读取数据
1、Scanner input = new Scanner(System.in);// 过 Scanner 类的 next() 与 nextLine() 方法获取输入的字符串,// 在读取前我们一般需要使用 hasNext 与 hasNextLine 判断是否还有输入的数据String s = input.nextLine();System.out.println("next方式接收:");if(scan.hasNext()){String str1 = scan.next();System.out.println("输入的数据为:"+str1);}input.close();2、BufferedBeader input = new BufferedBeader(new InputStreamReader(System.in));String s = input.readLine();
next()与nextLine()区别
next():
1、一定要读取到有效字符后才可以结束输入。
2、对输入有效字符之前遇到的空白,next()方法会自动将其去掉。
3、只有输入有效字符后才将其后面输入的空白作为分隔符或者结束符。
4、next()不能得到带有空格的字符串。
nextLine():
1、以Enter为结束符,也就是说nextLine()方法返回的是输入回车之前的所有字符。
2、可以获得空白。
获取其他基本数据类型
如果要输入int或float类型的数据,在Scanner类中也有支持,但是在输入之前最好先使用 hasNextXxx() 方法进行验证,再使用 nextXxx() 来读取:
import java.util.Scanner;
class ScannerDemo{
public static void main(String[] args){
Scanner scan = new Scanner(System.in);
double sum = 0;
int m = 0;
while(scan.hasNextDouble()){
double x = scan.nextDouble();
m = m + 1;
sum = sum + x;
}
System.out.println(m+"个数的和为"+sum);
System.out.println(m+"个数的平均值是"+(sum/m));
}
}
Lambda表达式
lambda 表达式的主要形式有三种:
( params ) -> expression;
( params ) -> statement;
( params ) -> { statements };
// 有花括号就需要 return 并且最后加分号
(int e) -> e*e // 对应第一种格式,返回 e*e 的值
(int e) -> e = 2*2 // 对应第二种格式,返回 void
(int e) -> return e*e //这种是错误的,我不太明白,为什么不能算是 statement,欢迎直接
(int e) -> { return e*e; } // 返回 e*e
(int e) -> { e*e; } // 这句话是错的,因为 e*e 不是 statement, 而是 expression
// 下面是多表达式的情况,返回的值是显示指明 return 的地方
(int e) -> {
e = 1*1;
return e*3;
}
Java math and string
最大值最小值
//Float Double Byte Character Short Integer Long
Imax = Integer.MAX_VALUE;
Imin = Integer.MIN_VALUE;
Lmax = Long.MAX_VALUE;
Lmin = Long.MIN_VALUE;
Dmax = Double.MAX_VALUE;
Dmin = Double.MIN_VALUE;
Long to int
// 因为Long是对象,而int、long是基础数据类型
Long l = new Long();
int a = l.intValue();
long b = l.longValue();
Long l = new Long((long)3);
数组
int[] arr = new int[]{1,2,3,4,5}; //初始化
int a[] = {5,4,3,2,1}; //初始化
int len = arr.length; // 获取数组的长度
Arrays.fill(arr, MAX); // 数组填充
Arrays.sort(arr); //升序
Array.sort(int[] a , int fromIndex, int toIndex); // [fromIndex, toIndex - 1]
Arrays.sort(a, Collections.reverseOrder()); // 降序
int newArr = oldArr.clone() // 数组赋值
Collections.reverse(mylist);
数组复制
System.arraycopy()方法实现复制
1、System中提供了一个native静态方法arraycopy(),可以使用这个方法来实现数组之间的复制。对于一维数组来说,这种复制属性值传递,修改副本不会影响原来的值。对于二维或者一维数组中存放的是对象时,复制结果是一维的引用变量传递给副本的一维数组,修改副本时,会影响原来的数组。
2、System.arraycopy的函数原型是:
public static void arraycopy(Object src,
int srcPos,
Object dest,
int destPos,
int length)
Array to List
String[] array = {"java", "c"};
List<String> list = Arrays.asList(array);
//但该方法存在一定的弊端,返回的list是Arrays里面的一个静态内部类,该类并未实现add,remove方法,因此在使用时存在局限性
// 运用ArrayList的构造方法是目前来说最完美的作法,代码简洁,效率高
List<String> list = new ArrayList<String>(Arrays.asList(array));
List to Array
List<String> list = new ArrayList<String>();
Object[] array=list.toArray();
// 推荐 设置好大小
String[] array=list.toArray(new String[list.size()]);
Math
Math.max((int)a,(int)b);
Math.min((int)a,(int)b);
Math.abs();
Math.ceil();
Math.floor();
Math.round();// 返回四舍五入的值
Math.exp();// 返回自然数底数 e 的参数次方
Math.pow(x,y);
Math.log();
Math.log10();
Math.random();//返回0-1之间的随机数
长度
- Java中的length属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了length这个属性.
- java中的length()方法是针对字符串String说的,如果想看这个字符串的长度则用到length()这个方法
字符串
String to int/long/char array
int a = Integer.parseInt(string);
long la = Long.parseLong(string);
char[] arr = String.toCharArray();
char c = s1.charAt(index);
char to String
1、String s = String.valueOf('c');//效率最高的方法 因为常量池 返回一个对象
2、String s = String.valueOf(new char[]{'c'}); //将一个char数组喊高转换成String
3、String s = Character.toString('c');// Character.toString(char)方法喊渗好实际上直接返回String.valueOf(char)
4、String s = new Character('c').toString();
5、String s = "" + 'c';// 虽然郑铅这个方法很简单,但这是效率最低的方法;
6. String s = new String(new char[]{'c'});
String method

String s = "asdefgasdefg";
for(int i = 0; i < s.length(); i++>){
char c = s.charAt(i);
}
s.indexOf('s') //retrun 1
s.indexof('s',2) //return 7
s.lastIndexOf('s') //return 7
s.lastIndexOf('s',6)//return 1
string[] ss = s.split("regex"); // 如果用“.”作为分隔的话,必须是如下写法:String.split("\\."),这样才能正确的分隔开,不能用String.split(".");
String s = s.substring((int)start,(int)end)//[start,end)
char[] cs = s.toCharArray();
String s = s.trim();
String s = String.valueOf(object);
String s = "a".repeat(3); // 字符串重复 结果为“aaa”
字符串比较
- equals() 方法
equals() 方法将逐个地比较两个字符串的每个字符是否相同。
str1.equals(str2);
"Hello".equals(greeting)
- equalsIgnoreCase() 方法
equalsIgnoreCase() 方法的作用和语法与 equals() 方法完全相同,唯一不同的是 equalsIgnoreCase() 比较时不区分大小写。
- equals()与==的比较
理解 equals() 方法和==运算符执行的是两个不同的操作是重要的。如同刚才解释的那样,equals() 方法比较字符串对象中的字符。而==运算符比较两个对象引用看它们是否引用相同的实例。
StringBuilder & StringBuffer
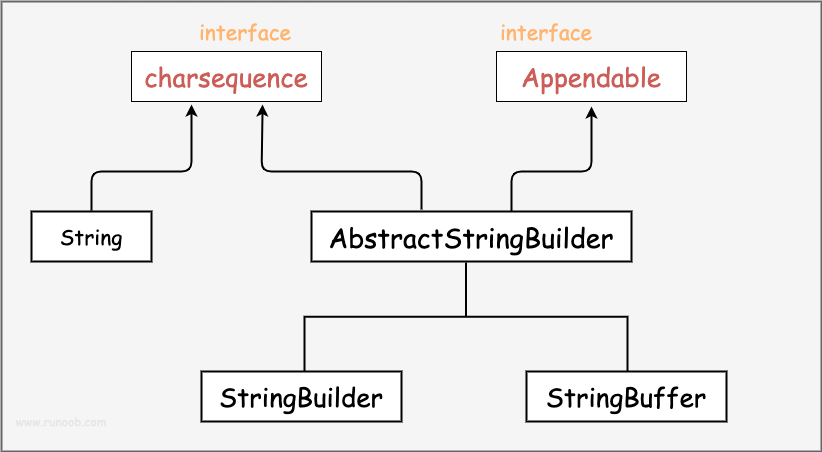
- StringBuilder 处理速度快但不是线程安全的
- StringBuffer 处理速度比 SrtringBuilder 慢但是线程安全
- String 是字符串常量,因此处理速度最慢
StringBuilder sb = new StringBuilder(); // 对象名.length() 序列长度 System.out.println(sb.length()); // 0 // 对象名.append() 追加到序列 sb.append("hello"); System.out.println(sb); // hello // 97代表的是是'a' sb.appendCodePoint(97); System.out.println(sb); // helloa // 链式编程 sb.append(1).append("world").append(2); System.out.println(sb); // helloa1world2 // 索引是5的位置替换成空格 sb.setCharAt(5, ' '); System.out.println(sb); // hello 1world2 // 指定位置0前插入0 sb.insert(0, 0); System.out.println(sb); // 0hello 1world2 // 删除索引6(包含)至索引14(不包含)的字符串 sb.delete(6, 14); // 删除索引6的字符串 sb.deleteCharAt(6); System.out.println(sb); // 0hello // StringBuilder类型转换成String类型 String s = sb.toString(); System.out.println(s); // 0hello // 以及还有截取、反转、替换等方法StringBuilder sb = new StringBuilder("String"); sb.append(""); sb.reverse(); sb.delete((int)start,(int)end); //[start,end) 删除 sb.deleteCharAt(int index); // 删除索引处 sb.insert((int)offset,"String"); sb.toString(); sb.setCharAt((int)index,(char)c);// string转换成StringBuilder String str = "hello"; StringBuilder sb = new StringBuilder(str); System.out.println(sb); // hello // StringBuilder转换成String String s = sb.toString(); System.out.println(s); // hello字符串数组
