LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、**[LG] WILDS: A Benchmark of in-the-Wild Distribution Shifts
P W Koh, S Sagawa, H Marklund, S M Xie, M Zhang, A Balsubramani, W Hu, M Yasunaga, R L Phillips, S Beery, J Leskovec, A Kundaje, E Pierson, S Levine, C Finn, P Liang
[Stanford University]
WILDS:实际场景分布漂移基准。提出WILDS实际场景分布漂移基准,涵盖不同数据模式和应用,从肿瘤识别到野生动物监测、贫困图谱。WILDS基于领域专家最近的数据收集工作,提供统一数据集,以及代表真实世界分布漂移的评价指标和训练集、测试集分割。这些数据集反映了不同医院、不同相机、不同国家、不同时间段、不同人口情况、不同分子骨架摸板,在训练和测试时产生的分布漂移,这些漂移会导致基线模型性能的大幅下降。**
Distribution shifts can cause significant degradation in a broad range of machine learning (ML) systems deployed in the wild. However, many widely-used datasets in the ML community today were not designed for evaluating distribution shifts. These datasets typically have training and test sets drawn from the same distribution, and prior work on retrofitting them with distribution shifts has generally relied on artificial shifts that need not represent the kinds of shifts encountered in the wild. In this paper, we present WILDS, a benchmark of in-the-wild distribution shifts spanning diverse data modalities and applications, from tumor identification to wildlife monitoring to poverty mapping. WILDS builds on top of recent data collection efforts by domain experts in these applications and provides a unified collection of datasets with evaluation metrics and train/test splits that are representative of real-world distribution shifts. These datasets reflect distribution shifts arising from training and testing on different hospitals, cameras, countries, time periods, demographics, molecular scaffolds, etc., all of which cause substantial performance drops in our baseline models. Finally, we survey other applications that would be promising additions to the benchmark but for which we did not manage to find appropriate datasets; we discuss their associated challenges and detail datasets and shifts where we did not see an appreciable performance