Backpropagation 向后传播
The backpropagation algorithm, based on the gradient descent algorithm, is designed to train the weights and biases of a neural network. 基于梯度下降算法训练神经网络中的权值和偏差。
How does backpropagation work?
For training, each training tuple,is first normalised to [0.0 ~ 1.0].
The error is propagated backward by updating the weights and biases** to reflect the error of the network’s prediction for the dependent variable for a training tuple. 通过向后传播误差,更新权值和偏差,来反映神经网络对训练集对预测误差。
- For unit
 in the output layer, its error
in the output layer, its error 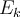 is computed by
is computed by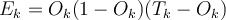 ,
,- where
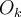 is the actual output of unit
is the actual output of unit 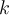 , and
, and 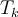 is the known target value of the given training tuple.
is the known target value of the given training tuple.
- To compute the error of a hidden layer unit
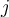 , the weighted sum of the errors of the units connected to unit
, the weighted sum of the errors of the units connected to unit 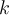 in the next layer are considered.
in the next layer are considered.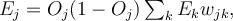
- where
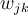 is the weight of the connection from unit
is the weight of the connection from unit 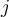 to a unit
to a unit 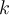 in the next higher layer.
in the next higher layer.
- The weights and biases are updated to reflect the propagated errors. 权值和偏差被更新以反映传播的误差。
- Each weight
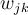 in the network is updated by the following equations, where
in the network is updated by the following equations, where 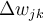 is the change in weight
is the change in weight 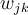 :
: - Each bias
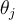 in the network is updated by the following equations, where
in the network is updated by the following equations, where 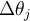 is the change in bias
is the change in bias 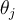 :
:
- Each weight
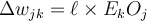
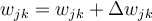
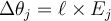
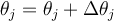
Learning rate: The parameter 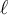 is the learning rate, typically, a value between 0.0 and 1.0. If the learning rate is too small, then learning (ie reduction in the Error) will occur at a very slow pace. If the learning rate is too large, then oscillation between inadequate solutions may occur. A rule of thumb is to set the learning rate to
is the learning rate, typically, a value between 0.0 and 1.0. If the learning rate is too small, then learning (ie reduction in the Error) will occur at a very slow pace. If the learning rate is too large, then oscillation between inadequate solutions may occur. A rule of thumb is to set the learning rate to 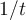 , where
, where 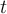 is the number of iterations through the training set so far. In principle the network should _converge _towards a minimal Error, but if this is not happening, try reducing this parameter value and retrain.
is the number of iterations through the training set so far. In principle the network should _converge _towards a minimal Error, but if this is not happening, try reducing this parameter value and retrain.
Updating schedules
- Case updating: The backpropagation algorithm given here updates the weights and biases immediately after the presentation of each tuple.
- Epoch updating: Alternatively, the weight and bias increments could be accumulated in variables, so that the weights and biases are updated after all the tuples in the training set have been presented.
- Either way, we keep updating until we have a satisfactory error; presenting each tuple of the training set many times over
- In theory, the mathematical derivation of backpropagation employs epoch updating, yet in practice, case updating is more common because it tends to yield more accurate results.

> Backpropagation algorithm from the textbook
How do you decide to terminate training?
- When your weights and biases are changing very little , ie. all the
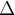 s are small; or 权值和偏差改变较小
s are small; or 权值和偏差改变较小 - Accuracy on the training set is good enough; or 准确度达标
- A prespecified number of epochs have passed. 许多预先规定的训练时段已经过去了。

若有收获,就点个赞吧
0 人点赞