String[] a = new String[100]; // 排序 // 注意,要想改变默认的排列顺序,不能使用基本类型(int,double,char) // 而要使用它们对应的类 Arrays.sort(a); //与list转换 List<Integer> 和 int[] 因类型不同不可直接转换 List<String> list = Arrays.asList(a); //a需要包装类 List<String> lst = new ArrayList<>(Arrays.asList(nums[i], nums[left], nums[right]))); String[] b = (String[])list.toArray(new String[size]); //复制 String[] c = Arrays.copyOfRange(String[] original,(int)start,(int)to)//[start,to) //填充 Arrays.fill(a,"fill");Utils
随机数
1、java.lang.Math.Random;
调用这个Math.Random()函数能够返回带正号的double值,该值大于等于0.0且小于1.0,即取值范围是[0.0,1.0)的左闭右开区间,返回值是一个伪随机选择的数,在该范围内(近似)均匀分布。例子如下: ```java package IO; import java.util.Random;
public class TestRandom {
public static void main(String[] args) {
// 案例1
System.out.println("Math.random()=" + Math.random());// 结果是个double类型的值,区间为[0.0,1.0)
int num = (int) (Math.random() * 3); // 注意不要写成(int)Math.random()*3,这个结果为0,因为先执行了强制转换
System.out.println("num=" + num);
/**
* 输出结果为:
*
* Math.random()=0.02909671613289655
* num=0
*
*/ }}
<a name="qdmno"></a>
### 2、java.util.Random
下面Random()的两种构造方法:<br />Random():创建一个新的随机数生成器(默认当前系统时间的毫秒数)。<br />Random(long seed):使用单个 long **种子(只是种子)**创建一个新的随机数生成器。
```java
protected int next(int bits):生成下一个伪随机数。
boolean nextBoolean():返回下一个伪随机数,它是取自此随机数生成器序列的均匀分布的boolean值。
void nextBytes(byte[] bytes):生成随机字节并将其置于用户提供的 byte 数组中。
double nextDouble():返回下一个伪随机数,它是取自此随机数生成器序列的、在0.0和1.0之间均匀分布的 double值。
float nextFloat():返回下一个伪随机数,它是取自此随机数生成器序列的、在0.0和1.0之间均匀分布float值。
double nextGaussian():返回下一个伪随机数,它是取自此随机数生成器序列的、呈高斯(“正态”)分布的double值,其平均值是0.0标准差是1.0。
int nextInt():返回下一个伪随机数,它是此随机数生成器的序列中均匀分布的 int 值。
int nextInt(int n):返回一个伪随机数,它是取自此随机数生成器序列的、在(包括和指定值(不包括)之间均匀分布的int值。
long nextLong():返回下一个伪随机数,它是取自此随机数生成器序列的均匀分布的 long 值。
void setSeed(long seed):使用单个 long 种子设置此随机数生成器的种子。
集合框架
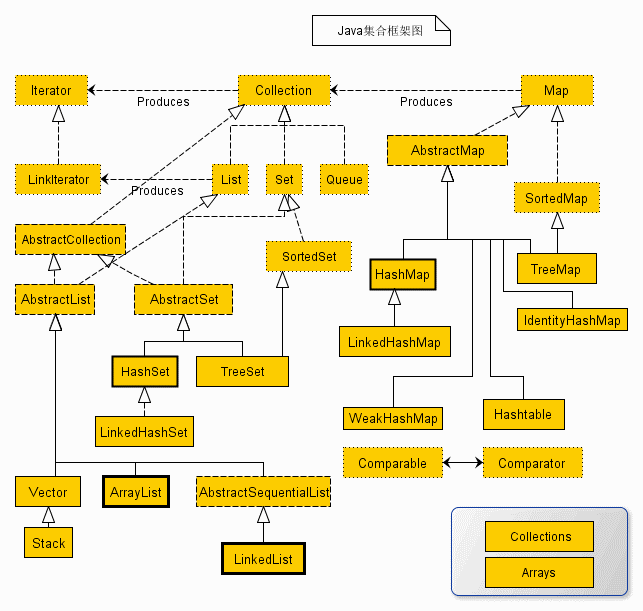
接口描述
1、Collection 接口
Collection 是最基本的集合接口,一个 Collection 代表一组 Object,即 Collection 的元素, Java不提供直接继承自Collection的类,只提供继承于的子接口(如List和set)。
Collection 接口存储一组不唯一,无序的对象。
2、List 接口
List接口是一个有序的 Collection,使用此接口能够精确的控制每个元素插入的位置,能够通过索引(元素在List中位置,类似于数组的下标)来访问List中的元素,第一个元素的索引为 0,而且允许有相同的元素。
List 接口存储一组不唯一,有序(插入顺序)的对象。
3、Set
Set 具有与 Collection 完全一样的接口,只是行为上不同,Set 不保存重复的元素。
Set 接口存储一组唯一,无序的对象。
4、SortedSet
继承于Set保存有序的集合。
5、Map
Map 接口存储一组键值对象,提供key(键)到value(值)的映射。
6、Map.Entry
描述在一个Map中的一个元素(键/值对)。是一个 Map 的内部接口。
7、SortedMap
继承于 Map,使 Key 保持在升序排列。
8、Enumeration
这是一个传统的接口和定义的方法,通过它可以枚举(一次获得一个)对象集合中的元素。这个传统接口已被迭代器取代。
Collection 接口
Collection 接口是 Set,List,Queue 接口的父接口
methods
| Modifier and Type | Method and Description |
|---|---|
| boolean | add(E e) Ensures that this collection contains the specified element (optional operation). |
| boolean | addAll(Collection<? extends E> c) Adds all of the elements in the specified collection to this collection (optional operation). |
| void | clear() Removes all of the elements from this collection (optional operation). |
| boolean | contains(Object o) Returns true if this collection contains the specified element. |
| boolean | containsAll(Collection<?> c) Returns true if this collection contains all of the elements in the specified collection. |
| boolean | equals(Object o) Compares the specified object with this collection for equality. |
| int | hashCode() Returns the hash code value for this collection. |
| boolean | isEmpty() Returns true if this collection contains no elements. |
| Iterator[E](https://docs.oracle.com/javase/8/docs/api/java/util/Collection.html) | iterator() Returns an iterator over the elements in this collection. |
| default Stream[E](https://docs.oracle.com/javase/8/docs/api/java/util/Collection.html) | parallelStream() Returns a possibly parallel Stream with this collection as its source. |
| boolean | remove(Object o) Removes a single instance of the specified element from this collection, if it is present (optional operation). |
| boolean | removeAll(Collection<?> c) Removes all of this collection’s elements that are also contained in the specified collection (optional operation). |
| default boolean | removeIf(Predicate<? super E> filter) Removes all of the elements of this collection that satisfy the given predicate. |
| boolean | retainAll(Collection<?> c) Retains only the elements in this collection that are contained in the specified collection (optional operation). 仅保留此集合中包含在指定集合中的元素 |
| int | size() Returns the number of elements in this collection. |
| default Spliterator[E](https://docs.oracle.com/javase/8/docs/api/java/util/Collection.html) | spliterator() Creates a Spliterator over the elements in this collection. |
| default Stream[E](https://docs.oracle.com/javase/8/docs/api/java/util/Collection.html) | stream() Returns a sequential Stream with this collection as its source. |
| Object[] | toArray() Returns an array containing all of the elements in this collection. |
| toArray(T[] a) Returns an array containing all of the elements in this collection; the runtime type of the returned array is that of the specified array. |
| static |
replaceAll(List Replaces all occurrences of one specified value in a list with another. |
|---|---|
| static void | reverse(List<?> list) Reverses the order of the elements in the specified list. |
| static |
reverseOrder() Returns a comparator that imposes the reverse of the natural ordering on a collection of objects that implement the Comparable interface. |
| static |
reverseOrder(Comparator Returns a comparator that imposes the reverse ordering of the specified comparator. |
| static void | rotate(List<?> list, int distance) Rotates the elements in the specified list by the specified distance. |
| static void | shuffle(List<?> list) Randomly permutes the specified list using a default source of randomness. |
| static void | shuffle(List<?> list, Random rnd) Randomly permute the specified list using the specified source of randomness. |
