🚩传送门:牛客题目
题目
请实现两个函数,分别用来序列化和反序列化二叉树。
你需要设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
示例:![[NC]123. 序列化二叉树 - 图1](/uploads/projects/mylearn@leetcode/f5907a981739ea0e8d1be5142e1a44d0.jpeg)
输入:root = [1,2,3,null,null,4,5] 输出:[1,2,3,null,null,4,5]
解题思路1:广度优先搜索
通常使用的前序、中序、后序、层序遍历记录的二叉树的信息不完整,即唯一的输出序列可能对应着多种二叉树可能性。题目要求的 序列化 和 反序列化 是 可逆操作 。因此,序列化的字符串应携带 完整的二叉树信息 。
观察题目示例,序列化的字符串实际上是二叉树的 “层序遍历”(BFS)结果,本文也采用层序遍历。
为完整表示二叉树,考虑将叶节点下的 null 也记录。在此基础上,对于列表中任意某节点 node ,其左子节点 node.left 和右子节点 node.right 在序列中的位置都是 唯一确定 的。如下图所示:
详情参考堆的物理性在数组中的下标表示
![[NC]123. 序列化二叉树 - 图2](/uploads/projects/mylearn@leetcode/9bd560230df490af48efe42013f7d1d2.png)
序列化 使用层序遍历实现。反序列化 通过以上递推公式反推各节点在序列中的索引,进而实现。
🚩序列化 Serialize :
借助队列,对二叉树做层序遍历,并将越过叶节点的 null 也打印出来。
🚩反序列化 Deserialize :
基于本文开始推出的 node , node.left , node.right 在序列化列表中的位置关系,可实现反序列化。
利用队列按层构建二叉树,借助一个指针 i 指向节点 node 的左、右子节点,每构建一个 node 的左、右子节点,指针 i 就向右移动 1 位 。
复杂度分析
时间复杂度:![[NC]123. 序列化二叉树 - 图3](/uploads/projects/mylearn@leetcode/ffb9b0524ef92a69fc087b696d4b1e90.svg) ,其中
,其中 ![[NC]123. 序列化二叉树 - 图4](/uploads/projects/mylearn@leetcode/6edc806a2ab0ea014918a3c1f7d31a7e.svg) 为二叉树结点个数。
为二叉树结点个数。
- 序列化阶段:  个二叉树结点个数,层序遍历需要访问所有节点,个数总是为  ,总体复杂度为 。- 反序列化阶段: 个二叉树结点个数,按层构建二叉树需要遍历整个 **vals**,长度最大为 
空间复杂度:![[NC]123. 序列化二叉树 - 图5](/uploads/projects/mylearn@leetcode/2b1304e91dbf826dd714b44cc02d2a93.svg) ,其中
,其中 ![[NC]123. 序列化二叉树 - 图6](/uploads/projects/mylearn@leetcode/2f89b325ac7d9d251a547c12180b8c63.svg) 为二叉树结点个数。
为二叉树结点个数。
- 序列化阶段:  个二叉树结点个数,最差情况下,队列 **queue** 同时存储  个节点 。- 反序列化阶段:  个二叉树结点个数,最差情况下,队列 **queue** 同时存储  个节点 。
官方代码
public class Codec {public String serialize(TreeNode root) {if(root == null) return "[]";StringBuilder res = new StringBuilder("[");Queue<TreeNode> queue = new LinkedList<>() {{ add(root); }};while(!queue.isEmpty()) {TreeNode node = queue.poll();if(node != null) {res.append(node.val).append(",");queue.add(node.left);queue.add(node.right);}else res.append("null,");}res.deleteCharAt(res.length() - 1);res.append("]");return res.toString();}// "[1,2,3,null,null,4,5]"public TreeNode deserialize(String data) {if(data.equals("[]")) return null;String[] vals = data.substring(1, data.length() - 1).split(",");TreeNode