🚩传送门:牛客题目
题目
给定一个字符串数组,再给定整数 ![[NC]97. 字符串出现次数的 TopK 问题 - 图1](/uploads/projects/mylearn@leetcode/2b07b23c0010751ab40a1b92d4cc093f.svg) ,请返回出现次数前
,请返回出现次数前 ![[NC]97. 字符串出现次数的 TopK 问题 - 图2](/uploads/projects/mylearn@leetcode/f53198b6e8e9e44d05ab71274817e015.svg) 名的字符串和对应的次数。返回的答案应该按字符串出现频率由高到低排序。如果不同的字符串有相同出现频率,按字典序排序。对于两个字符串,大小关系取决于两个字符串从左到右第一个不同字符的 ASCII 值的大小关系。字符仅包含数字和字母 。
名的字符串和对应的次数。返回的答案应该按字符串出现频率由高到低排序。如果不同的字符串有相同出现频率,按字典序排序。对于两个字符串,大小关系取决于两个字符串从左到右第一个不同字符的 ASCII 值的大小关系。字符仅包含数字和字母 。
比如“ah1x”小于“ahb”,“231”<“32”
数据范围:字符串数满足 ![[NC]97. 字符串出现次数的 TopK 问题 - 图3](/uploads/projects/mylearn@leetcode/b7027ffa9ff9550061716eb9daf25577.svg) ,每个字符串长度
,每个字符串长度 ![[NC]97. 字符串出现次数的 TopK 问题 - 图4](/uploads/projects/mylearn@leetcode/80775fd9b1f1952556ec9fa20c431f0b.svg) ,
,![[NC]97. 字符串出现次数的 TopK 问题 - 图5](/uploads/projects/mylearn@leetcode/2cb32c8ce3d41d56f39407575ccc190b.svg)
要求:空间复杂度 ![[NC]97. 字符串出现次数的 TopK 问题 - 图6](/uploads/projects/mylearn@leetcode/66cdfc46f293831e7725d6ba65d9f53f.svg) ,时间复杂度
,时间复杂度 ![[NC]97. 字符串出现次数的 TopK 问题 - 图7](/uploads/projects/mylearn@leetcode/e86445e73dd734c45900d51ce6fa84fe.svg)
解题思路:哈希表+小根堆
题目要求找出出现次数前 k 的字符串,最为简单的就是直接遍历数组用 Map 统计每个字符串出现的次数,接着将 Map 放入 List 再降序排序输出前 k 的字符串。但是此方法的时间复杂度 ![[NC]97. 字符串出现次数的 TopK 问题 - 图8](/uploads/projects/mylearn@leetcode/4af9abb4ad28cc50800d24ed5b2e1820.svg) 不符合题目要求,因此将 List 修改为 小根堆 。
不符合题目要求,因此将 List 修改为 小根堆 。
算法过程:
- 使用哈希统计每个字符串出现的次数;
- 建立容量为 k 的小根堆,遍历 map,将统计后满足条件的字符放入最小堆中 。
条件:个数多的,个数相等放入字典排序靠前的
复杂度分析
时间复杂度: ![[NC]97. 字符串出现次数的 TopK 问题 - 图9](/uploads/projects/mylearn@leetcode/22efc4d8c932040f2b0f96e537d8d57e.svg) ,堆中 K 个元素的排序时间
,堆中 K 个元素的排序时间
空间复杂度:![[NC]97. 字符串出现次数的 TopK 问题 - 图10](/uploads/projects/mylearn@leetcode/12b0335b1ac5b3ec77bbff284145114d.svg) ,需要存储 n 个 Map.Entry
,需要存储 n 个 Map.Entry
对于 List 比较规则是:9X 、8Y 、7A 、7B
- 数值大的在前
- 数值相等,ASCII 字典排序小的在前
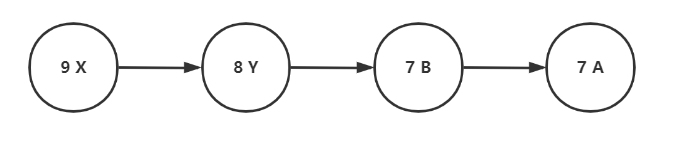
// 先是按出现次数降序比较,相同则再按照字符ASCII码升序比较Collections.sort(list,(o1, o2) ->(o1.getValue().compareTo(o2.getValue()) ==0 ? o1.getKey().compareTo(o2.getKey()) :o2.getValue().compareTo(o1.getValue())));
对于 Heap 比较规则是:7B 、7A 、8Y 、9X
- 数值小的在前(小根堆,堆顶值小)
- 数值相等,ASCII 字典排序大的在前
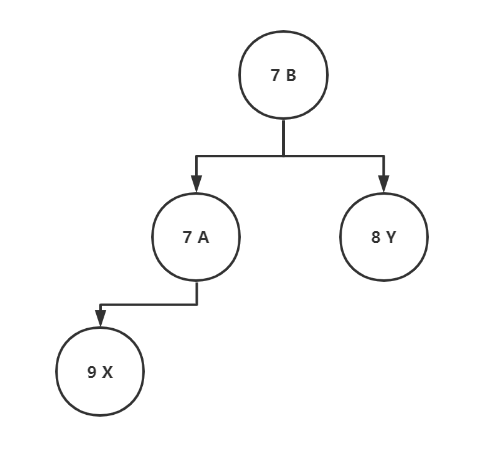
PriorityQueue<Map.Entry<String,Integer>> queue = new PriorityQueue<>(new Comparator<Map.Entry<String, Integer>>() {@Overridepublic int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {if (o1.getValue().equals(o2.getValue())){//字典序大的在前 所以 o2 比 o1return o2.getKey().compareTo(o1.getKey());}else {//数量小的在前所以 o1 - o2return o1.getValue() - o2.getValue();}}});