| static |
singleton(T o) Returns an immutable set containing only the specified object. |
| static |
singletonList(T o) Returns an immutable list containing only the specified object. |
| static |
singletonMap (K key, V value) Returns an immutable map, mapping only the specified key to the specified value. |
| static void |
sort(List Sorts the specified list into ascending order, according to the natural ordering of its elements. |
| static |
sort(List Sorts the specified list according to the order induced by the specified comparator. |
| static void | swap(List<?> list, int i, int j) Swaps the elements at the specified positions in the specified list. |
//Collection
Collections.sort(Collection c);
Collections.reverse(Collection c);
//List 有序集合,具有和索引有关的操作
List<Object> list = new ArrayList<>();
list.add((int)index,Object o);
list.get((int)index);
list.remove((int)index);
list.indexOf(Object o);
list.subList(int start,int end); [start,end);
//Stack(LIFO)
Stack<Object> s = new Stack<>();
s.pop();
s.peek();
s.push(Object o);
//Queue(FIFO)
Queue<Object> q = new LinkedList<>();
q.offer(Object o);
q.peek();
q.poll();
//Set 不允许重复
HashSet<Object> set = new HashSet<>();
set.add(Object o);
set.contains(Object o);
set.remove(Object o);
Java Map
常用类型
| 类型 | 特征 | ||
|---|---|---|---|
| HashMap | 根据 HashCode 存储数据,访问速度快。至多允许一条记录键为 null; 允许多条记录的值为 null;线程非同步 | ||
| TreeMap | 保存的记录按照键 (key) 排序,也可自定义排序规则。用生成的 Iterator 遍历 TreeMap 得到记录是排序后的。不允许记录的键为 null;线程非同步 | ||
| Hashtable | 用 HashMap 类似,不同的是键值都不允许为 null。 支持线程同步,但写入较慢 | ||
| LinkedHashMap | 保留记录的插入顺序,生成 Iterator 遍历顺序与插入顺序一致。遍历比 HashMap 慢,键值都允许为 null;线程非同步 |
—> HashMap 剖析
常用 API
| 方法 | 描述 |
|---|---|
| Object put(Object k, Object v) | 存入键值对 |
| Object get(Object k) | 返回键所映射的值;如果不存在该映射则返回 null |
| getOrDefault(Object key, V defaultValue) | 返回指定键映射到的值,如果该映射不包含键的映射,则返回defaultValue |
| boolean containsKey(Object k) | 是否包含键 k |
| boolean containsValue(Object v) | 是否包含值 v |
| boolean isEmpty() | Map 是否为空 |
| int size() | 返回 Map 的键值对数 |
| boolean remove(Object k) | 如果存在一个键映射关系,则删除此关系 (映射关系不存在不会报错) |
| boolean remove(Object k, V Value) | 仅在当前映射到指定值时,才移除指定键的条目 |
| replace(K key, V value) | 如果指定了 key 和 value,删除成功返回 true,否则返回 false。 |
| replace(K key, V oldValue, V newValue) | 如果 oldValue 不存,对 key 对应对 value 执行替换,返回 key 对应的旧值,如果存在则替换成功返回 true。 |
| void clear() | 移除 Map 中所有映射关系 |
| boolean equals(Object obj) | 比较指定对象于此 Map 是否相等 |
| void putAll(Map m) | 将指定 Map 的映射关系复制到此 Map 中 |
| Collection values() | 以 Collection 形式返回 Map 包含的值 |
| Set keySet() | 以 Set 形式返回 Map 包含的键 |
| Set entrySet() | 以 Set 形式返回 Map 的映射关系 |
Map 应用示例
Map<Integer, Character> map = new HashMap<>();
map.put(1, 'c');
map.get(1);
for(int i: map.keySet()){
System.out.println(map.get(i));
}
if(map.containsKey(1)){
map.remove(1);
}
常用遍历方法
1. 只获取键或值
// 获取键
for(Integer key: map.keyset()){
System.out.println(key);
}
// 获取值
for(Integer value: map.value()){
System.out.println(value);
}
2. 同时获取键和值
// 2.1 先取key再取value。不推荐
for(Integer key:map.keySet()){
System.out.println(map.get(key));
}
// 2.2 通过map entrySet遍历。性能优于上一种。
for(Map.Entry<Integer, Integer> entry: map.entrySet()){
System.out.println(entry.getKey() + ":" + entry.getValue());
}
3. Iterator
上面的 foreach 都可以用 Interator 代替。
foreach 是对 Set 遍历,大小不能改变。如果改变 map 的大小,会报错。如果想要删除元素,还是要用 Interator 的方式删除。
Interator<Map.Entry<Integer, Integer>> it = map.enteySet().iterator();
while(it.hasNext()){
Map.Entry<Integer, Integer> entry = it.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
// it.remove() 删除元素
}
- 注:Map.entrySet() 这个方法返回的是一个Set
4. Lambda
代码简洁,但是性能低于 entrySet。
map.forEach((key, value)->{
System.out.println(key + ":" + value);
})
5. 性能测试
用 10 万条数据,做了一个简单性能测试,数据类型为 Integer,map 实现选取 HashMap
static{
for (int i = 0; i < 100000; i++) {
map.put(i, 1);
}
}
测试结果如下:
KeySet: 392
Values: 320
keySet get(key): 552
entrySet: 465
entrySet Iterator:508
Lambda: 536
总结
- 如果只是获取key,或者value,推荐使用keySet或者values方式
- 如果同时需要key和value推荐使用entrySet
- 如果需要在遍历过程中删除元素推荐使用Iterator
- 如果需要在遍历过程中增加元素,可以新建一个临时map存放新增的元素,等遍历完毕,再把临时map放到原来的map中
Map 的遍历方法参考 (侵删)
Java for循环
Java for 循环里面的 i++ 与 ++i
在 for 循环里两者的作用是一样的
i++
for(int i=0; i<5; i++){
System.out.print(i + ",");
}
>> 0, 1, 2, 3, 4
++i
for(int i=0; i<5; ++i){
System.out.print(i + ",");
}
>> 0, 1, 2, 3, 4
工作原理
i++
{
System.out.print(i + ",");
i++;
}
++i
{
System.out.print(i + ",");
++i;
}
区别
在 Java 里面,i++ 需要开辟新的存储空间用于存储结果,++i 直接在原存储空间中存储结果。故 ++i 在 for 循环里面执行效率要高。 可以作为代码优化的一部分。
foreach 与 for 循环的效率
- 首先测试数组
结果
可见对于大数组采用 for 循环效率更高 ```java // 测试for循环 int[] A = new int[100000000]; long startTime = System.nanoTime(); int len = A.length; int res = 0; for(int i=0; i<len; i++){ res += A[i]; } long endTime = System.nanoTime(); System.out.println(“for循环: “+(endTime- startTime));
// 测试foreach int[] A = new int[100000000]; long startTime = System.nanoTime(); int len = A.length; int res = 0; for(Integer i: A){ res += i; } long endTime = System.nanoTime(); System.out.println(“foreach循环: “+(endTime- startTime));
```java
for循环: 37143324
forecah循环: 75450311
- 再测试 ArrayList
结果
可见对于 ArrayList 仍然是采用 for 循环效率更高! ```java ArrayListlist = new ArrayList<>(30000000); for(int i=0; i<30000000; i++){
} // 测试for循环 long startTime = System.nanoTime(); int size = list.size(); int res = 0; for(int i=0; i<size; i++){ res += list.get(i); } long endTime = System.nanoTime(); System.out.println(“for循环: “+(endTime- startTime));list.add(i);
// 测试foreach long startTime = System.nanoTime(); int res = 0; for(Integer i: list){ res += i; } long endTime = System.nanoTime(); System.out.println(“foreach循环: “+(endTime- startTime));
```java
for循环: 39368248
forecah循环: 42177137
for 循环小技巧
关于数组
1. 循环嵌套采用小套大。原理跟复制几个大文件跟复制一堆小文件耗时一样。
测试
long startTime = System.nanoTime();
int res = 0;
// 大套小
for(int i=0; i<10000000; i++){
for(int j=0; j<100; j++){
res += i;
}
}
long endTime = System.nanoTime();
System.out.println("大套小: "+(endTime- startTime));
// 小套大
for(int i=0; i<100; i++){