drop. By unifying datasets from a variety of application areas and making them accessible to the ML community, we hope to encourage the development of general-purpose methods that are anchored to real-world distribution shifts and that work well across different applications and problem settings. Data loaders, default models, and leaderboards are available at > this https URL.
https://weibo.com/1402400261/JzhkGi4zb
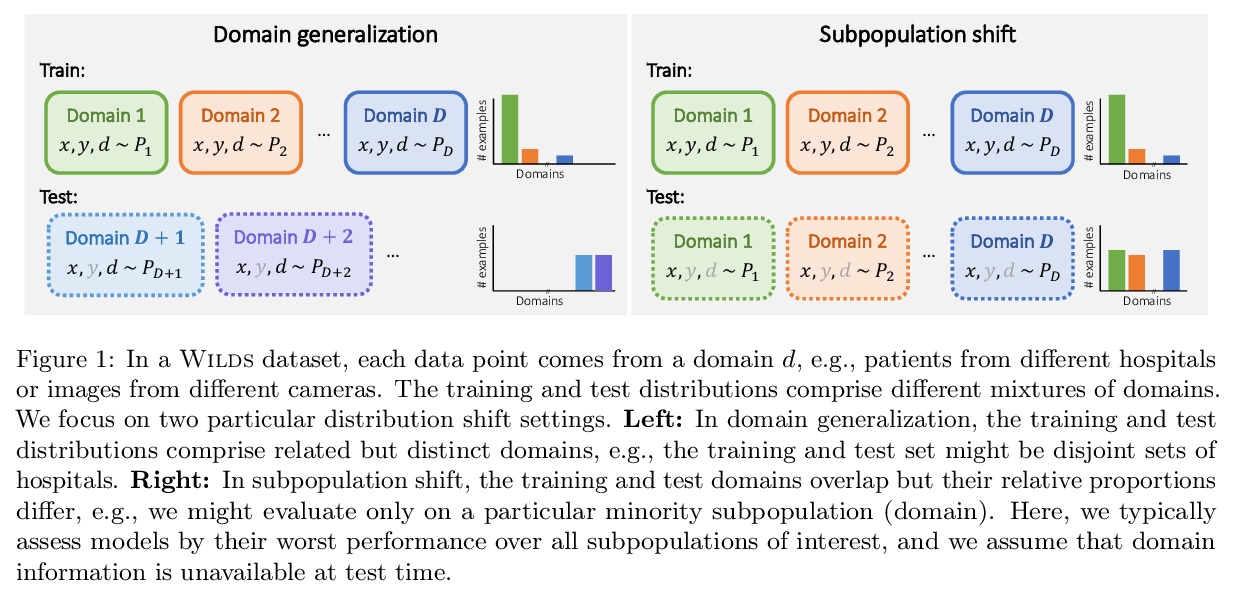
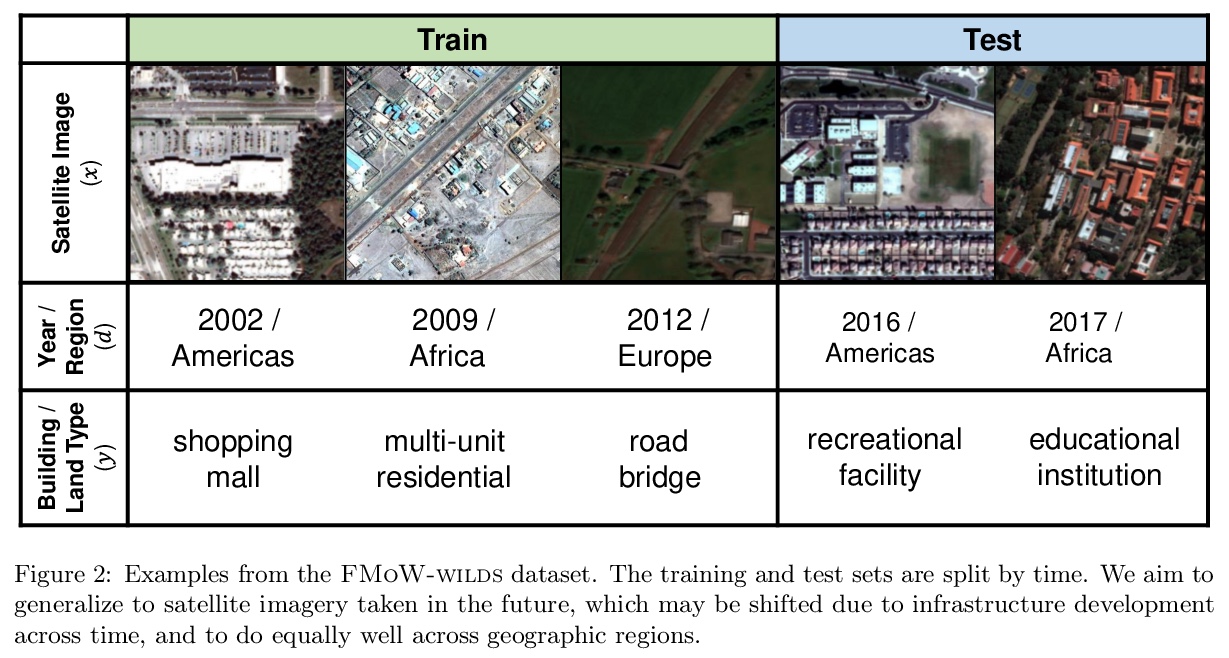
2、** **[CV] Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation
G Ghiasi, Y Cui, A Srinivas, R Qian, T Lin, E D. Cubuk, Q V. Le, B Zoph
[Google Research]
简单复制-粘贴是实例分割数据增强的有效方法。对复制-粘贴增强进行了系统研究,将对象随机粘贴到图像上,发现这样的简单机制是非常有效和鲁棒的,能在强大的基线基础上提供稳定的收益。复制-粘贴增强在多个实验设置中表现良好,在COCO和LVIS实例分割基准上提供了显著的改进。复制-粘贴增强策略简单易行,可插入到任意实例分割代码,且不会增加训练成本或推理时间。
Building instance segmentation models that are data-efficient and can handle rare object categories is an important challenge in computer vision. Leveraging data augmentations is a promising direction towards addressing this challenge. Here, we perform a systematic study of the Copy-Paste augmentation ([13, 12]) for instance segmentation where we randomly paste objects onto an image. Prior studies on Copy-Paste relied on modeling the surrounding visual context for pasting the objects. However, we find that the simple mechanism of pasting objects randomly is good enough and can provide solid gains on top of strong baselines. Furthermore, we show Copy-Paste is additive with semi-supervised methods that leverage extra data through pseudo labeling (e.g. self-training). On COCO instance segmentation, we achieve 49.1 mask AP and 57.3 box AP, an improvement of +0.6 mask AP and +1.5 box AP over the previous state-of-the-art. We further demonstrate that Copy-Paste can lead to significant improvements on the LVIS benchmark. Our baseline model outperforms the LVIS 2020 Challenge winning entry by +3.6 mask AP on rare categories.
