数据地址
百度:https://yuedu.baidu.com/partner/view/ptpress2013?fr=pidx
豆瓣:https://book.douban.com/latest
两个地址的区别
豆瓣简单但是不能请求数据过快会封ip,页面简单
百度页面有点复杂,公共类名多,且需要编码转换,而且有些地方显示的信息与页面有差距
技术点
axios —请求数据
cheerio — 转化为html
jquery — 选择元素
iconv-ilte — 编码转换
Promise — promise的使用
难点说的百度并不是豆瓣
数据请求的难点:
解决办法
网页字符集怎吗看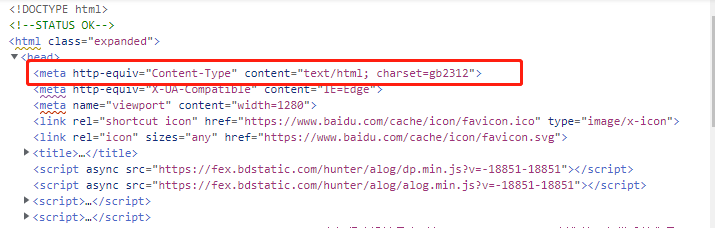
如图百度的网页使用的是 gb2312字符集 我要让response的响应数据格式为 arraybuffer 然后使用插件 iconv-ilte 这是字符编码转换插件
代码
const html = await axios.get(url, { responseType: 'arraybuffer' }).then((res) => {const str = iconv.decode(Buffer.from(res.data), 'gb2312');return iconv.encode(str, 'utf8').toString('utf8');});
cheerio与jquery 的难点
cheerio生成的HTML结构需要使用jq选择,但是cheerio不老实,自己又封装啦其他方法,例如获取元素上的属性 jq的是 attr 而cheerio中的是 attribs ,还有是不是想一下这是cheerio中的元素,还是用jq选择的元素
Promise.all的使用
之前我从诶使用过 promise.all() 这个api,了解是了解但是并没有用于项目中,我使用这个看最后是否把所有书籍信息拿回来,但是又要使用延迟,防止被封ip地址
解决方案
/*** 获取每一个书籍的信息*/async function fetchALL() {const list = await getLinks(); // 获取每本的url 存放与数组中const proms =[];// 遍历数组 拿取书籍详细信息for (let i = 0; i < list.length; i++) {proms.push(new Promise((res,rej) => {// 防止封ip 使用随机毫秒数setTimeout( () => {// 拿取当前书籍的详细信息const data = getBookInfo(list[i]);// 是否真的拿到if(data){res(data)} else {rej(data)}}, randomTimeout); // 随机毫秒数}))}// 全拿到才会返回数据,不然返回错误return Promise.all(proms)}
jq选择元素 元素与节点
由于百度使用公共类名过多会导致选错元素,以及有些元素没有类名。
有时候通过获取元素是获取不到想要的信息,需要元素+ 节点获取想要的信息,对节点操控很少,今天遇见啦。
const $ = cheerio.load(html); // 生成html结构const imgurl = $('img.doc-info-img').attr('src'); // 获取书籍图片地址const name = $('.content-block h1.book-title').attr('title');// 获取书籍名const author = $('a.doc-info-field-val.doc-info-author-link').text(); // 获取作者const list = $('.book-information-tip'); // 获取书籍信息// 查找文本为出版时间的元素const publishSpan = list.filter((i, ele) => {return $(ele).text().includes('出版时间:');});// 获取书籍出版时间 时间是在出版时间后面的文本节点const publishDate = publishSpan[0] ? publishSpan[0].nextSibling.nodeValue.trim() : ' ';
完整代码-百度
const axios = require('axios');const cheerio = require('cheerio');const Book = require('../models/Book')/*** 网页编码转换*/const iconv = require('iconv-lite');/*** 获取网页HTML*/async function getBooksHTML() {const res = await axios.get('https://yuedu.baidu.com/partner/view/ptpress2013?fr=pidx');return res.data;}/*** 获取图书链接*/async function getLinks() {const html = await getBooksHTML();const $ = cheerio.load(html);const list = $('.booklist-inner .book a.img-block');const listArr = list.map((i, ele) => {const url = 'https://yuedu.baidu.com' + ele.attribs['href'];return url;}).get();return listArr;}/*** 获取图书的详情*/async function getBookInfo(url) {const html = await axios.get(url, { responseType: 'arraybuffer' }).then((res) => {const str = iconv.decode(Buffer.from(res.data), 