for(int j=0; j<10000000; j++){
res += i;
}
}
long endTime = System.nanoTime();
System.out.println("小套大: "+(endTime- startTime));
大套小: 57934223
小套大: 4918044
2. 数组复制时采用 System.arraycopy() 方法比 for 循环复制效率高。
System.arraycopy()
public static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length)
代码解释:
Object src : 原数组
int srcPos : 从元数据的起始位置开始
Object dest : 目标数组
int destPos : 目标数组的开始起始位置
int length : 要copy的数组的长度
关于 ArrayList
1. 在循环时,首先把 ArrayList 长度 size 记录下来。
测试
ArrayList<Integer> list = new ArrayList<>(30000000);
for(int i=0; i<30000000; i++){
list.add(i);
}
long startTime = System.nanoTime();
//先把长度保存下来
int len = list.size();
int res = 0;
for(int i=0; i<len; i++){
res += list.get(i);
}
long endTime = System.nanoTime();
System.out.println("保存size(): "+(endTime- startTime));
//没有保存size()
for(int i=0; i<list.size(); i++){
res += list.get(i);
}
long endTime = System.nanoTime();
System.out.println("没有保存size(): "+(endTime- startTime));
结果
保存size(): 38973440
没有保存size(): 39486862
Java List
常用类型
| 类型 | 特征 | |
|---|---|---|
| ArrayList | 随机访问元素快;中间插入与删除元素较慢;操作不是线程安全的 | |
| LinkedList | 中间插入与删除操作代价较低,提供优化的顺序访问;随机访问元素慢 |
ArrayList
ArrayList 的 UML 类图如下所示:
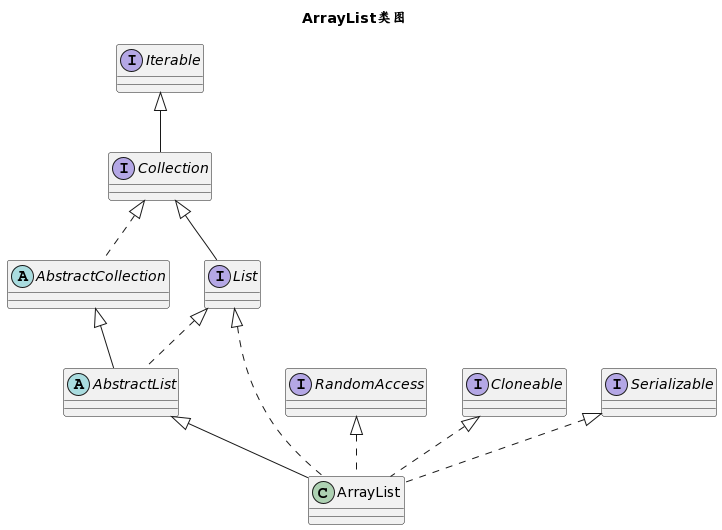
ArrayList 继承了 AbstractList, 直接实现了 Cloneable, Serializable,RandomAccess 类型标志接口。
- AbstractList 作为列表的抽象实现,将元素的增删改查都交给了具体的子类去实现,在元素的迭代遍历的操作上提供了默认实现。
- RandomAccess 接口实现,表示 ArrayList 里的元素可以被高效效率的随机访问,以下标数字的方式获取元素。实现 RandomAccess 接口的列表上在遍历时可直接使用普通的 for 循环方式,并且执行效率上给迭代器方式更高。
- Cloneable 接口的实现,表示了 ArrayList 支持调用 Object 的 clone 方法,实现 ArrayList 的拷贝。
- Serializable 接口实现,说明了 ArrayList 还支持序列化和反序列操作,具有固定的 serialVersionUID 属性值。
ArrayList 常用 API
| 方法 | 描述 |
|---|---|
| boolean add(E object) | 再 ArrayList 尾存入对象 |
| void add(int location, E object) | 在 location 添加对象 |
| boolean addAll(Collection<? extends E> collection) | 将一个 Collection 对象中存储全部的对象复制并存入 |
| boolean addAll(int location, Collection<? extends E> collection) | 将一个 Collection 对象中存储全部的对象复制并存入 location |
| boolean contains(Object object) | 是否包对象 object |
| boolean containsAll(Collection<?> collection) | 是否包含一个 Collection 对象 |
| boolean isEmpty() | ArrayList 是否为空 |
| E get(int location) | 获取 location 的对象 |
| E set(int location, E object) | 将某个位置的元素替换成 object |
| int indexOf(Object object) | 获取某个对象的位置(顺序遍历第一个) |
| int lastIndexOf(Object object) | 获取某个对象的位置(逆序遍历第一个) |
| int size() | 返回 ArrayList 存储的对象数量 |
| boolean remove(Object object) | 删除存储的某个对象 |
| E remove(int lcoation) | 删除位于 location 的对象 |
| boolean removeAll(Collection<?> collection) | 删除存储的某个 Collection 对象 |
| Object [] toArray() | ArrayList 转数组 |
| List<’E’> subList(int start, int end) | 获取位于 start 与 end 之间的 List |
| void clone() | 克隆 ArrayList |
| void clear() | 移除 ArrayList 中所有对象 |
| Iterator<’E’> iterator() | 获取该 ArrayList 对应的迭代器对象 |
ArrayList 应用示例
1. ArrayList 与数组之间的转换
// 转数组
List<String> list = new ArrayList<>();
String[] strings = new String[list.size()];
list.toArray(strings);
// 或者
String[] strings = (String[])list.toArray(new String[list.size()]);
// 数组转List
// 法1 快速,但是以视图形式返回,无法对数据进行删除及添加操作;
// 可用 set() 方法修改元素,但是原始List数据会随之改变
String[] s = {"abc", "def", "ghi"};
List<String> list = java.util.Arrays.asList(s);
//法 2 慢,但是新生成一个ArrayList,可对List进行操作不会对原对象产生影响
List<String> assertList = new ArrayList();
Collections.addAll(assertList, strings);
2. ArrayList 遍历方式
List<Integer> list = new ArrayList<>(Arrays.asList(1,2,3,4,5));
// 第一种,通过迭代器遍历。即通过Iterator去遍历。
Integer value = null;
Iterator iter = list.iterator();
while (iter.hasNext()) {
value = (Integer)iter.next();
}
// 第二种,随机访问,通过索引值去遍历。
Integer value = null;
int size = list.size();
for (int i=0; i < size; i++) {
value = (Integer)list.get(i);
}
// 第三种,for循环遍历。
Integer value = null;
for (Integer integer: list) {
value = integer;
}
// 第四种,利用Stream API的 stream.forEach()方法依次获取。
list.forEach(num -> System.out.println(num));
3. 初始化
// 第一种方式 Arrays.asList()方法
ArrayList<Integer> list = new Arraylist<>(Arrays.asList(1, 2, 3));
// 第二种方法 常规方式
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
//或者
List innerList = Arrays.asList(1, 2, 3);
list.addAll(innerList);
// 第三种方法 使用生成匿名内部类
ArrayList<Integer> list = new ArrayList<>(){
{
add(1);
add(2);
add(3);
}
};
// 第四种方式 使用Collection.nCopies
int element = 1;
ArrayList<Integer> list = new ArrayList<>(Collections.nCopies(2, element)); //复制伍分到list中。
4. 打印信息
由于 ArrayList 内部实现了 toString () 方法,所以可以直接打印
ArrayList<Integer> list = new ArrayList<>(Arrays.asList(1, 2, 3));
System.out.println(list);
对于数组信息的打印
int[] A = {1, 2, 3};
// 方法一
for(Integer i: A){
System.out.println(i);
}
//方法二
System.out.println(Arrays.toString(A));
5. 大量头部的增删操作
ArrayList 是数组实现的,使用的是连续的内存空间,当有在数组头部将元素添加或者删除的时候,需要对头部以后的数据进行复制并重新排序,效率很低。针对有大量类似操作的场景,出于性能考虑,我们应该使用 LinkedList 代替。
由于 LinkedList 是基于链表实现,当需要操作的元素位置位于 List 前半段时,就从头开始遍历,马上找到后将把元素在相应的位置进行插入或者删除操作。
参考资料
- ArrayList 源码剖析: http://www.spring4all.com/article/16262
Java Set
概述
Set 继承自集合(Collection),该集合不能包含相同的元素。
Set 里面进行元素是否相同的判定是通过 Object 类自带的 equals() 实现。
Set 最多可存储一个 null 元素。
Set 只是一个抽象的 接口,具体的使用还要用具体的实现,如 HashSet、TreeSet 等。
常用方法
因为 Set 继承自集合 Collection,所以具有集合的方法。
| 方法 | 描述 |
|---|---|
| int size() | 返回 Set 里面存储的元素个数。 |
| boolean isEmpty() | 如果没有元素,返回 true。 |
| boolean add(E e) | 如果 Set 里面没有包含元素 e,就将其加入。 |
| boolean addAll(Collection<? extends E>c) | 如果指定集合中的元素不存在 Set 中,就将其加入 Set。如果该 Collection 也是一个 Set,相当于对这两个 Set 取并集。 |
| boolean contains(Object o) | 是否包含特定的元素 o。 |
| boolean containsAll(Collecton< ? >c) | 该 Set 是否包含指定 Collection 的所有元素。 |
| void clear() | 清除所有元素。 |
| boolean remove(Object o) | 删除指定元素。 |
| boolean removeAll(Collection< ? >c) | 删除 Set 中存在于该 Collection 里的元素。 |
| Object[ ] toArray() | 将 Set 转化为数组。 |
| < T > T[ ] toArray(T[ ] a) | 返回所有的 Set 元素并存储在 Array 中。如果 a 的长度大于 Set 长度,则多余空间以 null 补全。 |
| Iterator< E > iterator() | 返回一个该 Set 的迭代器 |
| default Spliterator< E > spliterator() | 在该集合中创建拆分器。 |
常用 Set 实现
HashSet
HashSet 的方法基本与 Set 一致,只不过多了一个 Object clone() 方法(浅复制,只复制地址)。
主要方法包括:
add()
