题目
题目来源:力扣(LeetCode)
单词数组 words 的 有效编码 由任意助记字符串 s 和下标数组 indices 组成,且满足:
words.length == indices.length
助记字符串 s 以 ‘#’ 字符结尾
对于每个下标 indices[i] ,s 的一个从 indices[i] 开始、到下一个 ‘#’ 字符结束(但不包括 ‘#’)的 子字符串 恰好与 words[i] 相等
给你一个单词数组 words ,返回成功对 words 进行编码的最小助记字符串 s 的长度 。
示例 1:
输入:words = [“time”, “me”, “bell”]
输出:10
解释:一组有效编码为 s = “time#bell#” 和 indices = [0, 2, 5] 。
words[0] = “time” ,s 开始于 indices[0] = 0 到下一个 ‘#’ 结束的子字符串,如加粗部分所示 “time#bell#”
words[1] = “me” ,s 开始于 indices[1] = 2 到下一个 ‘#’ 结束的子字符串,如加粗部分所示 “time#bell#”
words[2] = “bell” ,s 开始于 indices[2] = 5 到下一个 ‘#’ 结束的子字符串,如加粗部分所示 “time#bell#”
示例 2:
输入:words = [“t”]
输出:2
解释:一组有效编码为 s = “t#” 和 indices = [0] 。
思路分析
思路:剔除重复词尾
首先,我们要理解题目中的“索引字符串”究竟是什么意思。题目中说,time 和 me 两个字符串都可以通过同一个索引 time# 编码。那么,time# 编码都可以表示哪些字符串呢?答案是 time、ime、me 和 e。这些字符串都是 time 的后缀。也就是说,如果 time 出现了,ime、me、e 这些单词都可以用 time 编码,不需要额外的编码了。
而如果两个字符串是 time 和 mime,它们虽然有相同的后缀 ime,但是开头的字母不一样,所以只能编码为 time#mime#。我们发现,只有一个单词完全包含另一个单词,才能让两个单词放进一个编码。
我们可以画一张图来看清楚这些字符串之间的关系: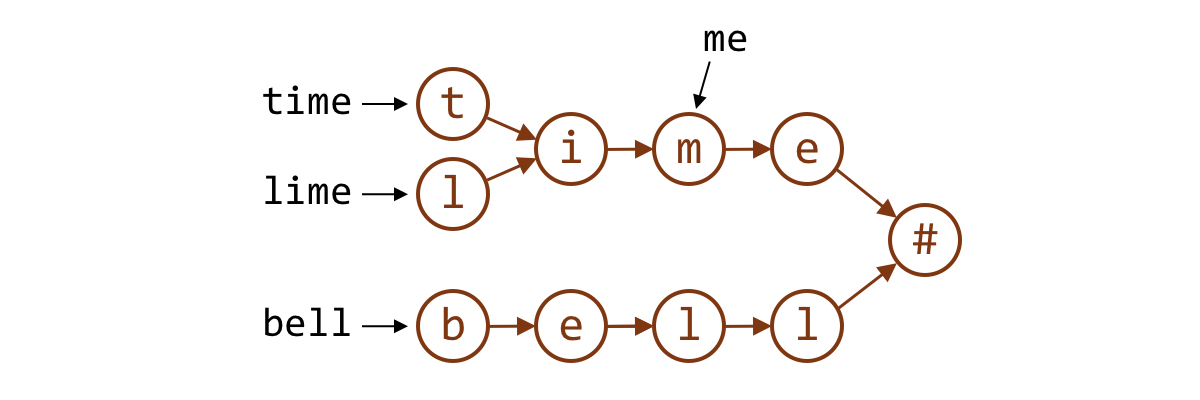
可以看到,字符串 me 的路径已经完全和 time 重合了,而 lime 和 time 只是部分重合。我们只需要把所有有自己独立起点的字符串作为编码字符串就可以了。
目标就是保留所有不是其他单词后缀的单词,最后的结果就是这些单词长度加一的总和,因为每个单词编码后后面还需要跟一个 # 符号。
我们对 words 中的每个元素的词尾做切片并比对,如果词尾出现在 words 中,则删除该元素。
/*** @param {string[]} words* @return {number}*/var minimumLengthEncoding = function (words) {let hashSet = new Set(words);for (let item of hashSet) {for (let i = 1; i < item.length; i++) {// 切片,看看是否词尾在 hashSet 中,切片从1开始,只看每个单词的词尾let target = item.slice(i);hashSet.has(target) && hashSet.delete(target);}}let result = 0;// 根据 hashSet 中剩余元素计算最终长度hashSet.forEach(item => result += item.length + 1)return result};
参考阅读
https://leetcode-cn.com/problems/short-encoding-of-words/solution/dan-ci-de-ya-suo-bian-ma-by-leetcode-solution/
https://leetcode-cn.com/problems/short-encoding-of-words/solution/wu-xu-zi-dian-shu-qing-qing-yi-fan-zhuan-jie-guo-j/

若有收获,就点个赞吧
0 人点赞