root = new TreeNode(Integer.parseInt(vals[0]));Queue<TreeNode> queue = new LinkedList<>() {{ add(root); }};int i = 1;while(!queue.isEmpty()) {TreeNode node = queue.poll();if(!vals[i].equals("null")) { // 左子树不空node.left = new TreeNode(Integer.parseInt(vals[i]));queue.add(node.left);}i++;if(!vals[i].equals("null")) { // 右子树不空node.right = new TreeNode(Integer.parseInt(vals[i]));queue.add(node.right);}i++;}return root;}}
解题思路2:深度优先搜索 [线序为例]
二叉树的序列化本质上是对其值进行编码,更重要的是对其结构进行编码。可以遍历树来完成上述任务。
深度优先搜索可以从一个根开始,一直延伸到某个叶,然后回到根,到达另一个分支。根据根节点、左节点和右节点之间的相对顺序,可以进一步将深度优先搜索策略区分为:先序遍历、中序遍历、后序遍历
这里,我们选择先序遍历的编码方式做序列化,我们可以通过这样一个例子简单理解: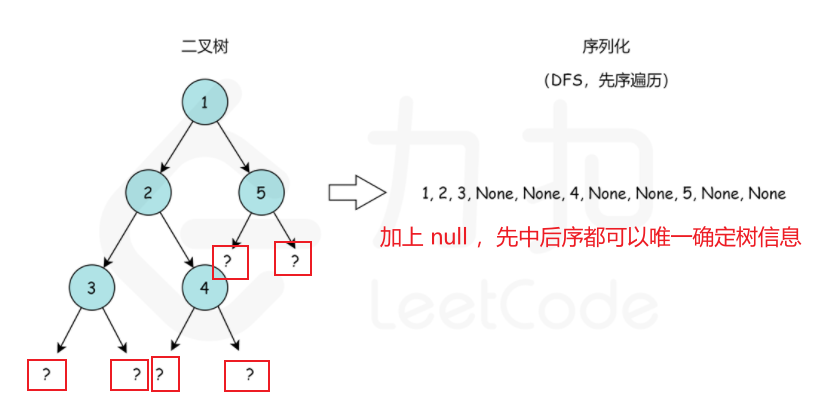
那么我们如何反序列化呢?
首先我们需要根据,把原先的序列分割开来得到先序遍历的元素列表,然后从左向右遍历这个序列:
- 如果当前的元素为 None,则当前为空树
- 否则先解析这棵树的左子树,再解析它的右子树
复杂度分析
时间复杂度:![[NC]123. 序列化二叉树 - 图8](/uploads/projects/mylearn@leetcode/664c75ec9a1a61834f2be04c99e92076.svg) ,其中
,其中 ![[NC]123. 序列化二叉树 - 图9](/uploads/projects/mylearn@leetcode/ec7a3f0915957018812ecefb5dd908aa.svg) 为二叉树结点个数。
为二叉树结点个数。
- 在序列化和反序列化函数中,我们只访问每个节点一次,因此时间复杂度为 
空间复杂度:![[NC]123. 序列化二叉树 - 图10](/uploads/projects/mylearn@leetcode/e3c0788acce40bd8ec132de8fc132c40.svg) ,其中
,其中 ![[NC]123. 序列化二叉树 - 图11](/uploads/projects/mylearn@leetcode/213b5ea569962a763b93533d67bf9107.svg) 为二叉树结点个数。
为二叉树结点个数。
- 在序列化和反序列化函数中,我们递归会使用栈空间,故渐进空间复杂度为 
官方代码
public class Codec {public String serialize(TreeNode root) {StringBuilder res = new StringBuilder("");return rserialize(root, res).toString();}public TreeNode deserialize(String data) {String[] dataArray = data.split(",");List<String> dataList = new LinkedList<String>(Arrays.asList(dataArray));return rdeserialize(dataList);}public StringBuilder rserialize(TreeNode root, StringBuilder str) {if (root == null) {str.append("None,");} else {str.append(root.val).append(",");str = rserialize(root.left, str);str = rserialize(root.right, str);}return str;}public TreeNode rdeserialize(List<String> dataList) {if (dataList.get(0).equals("None")) {dataList.remove(0);return null;}TreeNode root = new TreeNode(Integer.valueOf(dataList.get(0)));dataList.remove(0);root.left = rdeserialize(dataList);root.right = rdeserialize(dataList);return root;}}

若有收获,就点个赞吧
0 人点赞