clear()
clone()
contains()
isEmpty()
iterator()
remove()
size()
spliterator()
HashSet 底层是基于 HashMap 实现的。即通过 HashMap 的键唯一性实现。
构造方法示例
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
// 该构造方法为LinkedHashSet实现准备
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
LinkedHashSet
LinkedHashSet 保存了元素的顺序,即插入时的顺序,再使用 iterator 遍历时会按顺序遍历。
LinkedHashSet 底层也是根据 LinkHashMap 实现的。通过父类 HashSet 的构造方法,调用 LinkHashMap。
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
继承自 HashSet,实现了接口 Serializable 及 Cloneable。
Serializable 是一个空接口,是一个序列化的标记,用来告诉 JVM 该类可以序列化。
序列化就是把对象的状态转化为可存储和传输的格式(如二进制流);反序列化就是序列化的逆过程,根据序列化后的数据重新恢复对象及其状态。
TreeSet
可实现排序的 Set,排序规则可以是自带的或者通过 Comparator 实现。
基础操作(add,contains and remove)的耗时是 log (n)。
实现了 NavigableSet 接口,该接口是基于 TreeMap 的。
TreeSet 底层是基于 TreeMap 实现,所以对于系统内部类例如 Integer、String 等,由于实现了 Comparable 接口,可直接进行存储;对于自定义的类,必须实现 Comparable 接口并重写 comparaTo()方法,这样 TreeSet 才能根据排序规则进行排序。
TreeSet 不能有重复元素。
TreeSet 的存取不如 HashSet 快。
comparaTo() 方法在被调用过程中,如果返回真值(或大于零的数),就认为新插入元素大于根元素,存入右节点,此时为顺序排列;反之存入左节点,为逆序排列。
构造函数:
| 序号 | 构造函数的说明 |
|---|---|
| 1 | TreeSet (),此构造函数构造空树集,将在根据其元素的自然顺序按升序排序。 |
| 2 | TreeSet (集合 c),此构造函数生成树的集合,它包含的元素的集合 c。 |
| 3 | TreeSet (比较器 comp),此构造函数构造一个空树集,将根据给定的比较器进行排序。 |
| 4 | TreeSet (SortedSet ss),此构造函数生成包含给定 SortedSet 的元素 TreeSet |
常用方法:
| 修饰符和类型 | 方法和描述 |
|---|---|
| boolean | add (E e),将指定的元素添加到这套,如果它已不存在。 |
| boolean | addAll (Collection<? extends E> c),在加入这一组指定的集合中添加的所有元素。 |
| E | ceiling (E e),返回最小的元素在这一组大于或等于给定的元素,则 null 如果没有这样的元素。 |
| void | clear (),从这一组中移除所有元素。 |
| Object | clone (),返回此 TreeSet 实例浅表副本。 |
| Comparator<? super E> | comparator (),返回用于排序在这集,或空元素,如果这套使用自然排序其元素的比较。 |
| boolean | contains (Object o),如果此集合包含指定的元素,则返回 true 。 |
| Iterator | descendingIterator (),返回迭代器中这套降序排序的元素。 |
| NavigableSet | descendingSet (),返回逆序视图中包含的元素这一套。 |
| E | first (),返回第一个 (最低) 元素当前在这一套。 |
| E | floor (E e),返回的最大元素在这一组小于或等于 null 如果没有这样的元素。 |
| SortedSet | headSet (E toElement),返回其元素是严格小于 toElement 这套的部分视图. |
| NavigableSet | headSet (E toElement, boolean inclusive),返回一个视图的这部分设置的元素都小于 (或等于,如果 inclusive 是真的) toElement. |
| E | higher (E e),返回最小的元素在这套严格大于给定的元素,则 null 如果没有这样的元素。 |
| boolean | isEmpty (),如果此集不包含任何元素,则返回 true 。 |
| Iterator | iterator (),返回迭代器中这套以升序排序的元素。 |
| E | last (),在这套目前返回的最后一个 (最高) 的元素。 |
| E | lower (E e),在这一套严格的小于给定的元素,则 null 返回的最大元素,如果没有这样的元素。 |
| E | pollFirst (),检索和删除第一个 (最低) 元素,或如果此集合为空,则返回 null 。 |
| E | pollLast (),检索和删除的最后一个 (最高) 的元素,或如果此集合为空,则返回 null 。 |
| boolean | remove (Object o),从这一组中移除指定的元素,如果它存在。 |
| int | size (),在这套 (其基数) 中返回的元素的数目。 |
| NavigableSet | subSet (E fromElement, boolean fromInclusive, E toElement, boolean toInclusive),返回此集的部分视图的元素范围从 fromElement 到 toElement. |
| SortedSet | subSet (E fromElement, E toElement),返回视图的部分的这一套的元素范围从 fromElement,具有包容性,到 toElement,独家。 |
| SortedSet | tailSet (E fromElement),返回其元素是大于或等于 fromElement 这套的部分视图. |
| NavigableSet | tailSet (E fromElement, boolean inclusive),返回其元素是大于 (或等于,如果 inclusive 是真的) 这套的部分视图 fromElement. |
实现原理
TreeSet 底层依赖于 TreeMap,通过 TreeMap 来作为存储 TreeSet 的容易,键值保证了元素的唯一性。
采用 “红黑树” 的排序二叉树保存 Map 中的每个 Entry,每个 Entry 被当做 “红黑树” 的一个节点。
“红黑树” 是一种平衡二叉查找树,树中节点都大于等于左子树所有节点,且小于等于右子树左右节点。
TreeSet 部分源码
package java.util;
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
// 使用NavigableMap对象的key来保存Set集合的元素
private transient NavigableMap<E,Object> m;
//使用PRESENT作为Map集合中的value
private static final Object PRESENT = new Object();
// 不带参数的构造函数。创建一个空的TreeMap
//以自然排序方法创建一个新的TreeMap,再根据该TreeMap创建一个TreeSet
//使用该TreeMap的key来保存Set集合的元素
public TreeSet() {
this(new TreeMap<E,Object>());
}
// 将TreeMap赋值给 "NavigableMap对象m"
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
//以定制排序的方式创建一个新的TreeMap。根据该TreeMap创建一个TreeSet
//使用该TreeMap的key来保存set集合的元素
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<E,Object>(comparator));
}
// 创建TreeSet,并将集合c中的全部元素都添加到TreeSet中
public TreeSet(Collection<? extends E> c) {
this();
// 将集合c中的元素全部添加到TreeSet中
addAll(c);
}
// 创建TreeSet,并将s中的全部元素都添加到TreeSet中
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}
// 返回TreeSet的顺序排列的迭代器。
// 因为TreeSet时TreeMap实现的,所以这里实际上时返回TreeMap的“键集”对应的迭代器
public Iterator<E> iterator() {
return m.navigableKeySet().iterator();
}
// 返回TreeSet的逆序排列的迭代器。
// 因为TreeSet时TreeMap实现的,所以这里实际上时返回TreeMap的“键集”对应的迭代器
public Iterator<E> descendingIterator() {
return m.descendingKeySet().iterator();
}
// 返回TreeSet的大小
public int size() {
return m.size();
}
// 返回TreeSet是否为空
public boolean isEmpty() {
return m.isEmpty();
}
// 返回TreeSet是否包含对象(o)
public boolean contains(Object o) {
return m.containsKey(o);
}
// 添加e到TreeSet中
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
// 删除TreeSet中的对象o
public boolean remove(Object o) {
return m.remove(o)==PRESENT;
}
// 清空TreeSet
public void clear() {
m.clear();
}
// 将集合c中的全部元素添加到TreeSet中
public boolean addAll(Collection<? extends E> c) {
// Use linear-time version if applicable
if (m.size()==0 && c.size() > 0 &&
c instanceof SortedSet &&
m instanceof TreeMap) {
//把C集合强制转换为SortedSet集合
SortedSet<? extends E> set = (SortedSet<? extends E>) c;
//把m集合强制转换为TreeMap集合
TreeMap<E,Object> map = (TreeMap<E, Object>) m;
Comparator<? super E> cc = (Comparator<? super E>) set.comparator();
Comparator<? super E> mc = map.comparator();
//如果cc和mc两个Comparator相等
if (cc==mc || (cc != null && cc.equals(mc))) {
//把Collection中所有元素添加成TreeMap集合的key
map.addAllForTreeSet(set, PRESENT);
return true;
}
}
return super.addAll(c);
}
// 返回子Set,实际上是通过TreeMap的subMap()实现的。
public NavigableSet<E> subSet(E fromElement, boolean fromInclusive,
E toElement, boolean toInclusive) {
return new TreeSet<E>(m.subMap(fromElement, fromInclusive,
toElement, toInclusive));
}
// 返回Set的头部,范围是:从头部到toElement。
// inclusive是是否包含toElement的标志
public NavigableSet<E> headSet(E toElement, boolean inclusive) {
return new TreeSet<E>(m.headMap(toElement, inclusive));
}
// 返回Set的尾部,范围是:从fromElement到结尾。
// inclusive是是否包含fromElement的标志
public NavigableSet<E> tailSet(E fromElement, boolean inclusive) {