https://weibo.com/1402400261/Jzhtv02fS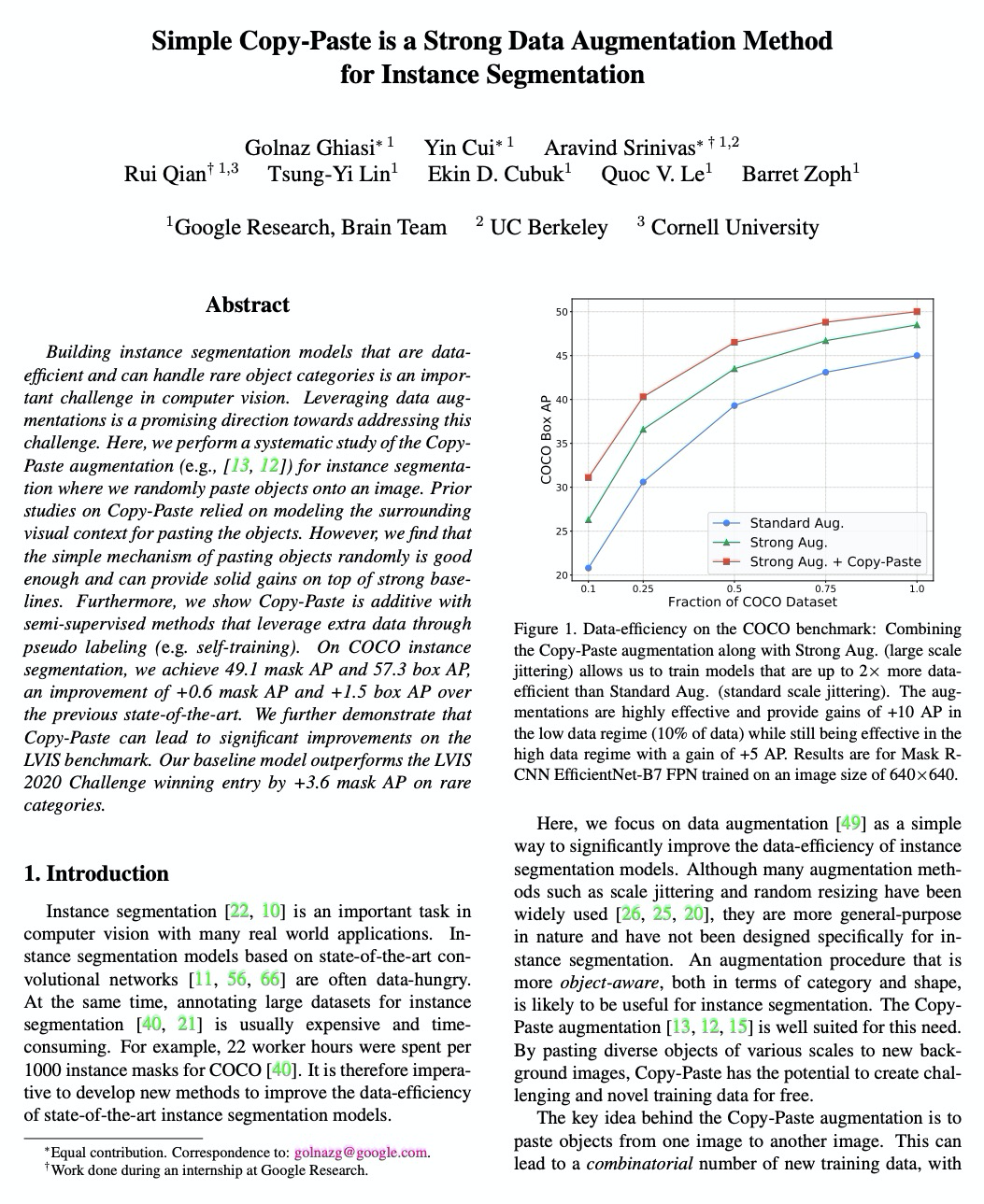


3、** **[LG] When is Memorization of Irrelevant Training Data Necessary for High-Accuracy Learning?
G Brown, M Bun, V Feldman, A Smith, K Talwar
[Boston University & Apple]
对看似无关训练数据的记忆是否是高精度学习的必要条件?现代机器学习模型非常复杂,经常要对输入中惊人数量的信息进行编码。极端情况下,复杂模型似乎能记住所有输入样本,包括看似无关的信息(例如,文本中包含的社会保险号码)。本文旨在研究这种记忆是否是准确学习所必需的。描述了自然预测问题,预测模型中每个足够精确的训练算法,都必须编码训练样本一个大子集的所有信息。即使样本是高维的、熵比样本大小大得多,即使大部分信息基本上跟手头的任务无关,情况依然如此,且与训练算法或用于学习的模型类别无关。
Modern machine learning models are complex and frequently encode surprising amounts of information about individual inputs. In extreme cases, complex models appear to memorize entire input examples, including seemingly irrelevant information (social security numbers from text, for example). In this paper, we aim to understand whether this sort of memorization is necessary for accurate learning. We describe natural prediction problems in which every sufficiently accurate training algorithm must encode, in the prediction model, essentially all the information about a large subset of its training examples. This remains true even when the examples are high-dimensional and have entropy much higher than the sample size, and even when most of that information is ultimately irrelevant to the task at hand. Further, our results do not depend on the training algorithm or the class of models used for learning.Our problems are simple and fairly natural variants of the next-symbol prediction and the cluster labeling tasks. These tasks can be seen as abstractions of image- and text-related prediction problems. To establish our results, we reduce from a family of one-way communication problems for which we prove new information complexity lower bounds.
