Data pre-processing
● It is important to ensure the databases to be linked have similar structure and content 在链接数据库之前,保证其有相似的结构和内容很重要
● Real world data are often dirty 真实世界的数据经常是脏的
– Typographical and other errors 印刷和其他错误
– Different coding schemes 不同的编码格式
– Missing values 缺失值
– Data changing over time 随时间变化的数据
● Names and addresses are especially prone to data entry errors 姓名和地址尤其容易出现数据输入错误
– Scanned, hand-written, recorded over telephone, and manually typed 扫描的手写体
– Same person often provides her/his details differently 同一个人通过不同方式提供的他的细节
– Different correct spelling variations for proper names (like ‘Gail’ and ‘Gayle’) 专有名称的不同正确拼写变体
Data pre-processing steps 数据预处理步骤
● Clean input: 输入清洗
– Remove unwanted characters and words (“missing”, “n/a”, etc.) 移除不想要的单词或字符
– Expand abbreviations and correct misspellings (“Wolllongonng” → “Wollongong”, “St” → “Street”, etc.) 扩展缩写并纠正拼写错误
● Segment names and addresses into well defined output fields (such as title, first name, middle name, last name, etc.) 将姓名和地址分割成定义明确的输出字段(如标题、名字、中间名、姓氏等)。)
● Verify correctness if possible 确认正确性
– Do gender and first name match? 性别和名字是否匹配?
– Does an address (or parts of it) exists in the real-world? (such as “Sydney NSW 7000”)地址是否真实存在?
Blocking
Why blocking?
● The number of record pair comparisons equals the product of the sizes of the two data sets 记录配对的比较次数为两个数据集的数据量相乘
● For example: Matching two data sets containing 1 and 5 million records will result in 1,000,000 × 5,000,000 = 5 x 1012 record pair comparisons (one trillion = one million million)
● Question: How many record pair comparisons are there for the deduplication of a single database with 1 million records?
● Performance bottleneck in a record linkage system is usually the (expensive) detailed comparison of attribute (field) values between record pairs (such as approximate string comparison functions) 记录链接系统中的性能瓶颈通常是记录对之间属性(字段)值的(昂贵的)详细比较(例如近似字符串比较函数)
● Blocking / indexing / searching / filtering techniques are used to reduce the large amount of record pair comparisons 为了减少记录对互相比较的次数
● Aim of blocking: Cheaply remove candidate record pairs which are obviously not matches (i.e. are non-matches) Blocking的目的:便宜直接移除那些明显不匹配的记录对。
**
Traditional blocking
● Traditional blocking works by only comparing record pairs that have the same value for a blocking key variable 传统的blocking只通过比较阻blocking变量具有相同值的记录对
● One or more attributes in the databases to be linked are selected as blocking keys (and attribute values are concatenated) 选择一个或者多个数据库中的属性连接作为blocking key
● All records that have the same blocking key value (BKV) will be inserted into the same block 所有有相同BLK的记录都会被插入相同的block
● Candidate record pairs will be formed from blocks where their BKV occurs in both databases 候选记录对将由BKV同时出现在两个数据库中的block形成
● Problems with traditional blocking: 传统blocking的问题
– An erroneous value in a blocking key variable results in a record being inserted into the wrong block blocking键变量中的错误值会导致记录被插入到错误的块中
– Attributes that are know to change will mean true matching record pairs are potentially missed (for example, surname or postcode) 会更改的属性可能导致真正匹配的记录对丢失(例如,姓氏或邮政编码)
– Missing values mean BKVs cannot be generated 缺少值意味着无法生成BKVs
– Frequency distributions of BKVs influence number of record pairs generated BKVs的频率分布影响生成的记录对的数量
● Question: Assume the number of surname values “Smith” in two databases is 10,000 and 25,000; while the number of “Dijkstra” is 4 and 5. How many record pairs are generated from each?
● Attributes selected as blocking keys should: 选择属性作为blocking key应该:
– Not change over time (i.e. be constant) 稳定、不会随时间变化
– Be accurate (no errors or variations in them) 准确(没有错误或变化)
– Be complete (no missing values) 完整,没有缺失值
– Have a frequency distribution close to uniform 具有接近均匀的频率分布
– Have a reasonable number of unique different values 拥有合理数量的独特不同值
● Questions: Which one is better as a blocking key? Gender or social security number? What are examples of attributes suitable as blocking keys?