return new TreeSet<E>(m.tailMap(fromElement, inclusive));
}
// 返回子Set。范围是:从fromElement(包括)到toElement(不包括)。
public SortedSet<E> subSet(E fromElement, E toElement) {
return subSet(fromElement, true, toElement, false);
}
// 返回Set的头部,范围是:从头部到toElement(不包括)。
public SortedSet<E> headSet(E toElement) {
return headSet(toElement, false);
}
// 返回Set的尾部,范围是:从fromElement到结尾(不包括)。
public SortedSet<E> tailSet(E fromElement) {
return tailSet(fromElement, true);
}
// 返回Set的比较器
public Comparator<? super E> comparator() {
return m.comparator();
}
// 返回Set的第一个元素
public E first() {
return m.firstKey();
}
// 返回Set的最后一个元素
public E first() {
public E last() {
return m.lastKey();
}
// 返回Set中小于e的最大元素
public E lower(E e) {
return m.lowerKey(e);
}
// 返回Set中小于/等于e的最大元素
public E floor(E e) {
return m.floorKey(e);
}
// 返回Set中大于/等于e的最小元素
public E ceiling(E e) {
return m.ceilingKey(e);
}
// 返回Set中大于e的最小元素
public E higher(E e) {
return m.higherKey(e);
}
// 获取第一个元素,并将该元素从TreeMap中删除。
public E pollFirst() {
Map.Entry<E,?> e = m.pollFirstEntry();
return (e == null)? null : e.getKey();
}
// 获取最后一个元素,并将该元素从TreeMap中删除。
public E pollLast() {
Map.Entry<E,?> e = m.pollLastEntry();
return (e == null)? null : e.getKey();
}
// 克隆一个TreeSet,并返回Object对象
public Object clone() {
TreeSet<E> clone = null;
try {
clone = (TreeSet<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
clone.m = new TreeMap<E,Object>(m);
return clone;
}
// java.io.Serializable的写入函数
// 将TreeSet的“比较器、容量,所有的元素值”都写入到输出流中
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
s.defaultWriteObject();
// 写入比较器
s.writeObject(m.comparator());
// 写入容量
s.writeInt(m.size());
// 写入“TreeSet中的每一个元素”
for (Iterator i=m.keySet().iterator(); i.hasNext(); )
s.writeObject(i.next());
}
// java.io.Serializable的读取函数:根据写入方式读出
// 先将TreeSet的“比较器、容量、所有的元素值”依次读出
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden stuff
s.defaultReadObject();
// 从输入流中读取TreeSet的“比较器”
Comparator<? super E> c = (Comparator<? super E>) s.readObject();
TreeMap<E,Object> tm;
if (c==null)
tm = new TreeMap<E,Object>();
else
tm = new TreeMap<E,Object>(c);
m = tm;
// 从输入流中读取TreeSet的“容量”
int size = s.readInt();
// 从输入流中读取TreeSet的“全部元素”
tm.readTreeSet(size, s, PRESENT);
}
// TreeSet的序列版本号
private static final long serialVersionUID = -2479143000061671589L;
}
我们发现,TreeSet 底层是依靠 TreeMap 对 key 进行存储排序实现的,现在看一下 TreeMap 的部分源码。
TreeMap 的 put () 方法
public V put(K key, V value) {
//定义一个t来保存根元素
Entry<K,V> t = root;
//如果t==null,表明是一个空链表
if (t == null) {
//如果根节点为null,将传入的键值对构造成根节点(根节点没有父节点,所以传入的父节点为null)
root = new Entry<K,V>(key, value, null);
//设置该集合的size为1
size = 1;
//修改此时+1
modCount++;
return null;
}
// 记录比较结果
int cmp;
Entry<K,V> parent;
// 分割比较器和可比较接口的处理
Comparator<? super K> cpr = comparator;
// 有比较器的处理,即采用定制排序
if (cpr != null) {
// do while实现在root为根节点移动寻找传入键值对需要插入的位置
do {
//使用parent上次循环后的t所引用的Entry
// 记录将要被掺入新的键值对将要节点(即新节点的父节点)
parent = t;
// 使用比较器比较父节点和插入键值对的key值的大小
cmp = cpr.compare(key, t.key);
// 插入的key较大
if (cmp < 0)
t = t.left;
// 插入的key较小
else if (cmp > 0)
t = t.right;
// key值相等,替换并返回t节点的value(put方法结束)
else
return t.setValue(value);
} while (t != null);
}
// 没有比较器的处理
else {
// key为null抛出NullPointerException异常
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
// 与if中的do while类似,只是比较的方式不同
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// 没有找到key相同的节点才会有下面的操作
// 根据传入的键值对和找到的“父节点”创建新节点
Entry<K,V> e = new Entry<K,V>(key, value, parent);
// 根据最后一次的判断结果确认新节点是“父节点”的左孩子还是又孩子
if (cmp < 0)
parent.left = e;
else
parent.right = e;
// 对加入新节点的树进行调整
fixAfterInsertion(e);
// 记录size和modCount
size++;
modCount++;
// 因为是插入新节点,所以返回的是null
return null;
}
发现在插入过程中,会进行二叉树排序的判定:
- 如果新增节点大于当前节点且当前节点的右子节点存在,则以右子节点作为当前节点。并继续循环
- 如果新增节点小于当前节点且当前节点的左子节点存在,则以左子节点作为当前节点。并继续循环
- 如果新增节点等于当前节点,则新增节点覆盖当前节点,并结束循环。
TreeMap 的 get () 方法
public V get(Object key) {
//根据key取出Entry
Entry<K,V> p = getEntry(key);
//取出Entry所包含的value
return (p==null ? null : p.value);
}
关键在于 getEntry() 是怎么根据 Comparable 取出对应 Entry 的。
final Entry<K,V> getEntry(Object key) {
// 如果有比较器,返回getEntryUsingComparator(Object key)的结果
if (comparator != null)
return getEntryUsingComparator(key);
// 查找的key为null,抛出NullPointerException
if (key == null)
throw new NullPointerException();
// 如果没有比较器,而是实现了可比较接口
//将key强制转换为Comparable接口
Comparable<? super K> k = (Comparable<? super K>) key;
// 获取根节点
Entry<K,V> p = root;
// 从根节点开始对树进行遍历查找节点
while (p != null) {
// 把key和当前节点的key进行比较
int cmp = k.compareTo(p.key);
// key小于当前节点的key
if (cmp < 0)
// p “移动”到左节点上
p = p.left;
// key大于当前节点的key
else if (cmp > 0)
// p “移动”到右节点上
p = p.right;
// key值相等则当前节点就是要找的节点
else
// 返回找到的节点
return p;
}
// 没找到则返回null
return null;
}
其实就是一个二叉查找,根据 Comparable 进行 key 大小的判断。如果采用定制比较器,则采用 getEntryUsingComparator() 方法。
final Entry<K,V> getEntryUsingComparator(Object key) {
K k = (K) key;
// 获取比较器
Comparator<? super K> cpr = comparator;
// 其实在调用此方法的get(Object key)中已经对比较器为null的情况进行判断,这里是防御性的判断
if (cpr != null) {
// 获取根节点
Entry<K,V> p = root;
// 遍历树
while (p != null) {
// 获取key和当前节点的key的比较结果
int cmp = cpr.compare(k, p.key);
// 查找的key值较小
if (cmp < 0)
// p“移动”到左孩子
p = p.left;
// 查找的key值较大
else if (cmp > 0)
// p“移动”到右节点
p = p.right;
// key值相等
else
// 返回找到的节点
return p;
}
}
// 没找到key值对应的节点,返回null
return null;
}
Java Stack
Stack简介
Stack是栈。它的特性是:先进后出(FILO, First In Last Out)。
java工具包中的Stack是继承于Vector(矢量队列)的,由于Vector是通过数组实现的,这就意味着,Stack也是通过数组实现的,而非链表。当然,我们也可以将LinkedList当作栈来使用!在“Java 集合系列06之 Vector详细介绍(源码解析)和使用示例”中,已经详细介绍过Vector的数据结构,这里就不再对Stack的数据结构进行说明了。
Stack和Collection的关系如下图:

Stack的构造函数
Stack只有一个默认构造函数,如下:
Stack()
Stack的API
Stack是栈,它常用的API如下:
boolean empty()
synchronized E peek()
synchronized E pop()
E push(E object)
synchronized int search(Object o)
由于Stack和继承于Vector,因此它也包含Vector中的全部API。
Java deque
ArrayDeque , LinkedList , Stack的关系差不多就是下图那样

Stack实现了Vector接口,LinkedList实现了Deque,List接口,ArrayDeque实现了Deque接口
为什么不推荐使用Stack?
因为Vector是当初JAVA曾经写得不太行的类,所以Stack也不太行。
