- Introduction to IR + Boolean model 信息检索介绍+布尔模型
- Ranked retrieval model 分级检索模型
- Evaluation of IR systems 信息检索系统评估
- Web search basics 网站搜索基础
Introduction to Boolean Retrieval
– Information Retrieval 信息检索
– Term-Document Matrix 术语-文档矩阵
– Inverted Index 倒序索引
– Boolean Retrieval with Inverted Index 倒序布尔检索
– Document Tokenization 文档编译
Information Retrieval
“Information Retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers).” Manning et al. “信息检索(IR)是从大量集合(通常存储在计算机上)中寻找满足信息需求的非结构化材料(通常是文档)
You may think of web search first, but there are many other cases
– E-mail search 邮件搜索
– Searching your laptop 个人电脑检索
– Corporate knowledge bases 企业知识库
– Image search, video search 图片,视频搜索
Why IR?
- information overload
Starting Point
- Collection : A set of documents
- Goal:Retrieve documents with information that is relevant to the user’s information need and helps the user complete a task 检索带有信息的文档 与用户信息需求相关的信息 需要并帮助用户完成任务
Key Objectives
- Scalability 拓展性
- Accuracy 精确性
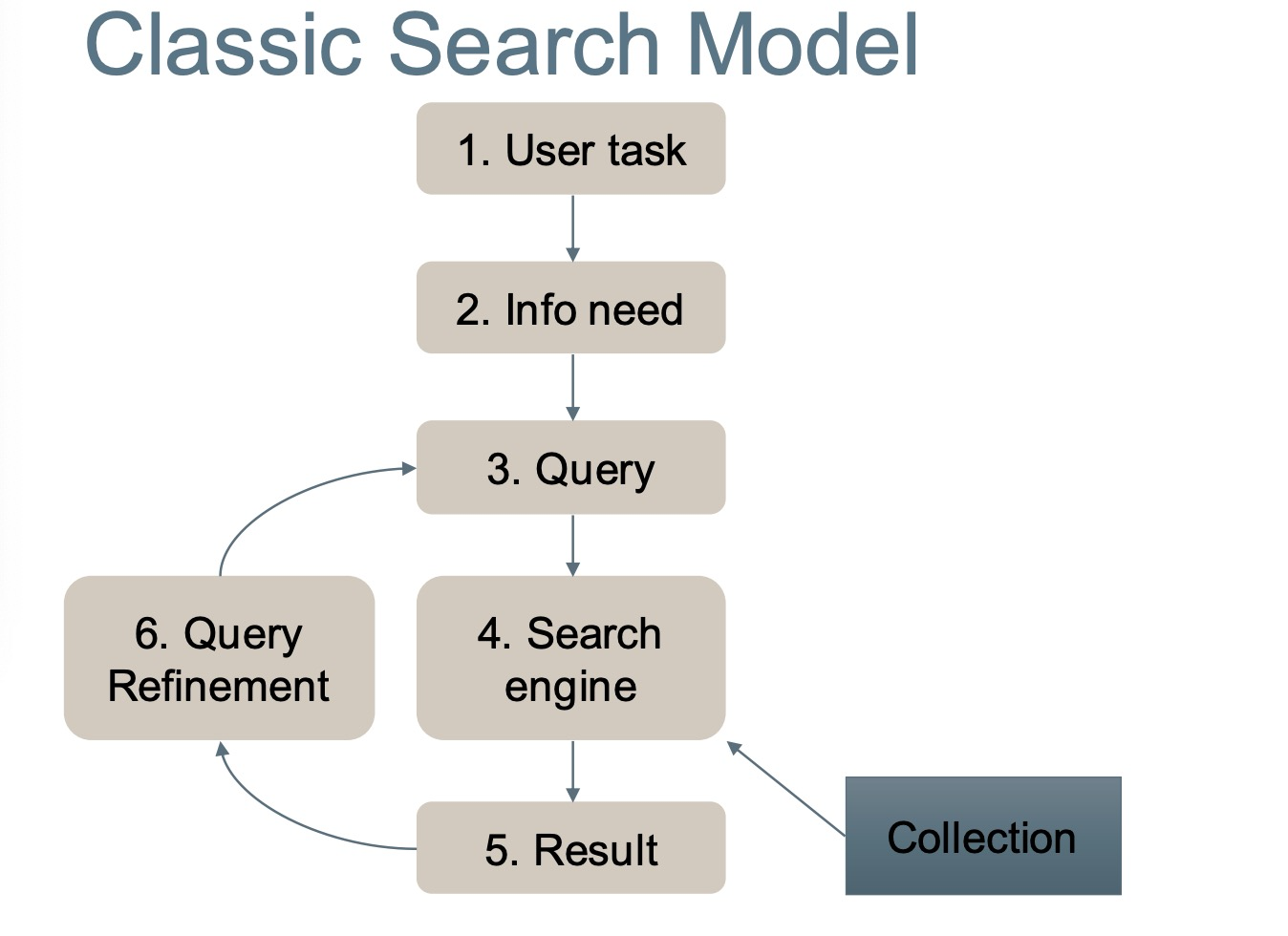
Quary and indexing
Indexing: Storing a mapping from terms to documents
Quarying: Looking up terms in the index and returning documents.
Search with Boolean query
Boolean query – E.g., “canberra” AND “healthcare” NOT “covid”
Procedures
– Lookup query term in the dictionary