https://weibo.com/1402400261/JzhyDzwyF
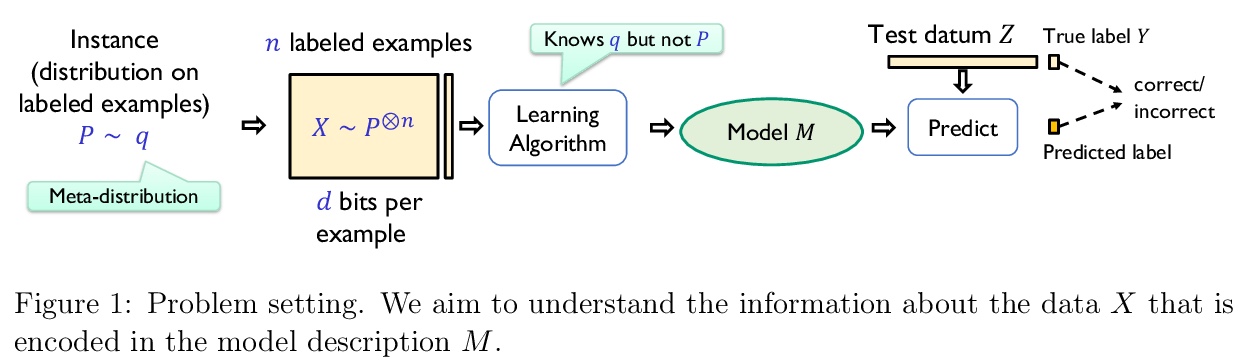
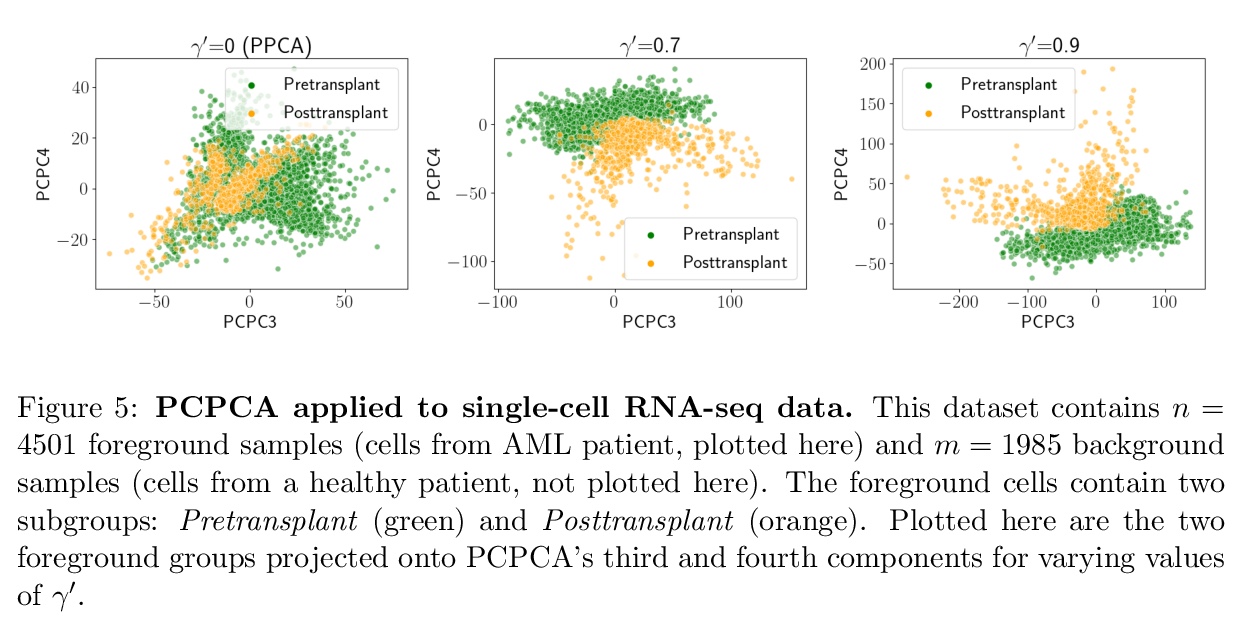
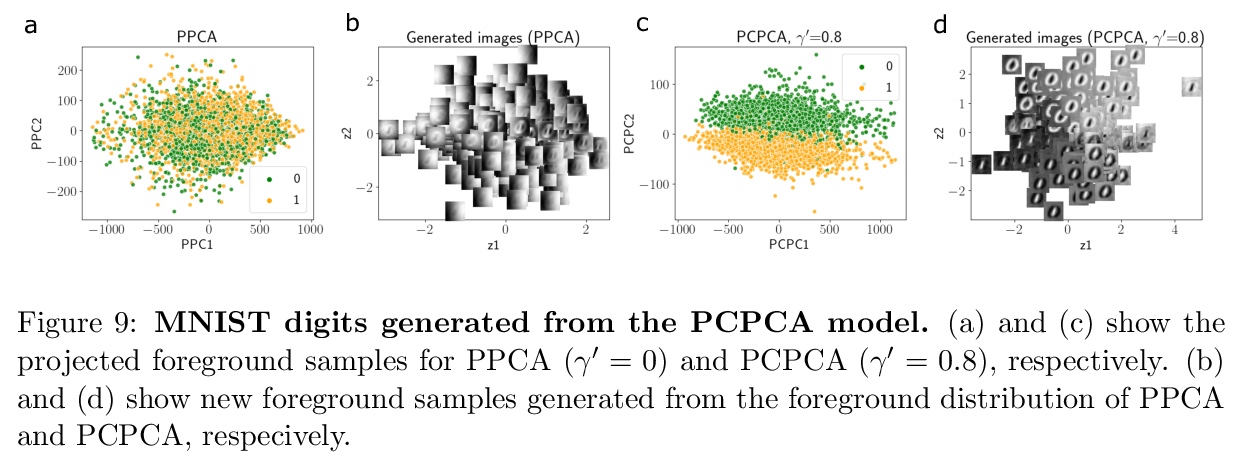
4、** **[ME] Probabilistic Contrastive Principal Component Analysis
D Li, A Jones, B Engelhardt
[Princeton University]
概率对比主成分分析。提出可替代CPCA的概率模型PCPCA,用于学习前景数据集和背景数据集间的对比维度。与CPCA相比,基于模型的方法具有更强的可解释性、对不确定性的量化性、对噪声和缺失数据的鲁棒性,以及从模型生成数据的能力。推导了一种仅依赖观测数据的梯度下降算法。通过蛋白质表达、基因表达和图像数据上的实验,展示了PCPCA在不同应用中的性能,PCPCA在捕获子群结构、对噪声和缺失数据的鲁棒性方面优于PPCA和CPCA。
Dimension reduction is useful for exploratory data analysis. In many applications, it is of interest to discover variation that is enriched in a “foreground” dataset relative to a “background” dataset. Recently, contrastive principal component analysis (CPCA) was proposed for this setting. However, the lack of a formal probabilistic model makes it difficult to reason about CPCA and to tune its hyperparameter. In this work, we propose probabilistic contrastive principal component analysis (PCPCA), a model-based alternative to CPCA. We discuss how to set the hyperparameter in theory and in practice, and we show several of PCPCA’s advantages, including greater interpretability, uncertainty quantification, robustness to noise and missing data, and the ability to generate data from the model. We demonstrate PCPCA’s performance through a series of simulations and experiments with datasets of gene expression, protein expression, and images.