Vector不行是因为效率不太行,很多方法都用了synchronized修饰,虽然线程安全,但是像ArrayDeque,LinkedList这些线程不安全的,在需要安全的时候也可以用Collections.synchronizedCollection()转化成线程安全的,所以Vector就没什么用处了
再根据仿生学
Stack只能上进上出,有点像刺胞动物(腔肠动物),就是那种从哪里吃进去就哪里拉出来的那种生活在海洋里的比较低级的生物。
Deque上进上出,上进下出,甚至下进上出,非常上流,只有你想不到,没有我Deque做不到的。
现在不会还有人不知道使用栈的时候选谁吧?
ArrayDeque与LinkList区别:
ArrayDeque:
- 数组结构
- 插入元素不能为null
- 无法确定数据量时,后期扩容会影响效率
LinkList:
- 链表结构
- 插入元素能为null
- 无法确定数据量时,有更好表现
ArrayDeque构造函数:
- 实例化一个有16个初始位置(后续位置不够会自动扩容)的数组的ArrayDeque,后面+的那个1应该是去干什么奇怪的事情了。

- 实例化一个有自定义初始位置位置数组的ArrayDeque。

- 传入一个集合,复制他,再实例化

LinkList构造函数:
和上面的那个差不多,就那样吧
Deque中常用方法:
以这2个为基础整出来的Deque除了结构不一样,方法都一样的。
- 普通队列(一端进另一端出):
Queue queue = new LinkedList()或Deque deque = new LinkedList()
- 双端队列(两端都可进出)
Deque deque = new LinkedList()
- 堆栈
Deque deque = new LinkedList()
注意:Java堆栈Stack类已经过时,Java官方推荐使用Deque替代Stack使用。Deque堆栈操作方法:push()、pop()、peek()。
此接口定义在双端队列两端访问元素的方法。提供插入、移除和检查元素的方法。每种方法都存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(null 或 false,具体取决于操作)。插入操作的后一种形式是专为使用有容量限制的 Deque 实现设计的;在大多数实现中,插入操作不能失败。
下表总结了上述 12 种方法:
| 第一个元素 (头部) | 最后一个元素 (尾部) | |||
|---|---|---|---|---|
| 抛出异常 | 特殊值 | 抛出异常 | 特殊值 | |
| 插入 | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| 删除 | removeFirst() | pollFirst() | removeLast() | pollLast() |
| 检查 | getFirst() | peekFirst() | getLast() | peekLast() |
Deque接口扩展(继承)了 Queue 接口。在将双端队列用作队列时,将得到 FIFO(先进先出)行为。将元素添加到双端队列的末尾,从双端队列的开头移除元素。从 Queue 接口继承的方法完全等效于 Deque 方法,如下表所示:
| Queue方法 | 等效Deque方法 |
|---|---|
| add(e) | addLast(e) |
| offer(e) | offerLast(e) |
| remove() | removeFirst() |
| poll() | pollFirst() |
| element() | getFirst() |
| peek() | peekFirst() |
双端队列也可用作 LIFO(后进先出)堆栈。应优先使用此接口而不是遗留 Stack 类。在将双端队列用作堆栈时,元素被推入双端队列的开头并从双端队列开头弹出。堆栈方法完全等效于 Deque 方法,如下表所示:
| 堆栈方法 | 等效Deque方法 |
|---|---|
| push(e) | addFirst(e) |
| pop() | removeFirst() |
| peek() | peekFirst() |
| Modifier and Type | Method and Description |
|---|---|
| boolean | add(E e) Inserts the specified element into the queue represented by this deque (in other words, at the tail of this deque) if it is possible to do so immediately without violating capacity restrictions, returning true upon success and throwing an IllegalStateException if no space is currently available. |
| void | addFirst(E e) Inserts the specified element at the front of this deque if it is possible to do so immediately without violating capacity restrictions, throwing an IllegalStateException if no space is currently available. |
| void | addLast(E e) Inserts the specified element at the end of this deque if it is possible to do so immediately without violating capacity restrictions, throwing an IllegalStateException if no space is currently available. |
| boolean | contains(Object o) Returns true if this deque contains the specified element. |
| Iterator[E](https://docs.oracle.com/javase/8/docs/api/java/util/Deque.html) | descendingIterator() Returns an iterator over the elements in this deque in reverse sequential order. |
| E | element() Retrieves, but does not remove, the head of the queue represented by this deque (in other words, the first element of this deque). |
| E | getFirst() Retrieves, but does not remove, the first element of this deque. |
| E | getLast() Retrieves, but does not remove, the last element of this deque. |
| Iterator[E](https://docs.oracle.com/javase/8/docs/api/java/util/Deque.html) | iterator() Returns an iterator over the elements in this deque in proper sequence. |
| boolean | offer(E e) Inserts the specified element into the queue represented by this deque (in other words, at the tail of this deque) if it is possible to do so immediately without violating capacity restrictions, returning true upon success and false if no space is currently available. |
| boolean | offerFirst(E e) Inserts the specified element at the front of this deque unless it would violate capacity restrictions. |
| boolean | offerLast(E e) Inserts the specified element at the end of this deque unless it would violate capacity restrictions. |
| E | peek() Retrieves, but does not remove, the head of the queue represented by this deque (in other words, the first element of this deque), or returns null if this deque is empty. |
| E | peekFirst() Retrieves, but does not remove, the first element of this deque, or returns null if this deque is empty. |
| E | peekLast() Retrieves, but does not remove, the last element of this deque, or returns null if this deque is empty. |
| E | poll() Retrieves and removes the head of the queue represented by this deque (in other words, the first element of this deque), or returns null if this deque is empty. |
| E | pollFirst() Retrieves and removes the first element of this deque, or returns null if this deque is empty. |
| E | pollLast() Retrieves and removes the last element of this deque, or returns null if this deque is empty. |
| E | pop() Pops an element from the stack represented by this deque. |
| void | push(E e) Pushes an element onto the stack represented by this deque (in other words, at the head of this deque) if it is possible to do so immediately without violating capacity restrictions, throwing an IllegalStateException if no space is currently available. |
| E | remove() Retrieves and removes the head of the queue represented by this deque (in other words, the first element of this deque). |
| boolean | remove(Object o) Removes the first occurrence of the specified element from this deque. |
| E | removeFirst() Retrieves and removes the first element of this deque. |
| boolean | removeFirstOccurrence(Object o) Removes the first occurrence of the specified element from this deque. |
| E | removeLast() Retrieves and removes the last element of this deque. |
| boolean | removeLastOccurrence(Object o) Removes the last occurrence of the specified element from this deque. |
| int | size() Returns the number of elements in this deque. |
PriorityQueue 默认升序 小顶堆
| Modifier and Type | Method and Description |