Improving traditional blocking 改进传统blocking
● Problems with traditional blocking: 传统blocking的问题
– An erroneous value in a blocking key variable results in a record being inserted into the wrong block blocking中的错误值会导致记录被插入错误的block
– Attributes that are know to change will mean true matching record pairs are potentially missed (for example, surname or postcode) 已知会改变的属性将意味着真正匹配的记录对可能会丢失(例如,姓氏或邮政编码)
– Missing values mean BKV cannot be generated 丢失值意味着BKV不能被生成
– Frequency distribution of a BKV influences the number of record pairs generated BKV的分布频率会影响记录对的生成
● Some of these problems can be overcome by careful selection of the attributes to be used as blocking keys 部分问题可以通过对属性的选择来解决。
● Others can be addressed by using phonetic encoding 其他问题可以通过语音编码解决
Phonetic encoding 语音编码
● Techniques that convert strings (assumed to be names) into some form of code according to how a string is pronounced 根据字符串的发音,按规则把字符串编码
– Generally assuming English language 假设是英语
– Variations of techniques for other languages exist 其他语言也有不同的技术
● The earliest and still commonly used technique is Soundex 最早也是最常用的技术是Soundex
– Patented in 1918 and 1922, used for analysis of older censuses 在1918年和1922年获得专利,用于分析旧的人口普查
● Various other techniques improve upon drawbacks of Soundex 各种其他技术改进了Soundex的缺点
– NYSIIS (New York State Identification and Intelligence System), 1970
– Metaphone and Double-Metaphone, 1990 and 2000
– Phonex (direct improvement of Soundex), 1993
– Phonix, Fuzzy Soundex, Oxford name Compression Algorithm (ONCA), etc.
Phonetic encoding for blocking Blocking 的语音编码
● Name variations are common in databases used for linkage (because generally linkage requires names and addresses) 名称变化在用于链接的数据库中很常见(因为通常链接需要名称和地址)
● Many name variations are valid (not errors) 许多名称变体都是有效的(不是错误)
● For example:
– “gail” versus “gayle” versus “gale” versus “gaile”
– “albert” versus “alberta” or “alva” versus “alvie” (all these are valid suburb names in Australia – check Australia Post!)
● Names are often recorded how people think they should be spelled (based on their experiences) 名字经常被记录人们认为应该如何拼写(基于他们的经验)
● Phonetic encoding can help bring together spelling variations of the same name for improved blocking 语音编码有助于将同一姓名的不同拼写组合在一起,从而提高阻断效果
Soundex algorithm 语音算法
● A simple algorithm to convert (name) strings into codes made of one letter and three digits 将字符串转换为由一个字母和三个数字组成的代码的简单算法
● Steps:
1) Keep first letter of a string 保持第一个字母为字符
2) Remove all following occurrences of: a, e, i, o, u, y, h, w 移除以下字母,a, e, i, o, u, y, h, w
3) Replace all consonants from position 2 onwards with digits using these rules: 使用以下规则用数字替换从第二个位置开始的所有辅音:
b, f, p, v → 1 c, g, j, k, q, s, x, z → 2
d, t → 3 l → 4
m, n → 5 r → 6