https://weibo.com/1402400261/JzhGEfG5I
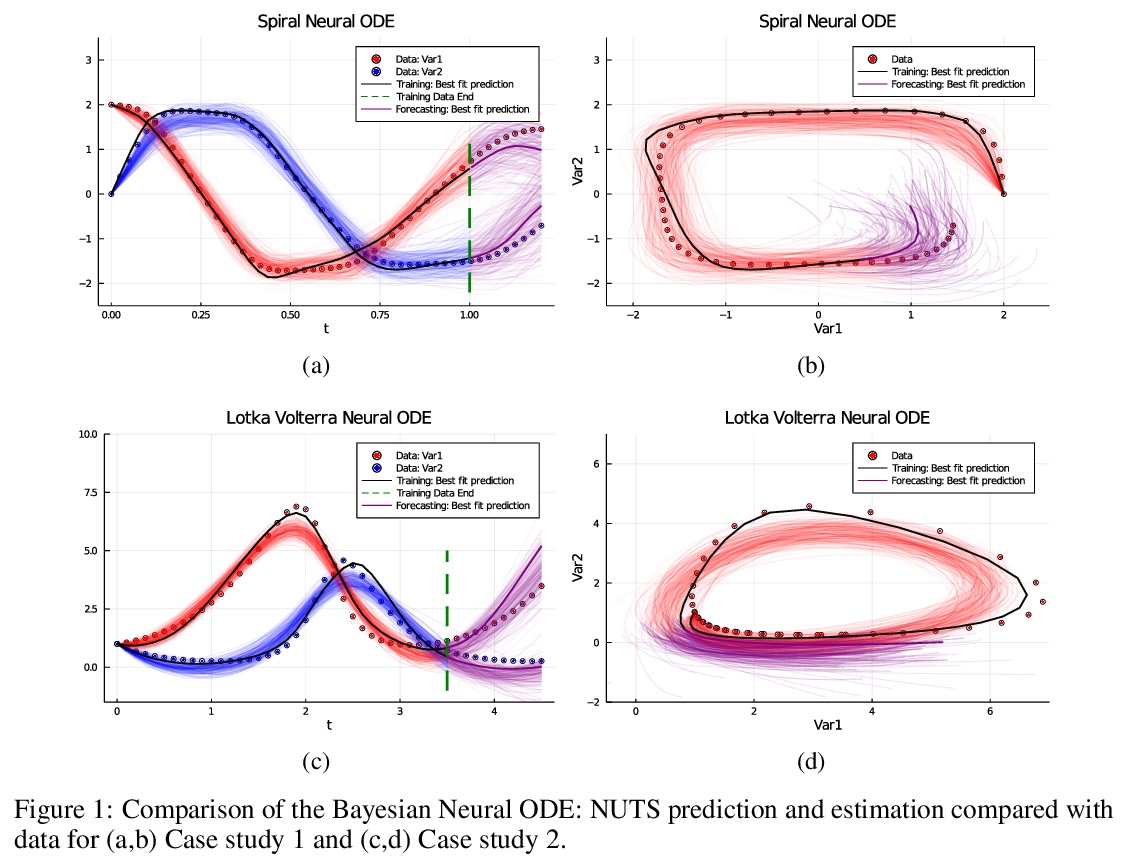
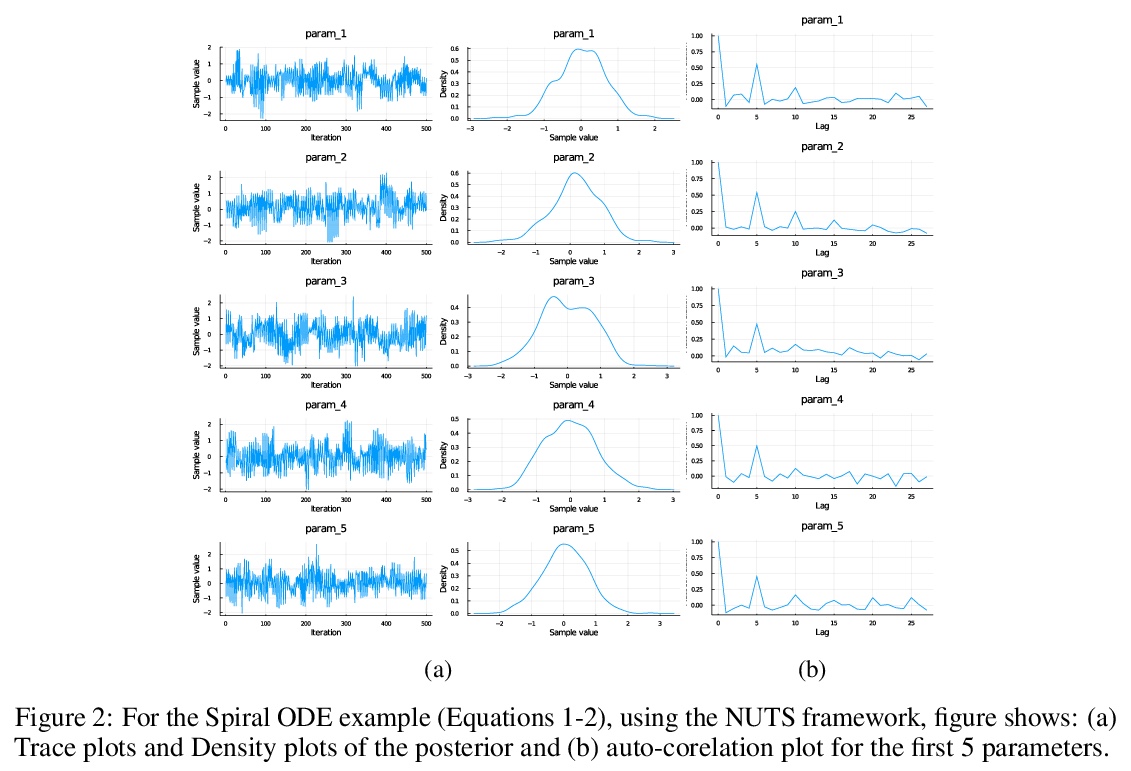
5、**[LG] Bayesian Neural Ordinary Differential Equations
R Dandekar, V Dixit, M Tarek, A Garcia-Valadez, C Rackauckas
[MIT & Julia Computing Inc & University of New South Wales at Canberra & National Autonomous University of Mexico]
贝叶斯神经常微分方程。展示了贝叶斯学习框架与神经网络常微分方程(Neural ODE)的成功结合,用No-U-Turn MCMC采样器(NUTS)和随机Langevin梯度下降(SGLD)两种采样方法,量化神经网络ODE的权重的不确定性。用GPU加速在经典物理系统及MNIST等标准机器学习数据集上,测试了贝叶斯神经常微分方程方法的性能。**
Recently, Neural Ordinary Differential Equations has emerged as a powerful framework for modeling physical simulations without explicitly defining the ODEs governing the system, but learning them via machine learning. However, the question: Can Bayesian learning frameworks be integrated with Neural ODEs to robustly quantify the uncertainty in the weights of a Neural ODE? remains unanswered. In an effort to address this question, we demonstrate the successful integration of Neural ODEs with two methods of Bayesian Inference: (a) The No-U-Turn MCMC sampler (NUTS) and (b) Stochastic Langevin Gradient Descent (SGLD). We test the performance of our Bayesian Neural ODE approach on classical physical systems, as well as on standard machine learning datasets like MNIST, using GPU acceleration. Finally, considering a simple example, we demonstrate the probabilistic identification of model specification in partially-described dynamical systems using universal ordinary differential equations. Together, this gives a scientific machine learning tool for probabilistic estimation of epistemic uncertainties.