– Retrieve the posting lists
– Operation • AND: intersect the posting lists • OR: union the posting list • NOT: diff the posting list
Retrieval procedure in modern IR
Boolean model provides all the ranking candidates
– Locate documents satisfying Boolean condition
• E.g., “obama healthcare” -> “obama” OR
“healthcare”
• Rank candidates by relevance
– Important: the notation of relevance
• Efficiency consideration
– Top-k retrieval (Google)


Efficient data structure tailored for boolean retrieval => Inverted index 布尔检索的高效数据结构——倒序索引
Inverted Index 倒序索引
- Inverted index consists of a dictionary and postings 倒序索引包含两部分
– Dictionary: a set of unique terms
– Posting: variable-size array that keeps the list of documents given term (sorted)
- INDEXER: Construct inverted index from raw text
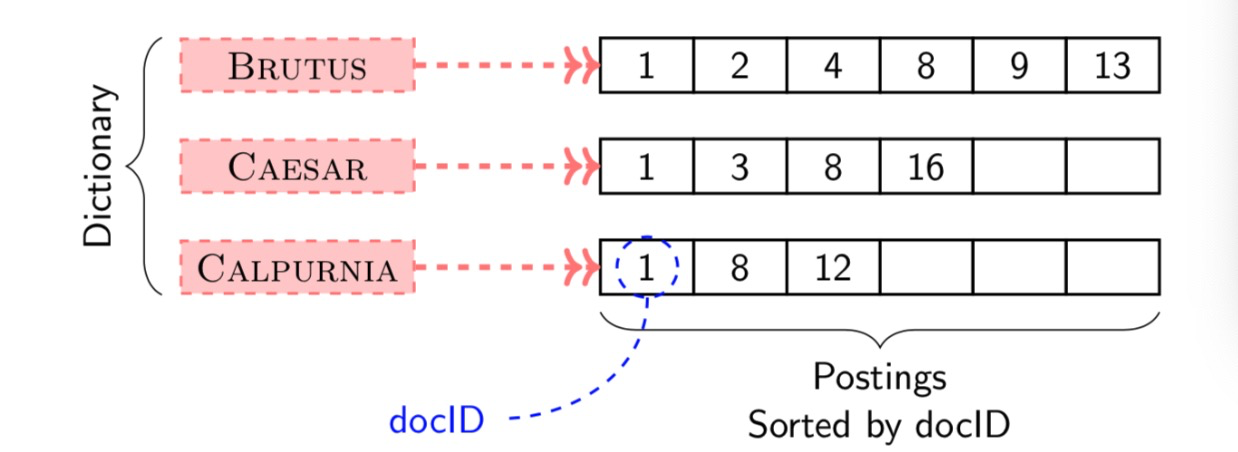
- For each term t, we must store a list of all documents that contain t 对于每个词t,我们都要储存一个列表,这个列表包含所有的包含词t的文件。
- — Identify each doc by a docID, a document serial number 每个文件以文件编号识别。
- We need variable-size postings lists
— On disk, a continuous run of postings is normal and best
— In memory, can use linked lists or variable length arrays 链表或可变长度的array
Initial Stages of Text Processing
• Tokenization
– Cut character sequence into word tokens
– Dealwith“John’s”,”can’t”->”can””not”?
