前言
总结:在用户研究中,被试间设计可以减少学习效应;被试内设计则需要更少的用户参与,且减少了随机变量的影响。
当你想在单个研究中对比若干个交互界面时,有两种分配用户进行测试的方式:
- 被试间设计(或组间设计):每种界面均用不同的用户进行测试,即每名用户只接触一种交互界面;
- 被试内设计(或组内设计、重复测量设计):每名用户都测试每一种交互界面。
(此处的「设计」指设计研究的设定,而非网页设计。)
例如,如果我们想要比较用户在两个租车网站A和B上如何完成租车,有两种方式可以设计研究,它们都是合理的:
- 被试间设计:每名用户仅测试一个网站(A或B),并只在该网站上完成租车。
- 被试内设计:每名用户测试两个网站(A和B),并在两个网站上都完成租车。
当研究需要测试不止一种界面时,我们都要决定是使用被试间设计还是被试内设计。然而,这种区分对于定量研究尤为重要。
一、定量研究的实验设计
和定性可用性测试不同,定量可用性测试旨在得出,在统计意义上能显著推广到整个用户群体的发现。这些研究数据的分析方法取决于其研究设计(即研究的实验设计)。
通常,定量可用性测试的首要目的就是比较——比较一个网站与其竞品,一种设计的两个迭代版本,或两种不同用户群体(如专家 vs. 新手)。与任何我们想要测定因果关系的科学实验一样,定量研究包含两种变量:
- 自变量,指研究者直接操控的变量
- 因变量,是研究者要测定的变量(且被认为在不同自变量操控条件下,会产生不同结果)
(如果研究产生了统计显著的差异,我们可以声称自变量的变化造成了因变量的变化。)
让我们回到之前的租车例子。如果我们想要确定A网站还是B网站能帮助用户更好地完成租车的任务,我们可以将网站(有两个可能的值——A和B)作为自变量,而用户完成租车任务时间和准确率作为因变量。而研究目的即是因变量(任务完成时长和准确率)是否在两个网站上有所区别,或保持一致(如果一致,则说明没有哪个网站比另一个好)。
那么,接下来我们要回答的问题就是:是进行被试间设计还是被试内设计呢?即,研究中的每名用户需要测试自变量中包含的所有情况(被试内),还是仅仅测试一种情况(被试间)?实验设计的选择会影响我们分析结果的统计方法类型。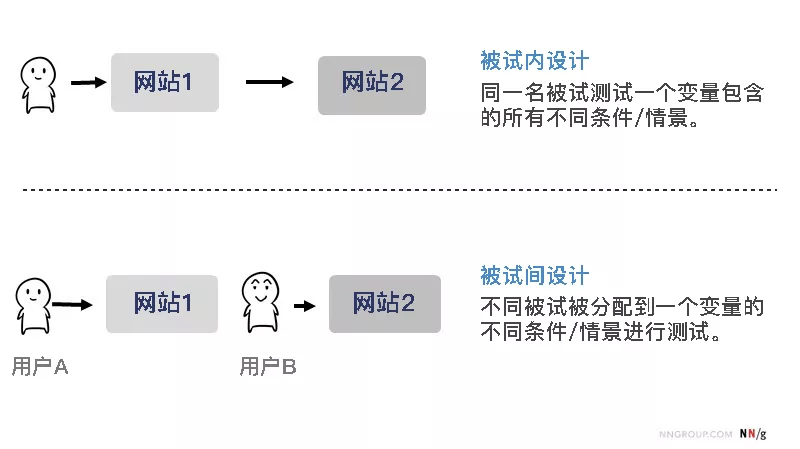
也存在研究设计同时包含被试间和被试内设计的情况。例如,假定在我们的租车网站研究中,我们想要了解30岁以下的用户和30岁以上的用户在任务完成上有无差异。在这种情况下,我们就有了两个自变量:
- 年龄,分为两种水平:30岁以下,30岁以上
- 网站,包含两个可能:A和B
研究中,每个年龄组我们都会招募同等数量的用户。我们假定,让30岁以下的用户在A网站和B网站均进行租车任务。在这种情况下,网站变量即为被试内设计(因为每名用户都访问了A和B网站)。然而,年龄变量上,我们则进行了被试间设计:一名用户只可能会在单个年龄组中(30岁以上或30岁以下,而不可能都是)。(理论上,你确实可以选一组30岁以下的用户并在他们满30岁之后再次测试该网站,但现实生活中这种研究设计是不可行的。)
某些自变量可能会限制研究设计的选择。正文提到的年龄即是其中之一。其他常见的相似变量包括熟练度(如果我们想要比较专家和新手用户),用户类型(如果我们想要对比不同用户群体或用户画像——例如,商务旅行者和休闲旅行者),或性别(假定一个人不可能同时属于多个性别)。在可用性以外的领域,药物试用是最常见的使用被试间设计的情况,研究参与者只会服用一种药物:被测药物,或安慰剂。有时,操控自变量本身就会影响参与者的状态:例如,如果想要比较两种教学方式哪种能更高效地进行阅读理解的教学,我们不能够让同一名学生同时接受两种方式的教育,因为他一旦学会了怎么进行阅读,他就不能够忘记已学会的东西,以不会的状态再学一遍。
二、哪种更好:被试间设计还是被试内设计?