我的代码 [ 匿名内部类Comparator ]
public class Solution {public String[][] topKstrings (String[] strings, int k) {if (k == 0) return new String[][]{};String[][] res = new String[k][2];TreeMap<String,Integer> map = new TreeMap<>();// 统计各个字符串出现的次数for (int i=0;i<strings.length;++i){String s = strings[i];if (!map.containsKey(s)) {map.put(s, 1);} else {map.put(s, map.get(s) + 1);}}PriorityQueue<Map.Entry<String,Integer>> queue = new PriorityQueue<>(new Comparator<Map.Entry<String, Integer>>() {@Overridepublic int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {if (o1.getValue().equals(o2.getValue())){return o2.getKey().compareTo(o1.getKey());}else {return o1.getValue() - o2.getValue();}}});for(Map.Entry<String,Integer> entry:map.entrySet()){// 堆的元素个数小于k,则直接加入堆中if (queue.size() < k) {queue.offer(entry);} else{if(queue.peek().getValue()<entry.getValue()||(queue.peek().getValue()==entry.getValue()&&queue.peek().getKey().compareTo(entry.getKey())>0)){//如果堆顶元素 < 新数,则删除堆顶,加入新数入堆queue.poll();queue.offer(entry);}}}// 返回topKfor (int i = k-1; i >=0; --i) {Map.Entry<String,Integer> entry =(Map.Entry)queue.poll();res[i][0] = entry.getKey();res[i][1] = String.valueOf(entry.getValue());}return res;}}
我的代码[ 外部类Comparator ]
public class Solution {//自定义能够实现升序的比较器class DescComparator implements Comparator<Map.Entry<String,Integer>>{@Overridepublic int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {if (o1.getValue().equals(o2.getValue())){return o2.getKey().compareTo(o1.getKey());}else {return o1.getValue() - o2.getValue();}}}public String[][] topKstrings (String[] strings, int k) {if (k == 0) return new String[][]{};Comparator compa = new DescComparator();String[][] res = new String[k][2];TreeMap<String,Integer> map = new TreeMap<>();// 统计各个字符串出现的次数for (int i=0;i<strings.length;++i){String s = strings[i];if (!map.containsKey(s)) {map.put(s, 1);} else {map.put(s, map.get(s) + 1);}}PriorityQueue queue = new PriorityQueue(k,compa);for(Map.Entry<String,Integer> entry:map.entrySet()){// 堆的元素个数小于k,则直接加入堆中if (queue.size() < k) {queue.offer(entry);} else if (compa.compare(queue.peek(),entry) < 0) {//如果堆顶元素 < 新数,则删除堆顶,加入新数入堆queue.poll();queue.offer(entry);}}// 返回topKfor (int i = k-1; i >=0; --i) {Map.Entry<String,Integer> entry =(Map.Entry)queue.poll();res[i][0] = entry.getKey();res[i][1] = String.valueOf(entry.getValue());}return res;}}

若有收获,就点个赞吧
0 人点赞