• Normalization 标准化 把query和文本统一成某种格式
– Map text and query term to same form
– YouwantU.S.A.andUSAtomatch
• Stemming
– Wemaywishdifferentformsofaroottomatch
– E.g.authorize,authorization;run,running
• Stop words
– We may omit very common words(ornot) 省略一些常用的虚词
– E.g.the,a,to,of
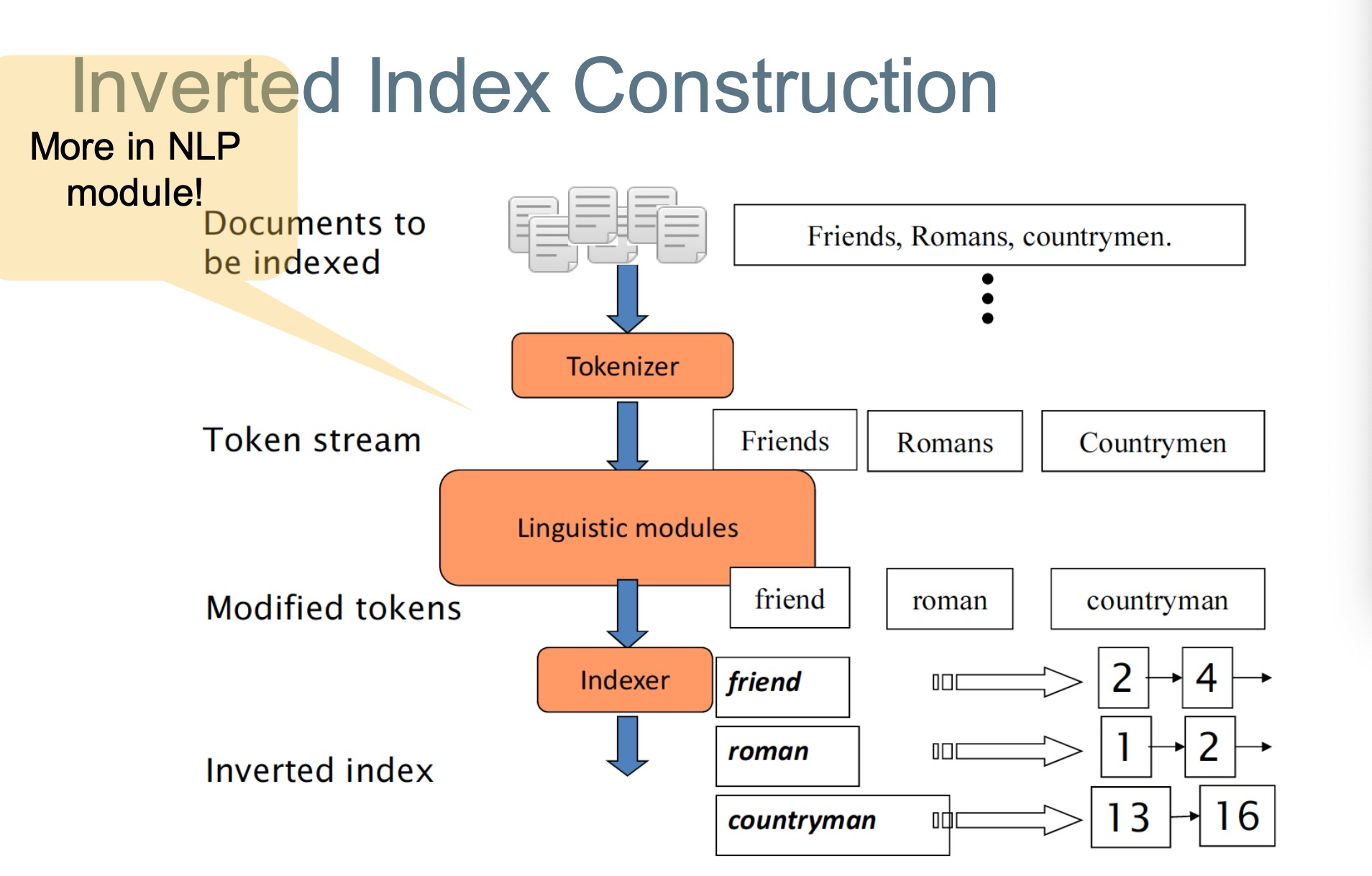
Indexer Step:
- token sequence 编译步骤
- Scan documents for indexable terms 扫描文档中可以
- Keep list of (token, docID) pairs.
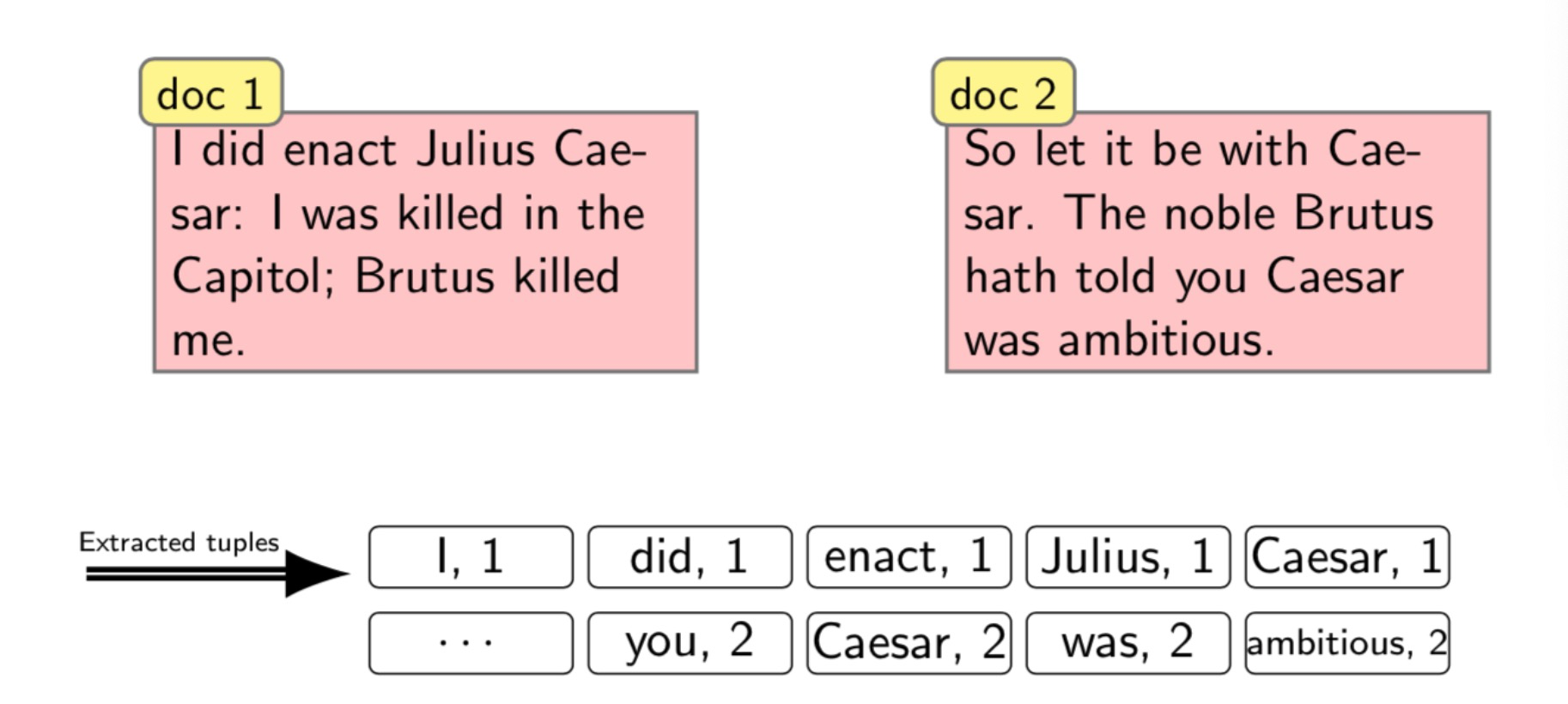
- Sort tuples by terms (and then docID)
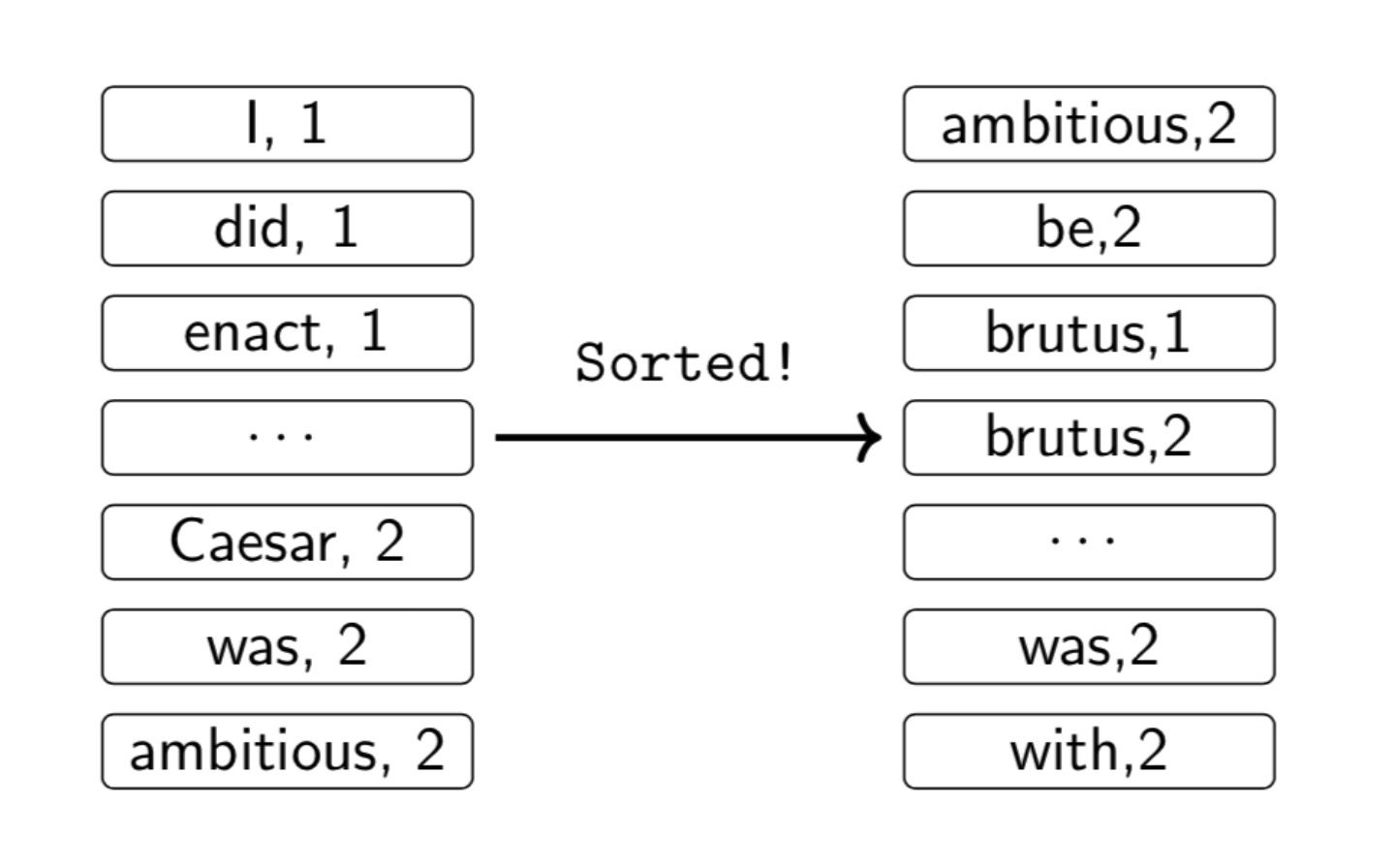
