Multiclass-Classification 多分类器
- Classification involving more than two classes (i.e., > 2 Classes)
- Method 1. One-vs.-all (OVA): Learn a classifier one at a time
- Given
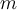 classes, train m classifiers: one for each class
classes, train m classifiers: one for each class - Classifier
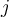 :treats tuples in class
:treats tuples in class 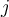 as positive & all others as negative
as positive & all others as negative - To classify a tuple
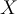 , the set of classifiers vote as an ensemble. If classifier
, the set of classifiers vote as an ensemble. If classifier 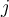 predicts the positive class, then class
predicts the positive class, then class 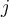 gets one vote. If classifier
gets one vote. If classifier 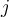 predicts the negative class then all non-
predicts the negative class then all non-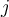 classes get one vote.
classes get one vote.
- Given
- Method 2. All-vs.-all (AVA): Learn a classifier for each pair of classes
- Given m classes, construct
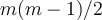 binary classifiers
binary classifiers - A classifier is trained using tuples of the two classes
- To classify a tuple
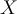 , each classifier votes.
, each classifier votes. 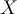 is assigned to the class with maximal vote
is assigned to the class with maximal vote
- Given m classes, construct
Comparison
- All-vs.-all tends to be superior to one-vs.-all
- Problem: Binary classifier is sensitive to errors, and errors affect vote count
Semi-supervised Classification 半监督学习分类器
Semi-supervised: Uses labeled and unlabeled data to build a classifier
- Self-training:
- Build a classifier using the labeled data
- Use it to label the unlabeled data, and those with the most confident label prediction are added to the set of labeled data
- Repeat the above process
- Advantage: easy to understand; disadvantage: may reinforce errors
Co-training: Use two or more classifiers to teach each other
- Use two disjoint and independent selections of attributes of each tuple to train two good classifiers, say
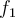 and
and 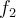
- Then
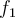 and
and 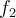 are used to predict the class label for unlabeled data tuples
are used to predict the class label for unlabeled data tuples 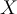
- Teach each other: The tuples in
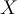 having the most confident prediction from
having the most confident prediction from 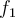 are added to the set of labeled training data for
are added to the set of labeled training data for 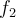 , & vice versa
, & vice versa - Retrain two classifiers using the extended training sets, using the same disjoint attribute selections
Active-Learning 主动学习
- Use two disjoint and independent selections of attributes of each tuple to train two good classifiers, say
Class labels are expensive to obtain
- Active learner: query human (oracle) for labels
- Pool-based approach: Uses a pool of unlabeled data
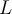 : a small subset of
: a small subset of 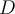 is labeled,
is labeled, 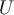 : a pool of unlabeled data in
: a pool of unlabeled data in 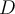
- Use a query function to carefully select one or more tuples from
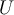 and request labels from an oracle (a human annotator)
and request labels from an oracle (a human annotator) - The newly labeled samples are added to
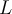 , and learn a model
, and learn a model - Goal: Achieve high accuracy using as few labeled data as possible
- Evaluated using learning curves: Accuracy as a function of the number of instances queried (# of tuples to be queried should be small)
Research issue: How to choose the data tuples to be queried?
Transfer learning: Build classifiers for one or more similar source tasks and apply to a target task
- vs Traditional learning: Build a new classifier for each new task

若有收获,就点个赞吧
0 人点赞