'gb2312');return iconv.encode(str, 'utf8').toString('utf8');});const $ = cheerio.load(html); // 生成html结构const imgurl = $('img.doc-info-img').attr('src'); // 获取书籍图片地址const name = $('.content-block h1.book-title').attr('title');// 获取书籍名const author = $('a.doc-info-field-val.doc-info-author-link').text(); // 获取作者const list = $('.book-information-tip'); // 获取书籍信息// 查找文本为出版时间的元素const publishSpan = list.filter((i, ele) => {return $(ele).text().includes('出版时间:');});// 获取书籍出版时间 时间是在出版时间后面的文本节点const publishDate = publishSpan[0] ? publishSpan[0].nextSibling.nodeValue.trim() : ' ';return {name,imgurl,publishDate,author,};}/*** 获取每一个书籍的信息*/async function fetchALL() {const list = await getLinks(); // 获取每本的url 存放与数组中const proms =[];// 遍历数组 拿取书籍详细信息for (let i = 0; i < list.length; i++) {proms.push(new Promise((res,rej) => {// 防止封ip 使用随机毫秒数setTimeout( () => {// 拿取当前书籍的详细信息const data = getBookInfo(list[i]);// 是否真的拿到if(data){res(data)} else {rej(data)}}, randomTimeout);}))}// 全拿到才会返回数据,不然返回错误return Promise.all(proms)}/*** 随机时间*/function randomTimeout() {return Math.floor(Math.random() * 10000);}/*** 保存到数据库*/async function saveToDB() {const res = await fetchALL();Book.bulkCreate(res);console.log('数据保存成功')}saveToDB();
待完善代码-豆瓣
由于豆瓣未做间隔请求数据被封ip,就只能搁置啦
const axios = require('axios');const cheerio = require('cheerio');/*** 获取豆瓣读书页面的html*/async function getBooksHTML() {const res = await axios.get('https://book.douban.com/latest');return res.data;}/*** 获取书籍的详情链接*/async function getBooksLinks() {const html = await getBooksHTML();console.log(html, 'html')const $ = cheerio.load(html);const len = $('#content .grid-12-12 li a.cover');const linkArr = len.map((i, ele) => {const href = ele.attribs['href'];return href;}).get();console.log(linkArr, 'linkArr');return linkArr}/*** 获取书籍详情页面的数据*/async function getBookInfo(url) {const res = await axios(url);const $ = cheerio.load(res.data);const name = $('h1').text().trim();const imgurl = $('#mainpic .nbg img').attr('src');const pl = $('#info span.pl')const authorSpan = pl.filter((i, ele) => {return $(ele).text().includes('作者')})const author = $(authorSpan).next().text().trim()const publishSpan = pl.filter((i, ele) => {return $(ele).text().includes('出版年')})const pluginsDate = publishSpan[0] ? publishSpan[0].nextSibling.nodeValue.trim() : ' ';return {name,imgurl,pluginsDate,author}}/*** 获取每一本书的信息*/async function fetchALL () {const links = await getBooksLinks()const booksInfo = links.map( (ele) => {// 由于此处未做间隔请求数据被封ip啦return getBookInfo(ele)});return Promise.all(booksInfo)}/*** 将书籍信息写入到数据可*/async function saveToDB() {const data = await fetchALL();console.log(data, 'data')}saveToDB()

若有收获,就点个赞吧
0 人点赞