|---|---|
| boolean | add(E e) Inserts the specified element into this priority queue. |
| void | clear() Removes all of the elements from this priority queue. |
| Comparator<? super E> | comparator() Returns the comparator used to order the elements in this queue, or null if this queue is sorted according to the natural ordering of its elements. |
| boolean | contains(Object o) Returns true if this queue contains the specified element. |
| Iterator[E](https://docs.oracle.com/javase/8/docs/api/java/util/PriorityQueue.html) | iterator() Returns an iterator over the elements in this queue. |
| boolean | offer(E e) Inserts the specified element into this priority queue. |
| E | peek() Retrieves, but does not remove, the head of this queue, or returns null if this queue is empty. |
| E | poll() Retrieves and removes the head of this queue, or returns null if this queue is empty. |
| boolean | remove(Object o) Removes a single instance of the specified element from this queue, if it is present. |
| int | size() Returns the number of elements in this collection. |
| Spliterator[E](https://docs.oracle.com/javase/8/docs/api/java/util/PriorityQueue.html) | spliterator() Creates a late-binding and fail-fast Spliterator over the elements in this queue. |
| Object[] | toArray() Returns an array containing all of the elements in this queue. |
| toArray(T[] a) Returns an array containing all of the elements in this queue; the runtime type of the returned array is that of the specified array. |
import java.util.PriorityQueue;
import java.util.Queue;
public class Main {
public static void main(String[] args) {
Queue<String> q = new PriorityQueue<>();
// 添加3个元素到队列:
q.offer("apple");
q.offer("pear");
q.offer("banana");
System.out.println(q.poll()); // apple
System.out.println(q.poll()); // banana
System.out.println(q.poll()); // pear
System.out.println(q.poll()); // null,因为队列为空
}
}
output:
apple
banana
pear
null
import java.util.Comparator;
import java.util.PriorityQueue;
import java.util.Queue;
public class Main {
public static void main(String[] args) {
Queue<User> q = new PriorityQueue<>(new UserComparator());
// 添加3个元素到队列:
q.offer(new User("Bob", "A1"));
q.offer(new User("Alice", "A2"));
q.offer(new User("Boss", "V1"));
System.out.println(q.poll()); // Boss/V1
System.out.println(q.poll()); // Bob/A1
System.out.println(q.poll()); // Alice/A2
System.out.println(q.poll()); // null,因为队列为空
}
}
class UserComparator implements Comparator<User> {
public int compare(User u1, User u2) {
if (u1.number.charAt(0) == u2.number.charAt(0)) {
// 如果两人的号都是A开头或者都是V开头,比较号的大小:
return u1.number.compareTo(u2.number);
}
if (u1.number.charAt(0) == 'V') {
// u1的号码是V开头,优先级高:
return -1;
} else {
return 1;
}
}
}
class User {
public final String name;
public final String number;
public User(String name, String number) {
this.name = name;
this.number = number;
}
public String toString() {
return name + "/" + number;
}
}
//自定义比较器,降序排列 匿名内部类
static Comparator<Integer> cmp = new Comparator<Integer>() {
public int compare(Integer e1, Integer e2) {
return e2 - e1;
}
};
public static void main(String[] args) {
//不用比较器,默认升序排列 小顶堆
Queue<Integer> q = new PriorityQueue<>();
q.add(3);
q.add(2);
q.add(4);
while(!q.isEmpty())
{
System.out.print(q.poll()+" ");
}
/**
* 输出结果
* 2 3 4
*/
//使用自定义比较器,降序排列 大顶堆
Queue<Integer> qq = new PriorityQueue<>(cmp);
qq.add(3);
qq.add(2);
qq.add(4);
while(!qq.isEmpty())
{
System.out.print(qq.poll()+" ");
}
/**
* 输出结果
* 4 3 2
*/
}
// lambda表达式做比较器,比较简洁
PriorityQueue<Map.Entry<Integer, Integer>> maxHeap = new PriorityQueue<>((o1,o2)->o2.getValue()-o1.getValue());
数组排序
class Solution {
public int[][] merge(int[][] intervals) {
if(intervals.length < 2){
return intervals;
}
// 升序
Arrays.sort(intervals, new Comparator<int[]>() {
public int compare(int[] a, int[] b){
return a[0] - b[0];
}
});
List<int[]> res = new LinkedList<int[]>();
for(int i = 0; i < intervals.length; ++i){
int L = intervals[i][0], R = intervals[i][1];
if(res.size() == 0 || res.get(res.size() - 1)[1] < L){
res.add(new int[]{L, R});
}else{
res.get(res.size() - 1)[1] = Math.max(res.get(res.size() - 1)[1], R);
}
}
// List转数组
return res.toArray(new int[res.size()][]);
}
}
自定义比较器
Comparator和Comparable
Comporable是内部比较器,而Comparator是外部比较器,由于这两个都是接口,所以都需要去实现。
而实现Comporable接口则需要实现compareTo方法,实现Comparator需要实现compare方法。
Comparable接口一般由要比较的类(compareTo方法在要实现的类中实现,该类继承Comporable接口)实现,所以叫内部比较器。
comparator比较器一般是单独实现(该类继承Comporator接口),或者匿名内部类实现。
一个类,可以通过实现Comparable接口来自带有序性,也可以通过额外指定Comparator来附加有序性。
- Comparable为可排序的,实现该接口的类的对象自动拥有可排序功能。
- Comparator为比较器,实现该接口可以定义一个针对某个类的排序方式。
- Comparator与Comparable同时存在的情况下,前者优先级高。
```java
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class CompareTest {
public static void main(String[] args) {
List
list.add(new Student(1,”jj”));
list.add(new Student(4,”ww”));
list.add(new Student(3,”kk”));
list.add(new Student(2,”ll”));
Collections.sort(list); // 内部比较器:要排序的类实现Comparable接口,可以对自身进行比较
System.out.println(list);// (1,”jj”) (2,”ll”) (3,”kk”) (4,”ww”)
List<Teacher> t = new ArrayList<Teacher>(10);
t.add(new Teacher(1,12));
t.add(new Teacher(0,13));
t.add(new Teacher(0,14));
t.add(new Teacher(2,15));
Collections.sort(t,new StudentComparator()); //外部比较器:通过额外的类来实现Comparator接口
System.out.println(t); // (1,"jj") (3,"kk") (2,"ll") (4,"ww")
}
}
class Student implements Comparable {
int num;
String name;
public Student(int num, String name) {
this.num = num;
this.name = name;
}
@Override
public String toString() {
return "\r\tnum:"+num+" name:"+name+"\r";
}
// 通过num升序 Object可以为具体的类,省的转换
public int compareTo(Object o) {
Student tmp = (Student) o;
return this.num - tmp.num;
}
}
class StudentComparator implements Comparator{
// 通过名字第一个字母升序 Object可以为具体的类,省的转换
public int compare(Object o1, Object o2) {
Student t1 = (Student) o1;
Student t2 = (Student) o2;
return t1.name.charAt(0) - t2.name.charAt(0);
}
}
```

若有收获,就点个赞吧
0 人点赞
