Java 类名:com.alibaba.alink.operator.batch.clustering.KMeansTrainBatchOp
Python 类名:KMeansTrainBatchOp
功能介绍
Kmeans算法的训练组件。KMeans是一个经典的聚类算法。该算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近它们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
距离度量方式
| 参数名称 | 参数描述 | 说明 | | —- | —- | —- |
|
EUCLIDEAN
|  | 欧式距离
|
| 欧式距离
|
|
COSINE
| 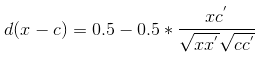 | 夹角余弦距离
|
| 夹角余弦距离
|
参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 | | —- | —- | —- | —- | —- | —- | —- |
| vectorCol | 向量列名 | 向量列对应的列名 | String | ✓ | 所选列类型为 [DENSE_VECTOR, SPARSE_VECTOR, STRING, VECTOR] | |
| distanceType | 距离度量方式 | 聚类使用的距离类型 | String | | “EUCLIDEAN”, “COSINE” | “EUCLIDEAN” |
| epsilon | 收敛阈值 | 当两轮迭代的中心点距离小于epsilon时,算法收敛。 | Double | | | 1.0E-4 |
| initMode | 中心点初始化方法 | 初始化中心点的方法,支持”K_MEANS_PARALLEL”和”RANDOM” | String | | “RANDOM”, “K_MEANS_PARALLEL” | “RANDOM” |
| initSteps | k-means++初始化迭代步数 | k-means初始化中心点时迭代的步数 | Integer | | | 2 |
| k | 聚类中心点数量 | 聚类中心点数量 | Integer | | | 2 |
| maxIter | 最大迭代步数 | 最大迭代步数,默认为 50。 | Integer | | | 50 |
| randomSeed | 随机数种子 | 随机数种子 | Integer | | | 0 |
代码示例
Python 代码
from pyalink.alink import *import pandas as pduseLocalEnv(1)df = pd.DataFrame([[0, "0 0 0"],[1, "0.1,0.1,0.1"],[2, "0.2,0.2,0.2"],[3, "9 9 9"],[4, "9.1 9.1 9.1"],[5, "9.2 9.2 9.2"]])inOp1 = BatchOperator.fromDataframe(df, schemaStr='id int, vec string')inOp2 = StreamOperator.fromDataframe(df, schemaStr='id int, vec string')kmeans = KMeansTrainBatchOp()\.setVectorCol("vec")\.setK(2)\.linkFrom(inOp1)kmeans.lazyPrint(10)predictBatch = KMeansPredictBatchOp()\.setPredictionCol("pred")\.linkFrom(kmeans, inOp1)predictBatch.print()predictStream = KMeansPredictStreamOp(kmeans)\.setPredictionCol("pred")\.linkFrom(inOp2)predictStream.print()StreamOperator.execute()
Java 代码
import org.apache.flink.types.Row;import com.alibaba.alink.operator.batch.BatchOperator;import com.alibaba.alink.operator.batch.clustering.KMeansPredictBatchOp;import com.alibaba.alink.operator.batch.clustering.KMeansTrainBatchOp;import com.alibaba.alink.operator.batch.source.MemSourceBatchOp;import com.alibaba.alink.operator.stream.StreamOperator;import com.alibaba.alink.operator.stream.clustering.KMeansPredictStreamOp;import com.alibaba.alink.operator.stream.source.MemSourceStreamOp;import org.junit.Test;import java.util.Arrays;import java.util.List;public class KMeansTrainBatchOpTest {@Testpublic void testKMeansTrainBatchOp() throws Exception {List <Row> df = Arrays.asList(Row.of(0, "0 0 0"),Row.of(1, "0.1,0.1,0.1"),Row.of(2, "0.2,0.2,0.2"),Row.of(3, "9 9 9"),Row.of(4, "9.1 9.1 9.1"),Row.of(5, "9.2 9.2 9.2"));BatchOperator <?> inOp1 = new MemSourceBatchOp(df, "id int, vec string");StreamOperator <?> inOp2 = new MemSourceStreamOp(df, "id int, vec string");BatchOperator <?> kmeans = new KMeansTrainBatchOp().setVectorCol("vec").setK(2).linkFrom(inOp1);kmeans.lazyPrint(10);BatchOperator <?> predictBatch = new KMeansPredictBatchOp().setPredictionCol("pred").linkFrom(kmeans, inOp1);predictBatch.print();StreamOperator <?> predictStream = new KMeansPredictStreamOp(kmeans).setPredictionCol("pred").linkFrom(inOp2);predictStream.print();StreamOperator.execute();}}
运行结果
模型结果
| model_id | model_info | | —- | —- |
| 0 | {“vectorCol”:””vec””,”latitudeCol”:null,”longitudeCol”:null,”distanceType”:””EUCLIDEAN””,”k”:”2”,”vectorSize”:”3”} |
| 1048576 | {“clusterId”:0,”weight”:3.0,”vec”:{“data”:[9.099999999999998,9.099999999999998,9.099999999999998]}} |
| 2097152 | {“clusterId”:1,”weight”:3.0,”vec”:{“data”:[0.1,0.1,0.1]}} |
预测结果
| id | vec | pred | | —- | —- | —- |
| 0 | 0 0 0 | 1 |
| 1 | 0.1,0.1,0.1 | 1 |
| 2 | 0.2,0.2,0.2 | 1 |
| 3 | 9 9 9 | 0 |
| 4 | 9.1 9.1 9.1 | 0 |
| 5 | 9.2 9.2 9.2 | 0 |

若有收获,就点个赞吧
0 人点赞
