Java 类名:com.alibaba.alink.operator.batch.outlier.DbscanOutlierBatchOp
Python 类名:DbscanOutlierBatchOp
功能介绍
DBSCAN,Density-Based Spatial Clustering of Applications with Noise,是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
基于DBSCAN聚类的异常检测算法将规模过小的簇视为异常。
使用方法
使用DBSCAN算法进行异常检测需要设置聚类半径,距离计算方法和簇最小规模。
当聚类半径设为0.1,用欧氏距离度量,簇最小规模为3时,如图是DBSCAN算法的异常检测效果,
距离度量方式
| 参数名称 | 参数描述 | 说明 |
|---|---|---|
| EUCLIDEAN |  |
欧式距离 |
| COSINE | 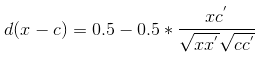 |
夹角余弦距离 |
| CITYBLOCK |  = \vert x-c\vert) = \vert x-c\vert) |
街区距离 |
参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
|---|---|---|---|---|---|---|
| predictionCol | 预测结果列名 | 预测结果列名 | String | ✓ | ||
| distanceType | 距离度量方式 | 聚类使用的距离类型 | String | “EUCLIDEAN”, “COSINE”, “INNERPRODUCT”, “CITYBLOCK”, “JACCARD”, “PEARSON” | “EUCLIDEAN” | |
| featureCols | 特征列名数组 | 特征列名数组,默认全选 | String[] | 所选列类型为 [BIGDECIMAL, BIGINTEGER, BYTE, DOUBLE, FLOAT, INTEGER, LONG, SHORT] | null | |
| groupCols | 分组列名数组 | 分组列名,多列,可选,默认不选 | String[] | null | ||
| maxOutlierNumPerGroup | 每组最大异常点数目 | 每组最大异常点数目 | Integer | |||
| maxOutlierRatio | 最大异常点比例 | 算法检测异常点的最大比例 | Double | |||
| maxSampleNumPerGroup | 每组最大样本数目 | 每组最大样本数目 | Integer | |||
| outlierThreshold | 异常评分阈值 | 只有评分大于该阈值才会被认为是异常点 | Double | |||
| predictionDetailCol | 预测详细信息列名 | 预测详细信息列名 | String | |||
| tensorCol | tensor列 | tensor列 | String | 所选列类型为 [BOOL_TENSOR, BYTE_TENSOR, DOUBLE_TENSOR, FLOAT_TENSOR, INT_TENSOR, LONG_TENSOR, STRING, STRING_TENSOR, TENSOR, UBYTE_TENSOR] | null | |
| vectorCol | 向量列名 | 向量列对应的列名,默认值是null | String | 所选列类型为 [DENSE_VECTOR, SPARSE_VECTOR, STRING, VECTOR] | null | |
| numThreads | 组件多线程线程个数 | 组件多线程线程个数 | Integer | 1 |
代码示例
Python 代码
JAVA 代码

若有收获,就点个赞吧
0 人点赞
