeling (LM1B, C4), Machine Translation, Long Range Arena (LRA), and Image Recognition. The experiments show that OmniNet achieves considerable improvements across these tasks, including achieving state-of-the-art performance on LM1B, WMT’14 En-De/En-Fr, and Long Range Arena. Moreover, using omnidirectional representation in Vision Transformers leads to significant improvements on image recognition tasks on both few-shot learning and fine-tuning setups.
https://weibo.com/1402400261/K52c3hvoW


5、[CV] Enhanced 3D Human Pose Estimation from Videos by using Attention-Based Neural Network with Dilated Convolutions
R Liu, J Shen, H Wang, C Chen, S Cheung, V K. Asari
[University of Dayton]
利用基于注意力和扩张卷积的神经网络实现的视频3D人体姿态估计。提出一种新方法,用于无约束视频中3D人体姿态估计和重建,具有任意视频序列作为输入的灵活性和可扩展性。为增强时间一致性,将注意力机制集成到时间卷积网络中,引导网络学习信息性表示。引入多尺度扩张卷积,捕捉多个层次的时间感受野,实现帧间的长程依赖。
The attention mechanism provides a sequential prediction framework for learning spatial models with enhanced implicit temporal consistency. In this work, we show a systematic design (from 2D to 3D) for how conventional networks and other forms of constraints can be incorporated into the attention framework for learning long-range dependencies for the task of pose estimation. The contribution of this paper is to provide a systematic approach for designing and training of attention-based models for the end-to-end pose estimation, with the flexibility and scalability of arbitrary video sequences as input. We achieve this by adapting temporal receptive field via a multi-scale structure of dilated convolutions. Besides, the proposed architecture can be easily adapted to a causal model enabling real-time performance. Any off-the-shelf 2D pose estimation systems, e.g. Mocap libraries, can be easily integrated in an ad-hoc fashion. Our method achieves the state-of-the-art performance and outperforms existing methods by reducing the mean per joint position error to 33.4 mm on Human3.6M dataset.
https://weibo.com/1402400261/K52hk4f2o




另外几篇值得关注的论文:
[CV] Energy-Based Learning for Scene Graph Generation
场景图生成的基于能量学习
M Suhail, A Mittal, B Siddiquie, C Broaddus, J Eledath, G Medioni, L Sigal
[University of British Columbia & Amazon]
https://weibo.com/1402400261/K52luCqyW


[CV] Single-Shot Motion Completion with Transformer
基于Transformer的单样本运动补全
Y Duan, T Shi…
[NetEase & University of Michigan]
https://weibo.com/1402400261/K52pA8mTA



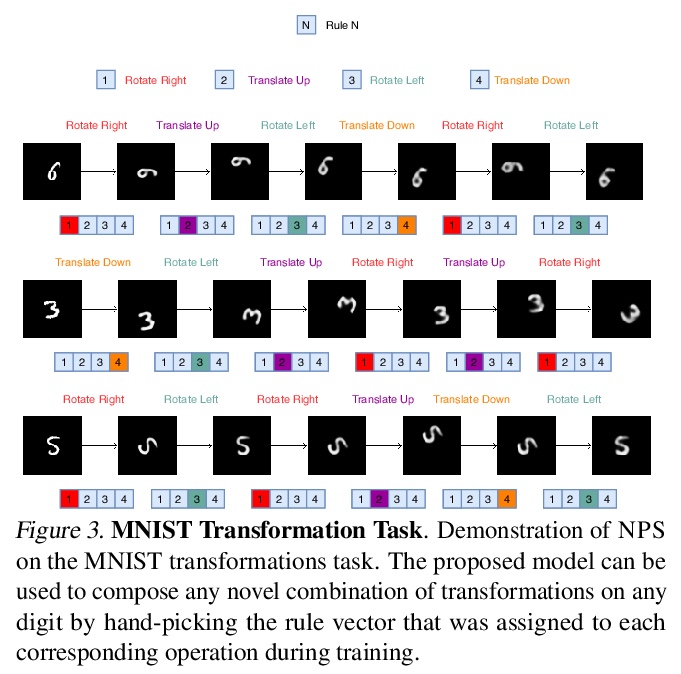
[AI] Neural Production Systems
神经产生式系统
A Goyal, A Didolkar, N R Ke, C Blundell, P Beaudoin, N Heess, M Mozer, Y Bengio
[Mila & Deepmind & Waverly & Google Brain]
https://weibo.com/1402400261/K52slzIyo


[IR] Simplified Data Wrangling with ir_datasets
用ir_datasets简化数据整理
S MacAvaney, A Yates, S Feldman, D Downey, A Cohan, N Goharian
[University of Glasgow & Max Planck Institute for Informatics & Allen Institute for AI & Georgetown University]
https://weibo.com/1402400261/K52vtqm00




若有收获,就点个赞吧
0 人点赞