4) Only keep unique adjacent digits 仅保留唯一的相邻数字
5) If length of a code is less than 4 add zeros, if longer truncate at length 4 如果代码长度小于4,则添加零,如果更长,则在长度4处截断
● “gail” → g400 “gayle” → g400
● “christine” →c623 “christina → c623
● “kristina” → k623 “kirstin” → k623
● “peter” → p360 “christen” → c623
● Online converter: http://resources.rootsweb.ancestry.com/cgi-bin/soundexconverter
Alternative blocking: Sorted neighbourhood 替代blocking:领域排序
● Various alternatives to standard blocking have been developed, a popular approach is the sorted neighbourhood method 已经开发了各种标准blocking的替代方法,一种流行的方法是排序邻域法
● Basic idea: 基本思路
– Merge databases and sort them according to a sorting key 通过分类键来排序,并合并数据库。
– Slide a window over the sorted databases 在已经排序的数据空上滑动窗口
– Compare records in the window 比较窗口中的记录
– Use several passes with different sorting criteria 使用具有不同排序标准的多个通道
– Window size can be fixed or adaptive (based on similarities between records) 窗口大小可以是固定的或自适应的(基于记录之间的相似性)
– For a window of fixed size w, the number of comparisons becomes w (|D1 | + |D2 |), where |D| is the number of records in a database 对于固定大小为w的窗口,比较次数变为w (D1 |+| D2 |),其中|D|是数据库中的记录数
Sorted neighbourhood example
● For example, a database is sorted using first and last name: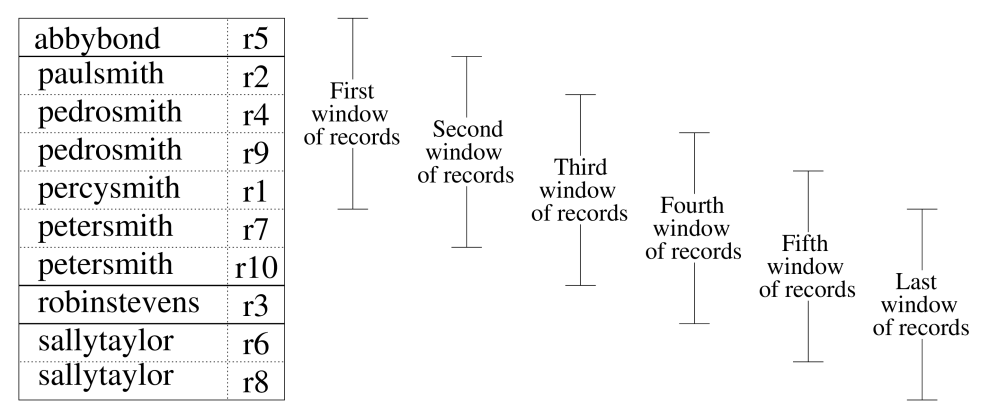
Alternative blocking: Canopy clustering 聚类
● Based on a computationally ‘cheap’ similarity measure such as Jaccard (set intersection based on q-grams)
● Records will be inserted into several clusters / blocks 记录将被插入到几个簇/块中
● Algorithm steps:
1) Randomly select a record in database D as cluster centroid c i , i = 1, 2, . . . 在数据库D中随机选择一条记录作为聚类质心c i,i = 1,2,.。。
2) Insert all records that have a similarity of at least s loose with c i into cluster Ci )将所有与c i相似度至少为s的记录插入到分类Ci中
3) Remove all records r j C ∈ i (including c i ) from D that have a similarity of at least s tight with c i , with s tight ≥ s loose )将所有与c i相似度至少为s的记录插入到分类Ci中
4) If database D not empty go back to step 1)如果数据库D不为空,返回步骤1)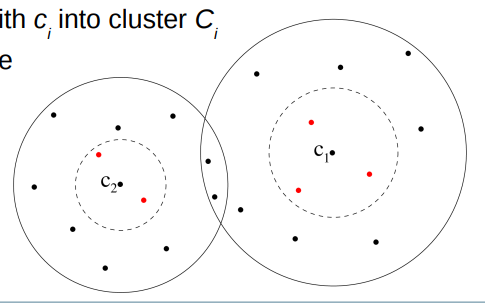
Other blocking techniques
● Q-gram based blocking (e.g. 2-grams / bigrams)
– Convert attribute values into q-gram lists, then generate sub-lists:
“peter” →[‘pe’,‘et’,‘te’,‘er’], [‘pe’,‘et’,‘te’], [‘pe’,‘et’,‘er’], …
“pete” → [‘pe’,‘et’,‘te’], [‘pe’,‘et’], [‘pe’,‘te’], [‘et’,‘te’], …
– Records with the same sub-list value are inserted into the same block
– Each record will be inserted into several blocks
– Works well for ‘dirty’ data but has high computational costs
● Mapping-based blocking 图映射blocking
– Map strings into a multi-dimensional space such that distances between strings are preserved
● Many more advanced blocking techniques developed in recent years, still an active research area

若有收获,就点个赞吧
0 人点赞