https://weibo.com/1402400261/JzhLXqhI5
另外几篇值得关注的论文:
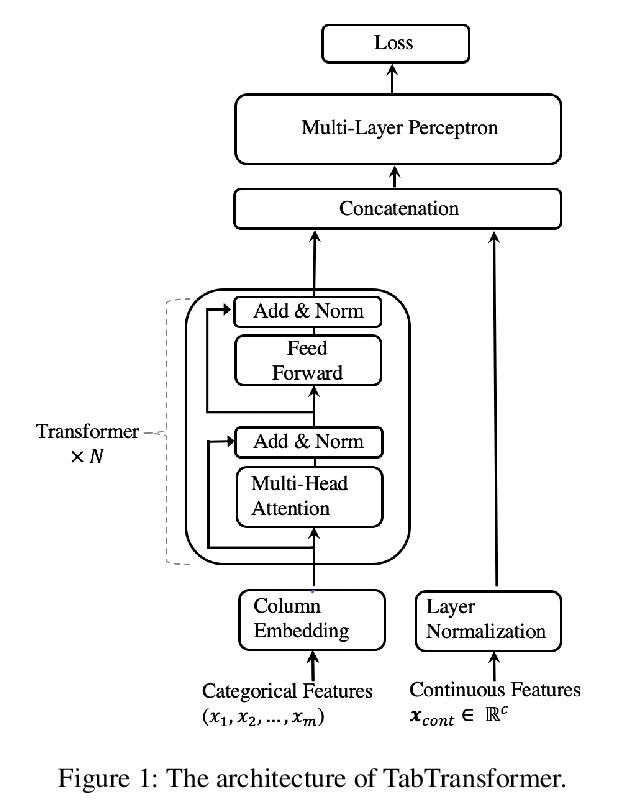
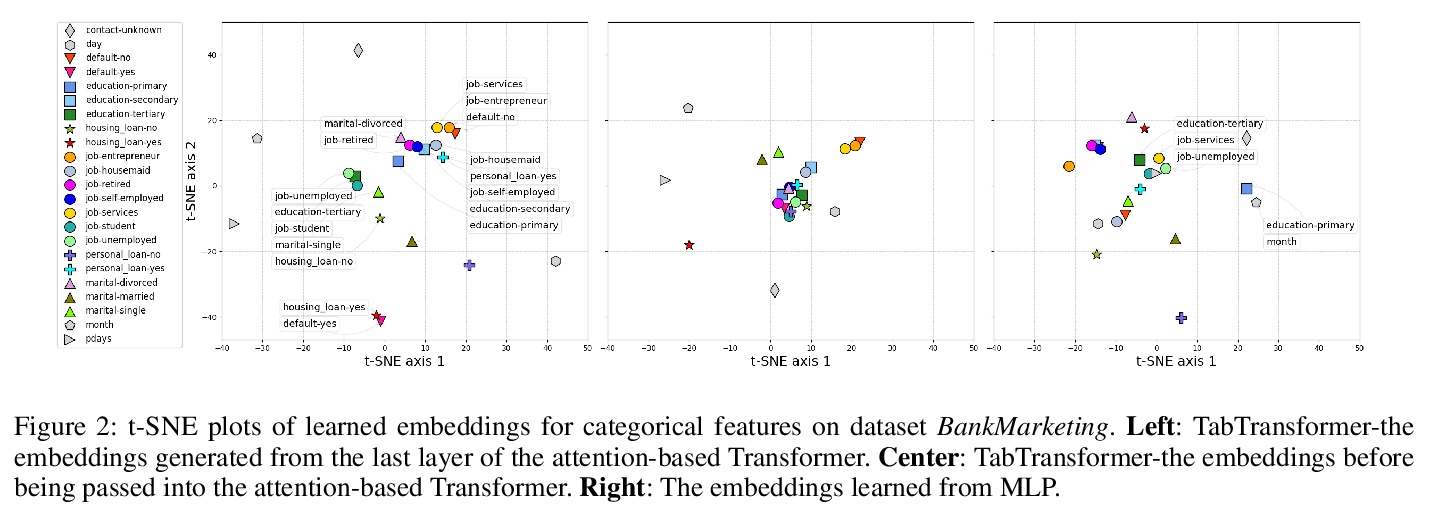
[LG] TabTransformer: Tabular Data Modeling Using Contextual Embeddings
TabTransformer:基于上下文嵌入的表格数据建模
X Huang, A Khetan, M Cvitkovic, Z Karnin
[Amazon AWS & PostEra]
https://weibo.com/1402400261/JzhRBzHlC
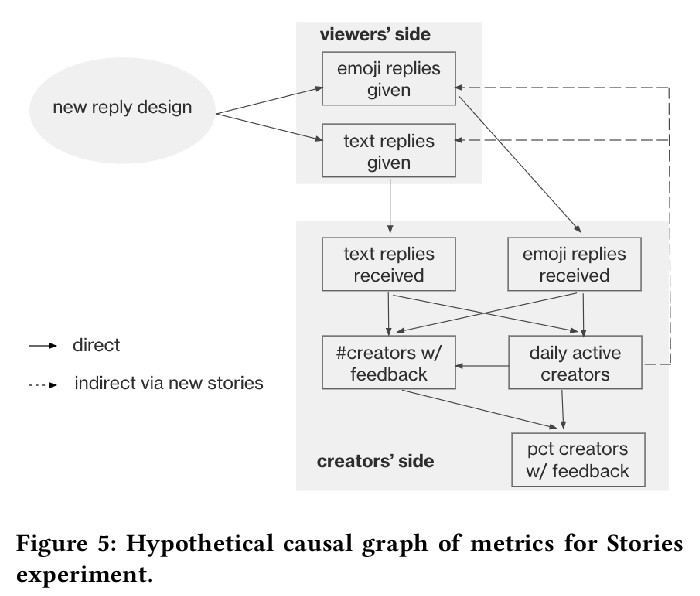
[SI] Network experimentation at scale
Facebook大规模网络实验
B Karrer, L Shi, M Bhole, M Goldman, T Palmer, C Gelman, M Konutgan, F Sun
[Facebook]
https://weibo.com/1402400261/JzhTHyuwk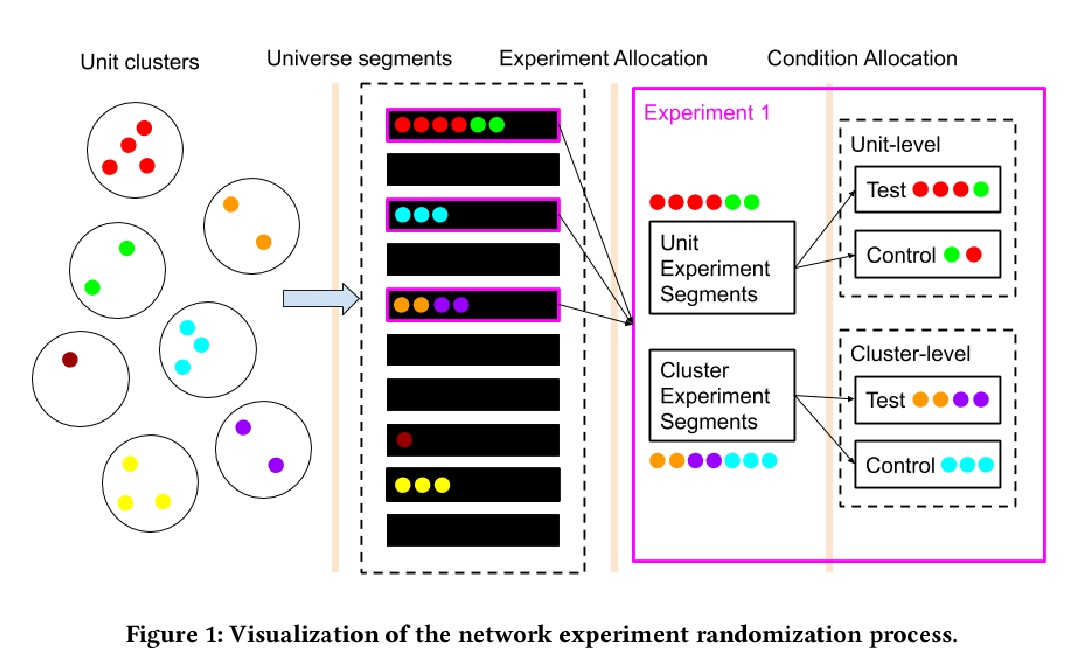