不幸的是,这个问题并没有一个简单的答案。正如上文讨论的那样,有时自变量的类型会决定研究设计。但在许多情况下,两种设计都是可行的。
- 被试间设计最小化了学习效应和不同场景间的迁移。当用户在一个租车网站上完成一系列任务后,他对于租车这个领域就有了比之前更多的知识和了解。例如,他可能会知道了租车网站会对21岁以下的司机征收额外费用,或者什么是车辆碰损险。这种知识可能会帮助他更高效地完成第二个租车网站上的任务,即使第二个网站可能和第一个网站很不一样。对于被试间设计,这种知识的迁移并不是问题——用户并不会测试同一自变量的不同条件。
- 被试间设计相比被试内设计,每个测试试次时长更短。只在单个租车网站上完成任务的用户会比在两个租车网站上都测试的用户更快地完成一场测试。更短的试次对于用户而言没有那么辛苦,并且更适用于远程无主持可用性测试。
- 被试间设计在流程上更简单,尤其是在有多个自变量的情况下。当研究是被试内设计时,在呈现测试界面的顺序上需要进行随机化,防止顺序效应。例如,在租车网站研究中,我们需要确保不是每个用户都先在A网站租车,再在B网站租车。访问租车网站的顺序对于每个被试应该是随机的。在只测试两个网站时,这比较简单:随机分配50%的用户先访问A网站,另50%用户先访问B网站即可。然而,如果你的研究有更多的自变量,或每个自变量有更多的可能性时,随机化测试在设定上就会更难。
- 被试内设计需要更少的用户参与研究,也更便宜。为了检测两种条件下的统计显著的差异,我们通常需要在每种条件下收集到一定数量的数据点(通常是30个以上)。如果研究采用被试内设计,每名用户都会为自变量的每个条件提供数据点。在租车研究中,30名用户可以为两个网站都提供数据。但如果采用被试间设计,我们则需要两倍的用户参与来获得同样多的数据点。这意味着两倍的投入。
- 被试内设计减少了随机变量的影响。被试内设计的最大优点之一,就是它能更好地排除可能干扰、甚至掩盖组间差异的随机噪音。参与研究的每名用户都有各自的个人成长史、背景知识,甚至情境影响。有的用户可能刚参加完一个通宵派对,有的可能处于疲惫状态,也有的可能在参与研究前刚刚获知了一个好消息因而非常高兴。如果同一名用户参与测试了自变量的每个情景,他会以同样的方式影响这些数据。开心的用户在两个网站上测试时都会很开心,疲惫的用户则都会疲惫。但如果研究是被试间设计,开心的用户可能只会测试一个网站,从而影响最终结果。我们应确保在测试另一个网站时,也有一个相似的开心的用户,来抵消之前用户的影响。在实际操作中,研究者不太可能感知到被试间的这些差异——尽管不同组用户的性别、经验水平和年龄可能都匹配上了,我们也很难检测及预测其他的、每名用户特有的、可能影响研究结果的因素。
三、随机化:对两种设计同等重要
无论你的研究是被试内还是被试间设计,随机化都是我们需要考虑的。尽管对于这两种情况,进行随机化的考虑会有些许的不同。
上文中我们讨论了被试内设计需要随机化的原因:它可以抵消可能的顺序效应,最小化不同条件下的迁移和学习效应。
对于被试间设计,则需要确保被试被随机地分配到不同条件下,因为我们要确保被试分配不会影响试验结果。因此,如果一名研究员决定让所有他喜欢的用户测试A网站,并最终发现用户在A网站上表现比B网站要好,他就不能断定到底是这两个网站确实有区别,还是这仅仅是他分配用户的偏好造成的结果(例如,因为测试A网站的用户能感受到研究员对他们的喜欢并有所回报,会在完成任务时更加耐心,或有着更积极的心态)。
即使没有个人偏好这种很明显的偏见影响被试分配,随机化也是很容易出错的。假设你要进行一个4天的研究,从周六到周二。你可能决定要让前一半参与的用户从A网站开始,而后一半参与的用户从B网站开始。然而,这并不是真正的随机化,因为很有可能特定类型用户更愿意周末参与研究,而别的类型用户则更倾向于周中参与研究。
结论
用户研究可以是被试间设计或被试内设计(或都是),取决于每个用户只测试一种条件,或测试研究中所有不同的条件。每种实验设计都有其优劣:被试内设计只需更少的用户,并增加了发现不同条件下差异的可能性;被试间设计减少了学习效应,缩短了每个试次时长,且在研究流程和数据分析上可能更简单。
附录
原文地址:https://www.nngroup.com/articles/between-within-subjects/
版权声明
本文版权属尼尔森诺曼集团(Nielsen Norman Group)所有。欢迎转发至朋友圈,如需转载,请邮件Support@nngroup.com。未经授权的转载、翻译是侵权行为,版权方将保留追究法律责任的权利。

若有收获,就点个赞吧
0 人点赞