- THREE
- Multiple term entries in a single document are merged
- Split into Dictionary and Postings
- Doc. frequency information is added

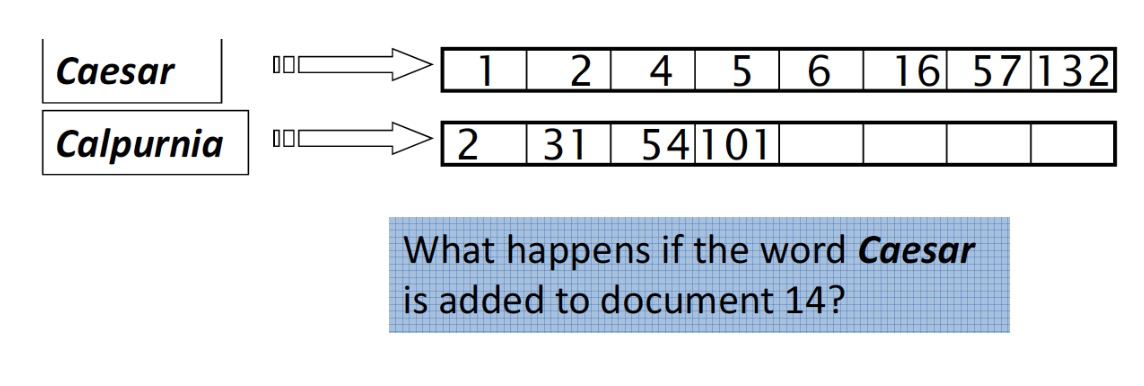
Boolean Retrieval with inverted index
- Easy to retrieve all documents containing term t
- How to find documents containing BRUTUS AND CEASAR using postings?
→ Linear time intersection algorithm for sorted lists
(p1, p2 为两词的posting, 该算法为找出同时出现两词的文章)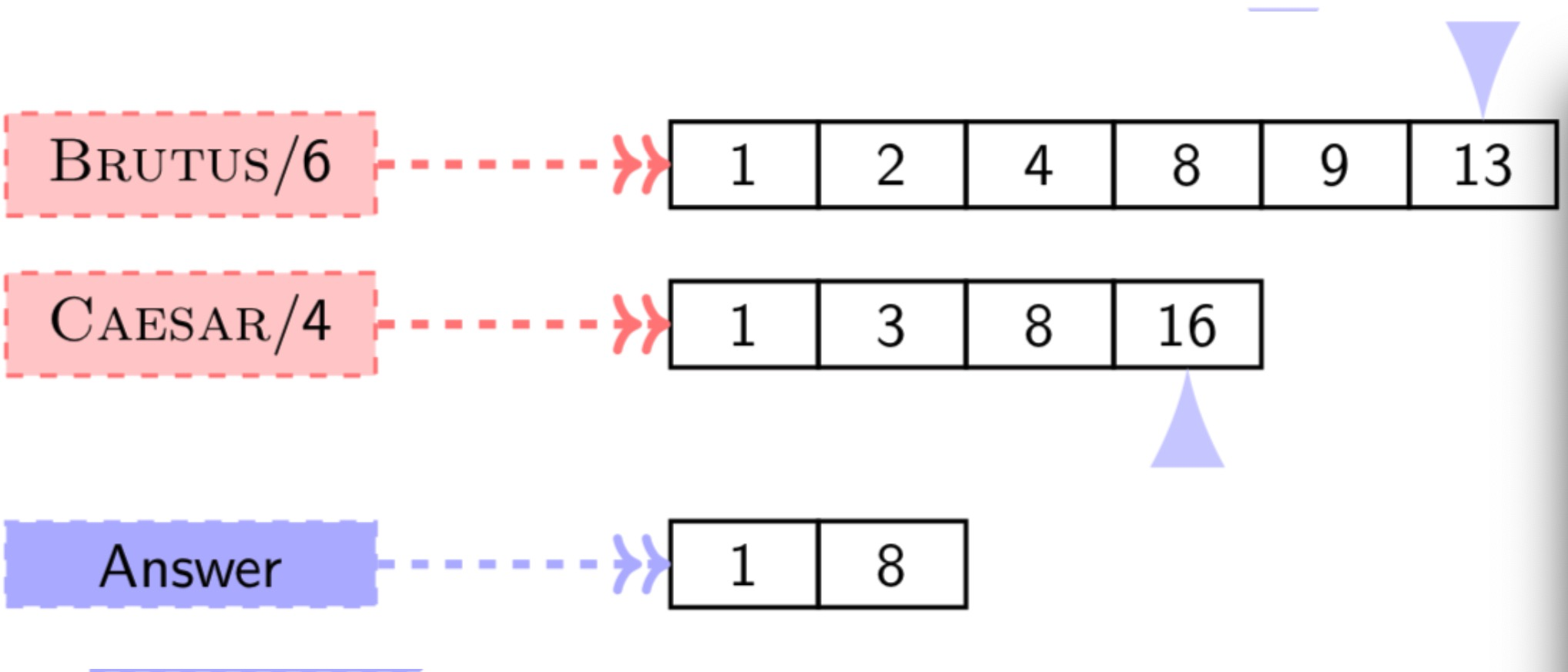
Boolean Retrieval 布尔检索