[SI] Analysing the Social Spread of Behaviour: Integrating Complex Contagions into Network Based Diffusions
社会化行为传播分析:将复杂扩散整合到网络传播中
J A. Firth, G F. Albery, K B. Beck, I Jarić, L G. Spurgin, B C. Sheldon, W Hoppitt
[Oxford University & Georgetown University] 

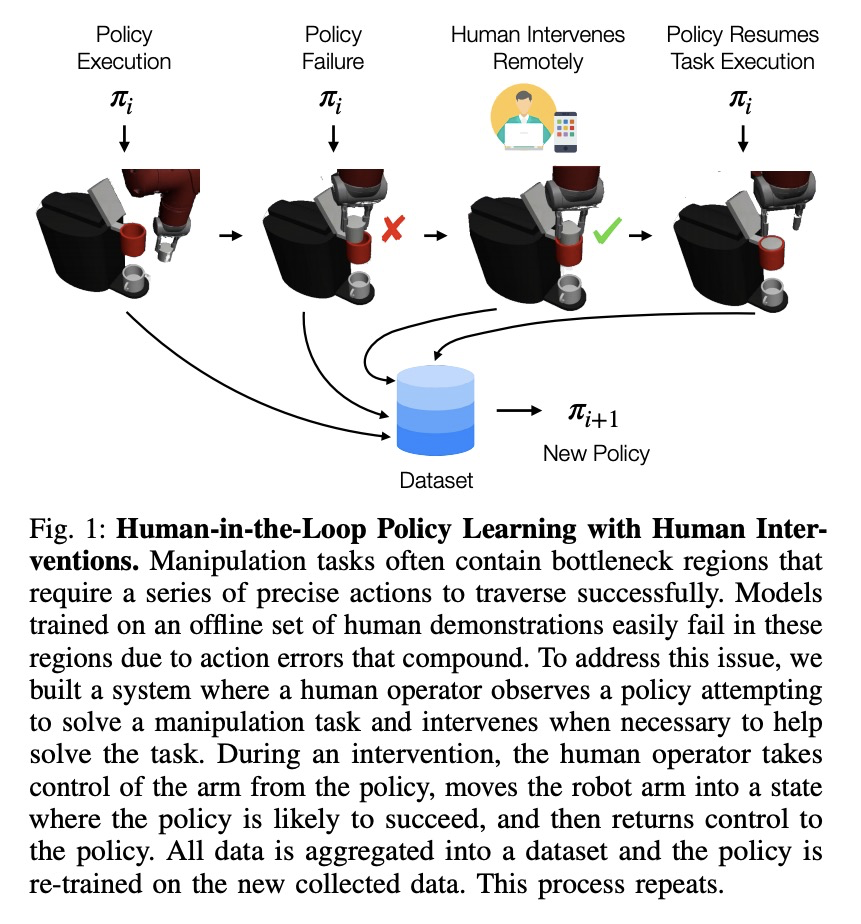
[RO] Human-in-the-Loop Imitation Learning using Remote Teleoperation
基于远程遥操作的人在回路模仿学习
A Mandlekar, D Xu, R Martín-Martín, Y Zhu, L Fei-Fei, S Savarese
[Stanford Vision & Learning Lab & The University of Texas at Austin]
https://weibo.com/1402400261/JzhY38qVZ


若有收获,就点个赞吧
0 人点赞