• Can answer any query which is a Boolean expression: AND, OR, NOT
• Precise: each document matches, or not
• Extended Boolean allows more complex queries
• Primary commercial search for 30+ years, and is still used
A step back
– Tokenization
– Stopwords
– Normalization
– Stemming and Lemmatization
Tokenization
• Task of chopping a document into tokens
• Chopping by whitespace and throwing punctuation are not enough. 不只是删除标点符号和空格。
• Examples:
– NewYork, San Francisco
– Phone numbers ((800)2342333)and dates (Mar11,1983)
– LOWERCASE and LOWERCASE
– Hyphenation
• Co-education,Hewlett-Packard,doc-ument(lineend)
• Regex tokenizer: simple and efficient
• Whatever method you use, always do the same tokenization of document and query text 不管你用什么方法,解析查询语句和原文档的tokenization要一致
Stopword Removal & Normalization
• Stopword removal
– Stop words usually refer to the most common words in a language.
– E.g. the, a, an, and, or, will, would, could
– Reduce the number of postings that a system has to store
– These words are not very useful in keyword search.
• Normalization
– Keep equivalence class of terms: U.S.A = USA = united states
– Synonym list: car = automobile
– Capitalization: ferrari→Ferrari
– Case-folding: Automobile → automobile , CAT != cat
Stemming 词干 and Lemmatization 引理
- {run, running, ran}→run
- Stemming
– Stemming turns tokens into stems, which are the same regardless of inflection.
– Stems need not bereal words 词干不需要多余的词
- Lemmatization
Lemmatization turns words into lemmas, which are dictionary entries.
The word “better” has “good” as its lemma. (depending on the dictionary used) “更好”这个词以“好”为引理。(取决于使用的词典)

若有收获,就点个赞吧
0 人点赞
