IF-THEN rules can also be derived directly from the training data (i.e., without having to generate a decision tree first) using a sequential covering algorithm. Sometimes this is called induction or _abduction, _by reference to the language of logical inference, where rule languages have been extensively studied over a very long period.
Sequential covering algorithm
- Extracts rules directly from training data
- Typical sequential covering algorithms: FOIL, AQ, CN2, RIPPER
- Rules are learned sequentially, each for a given class
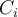 will cover many tuples of
will cover many tuples of 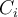 but none (or few) of the tuples of other classes
but none (or few) of the tuples of other classes - Steps:
- Rules are learned one at a time
- Each time a rule is learned, the tuples covered by the rules are removed from the training set
- The process repeats on the remaining tuples until a termination condition
- e.g., when no more training examples or when the quality of a rule returned is below a user-specified threshold
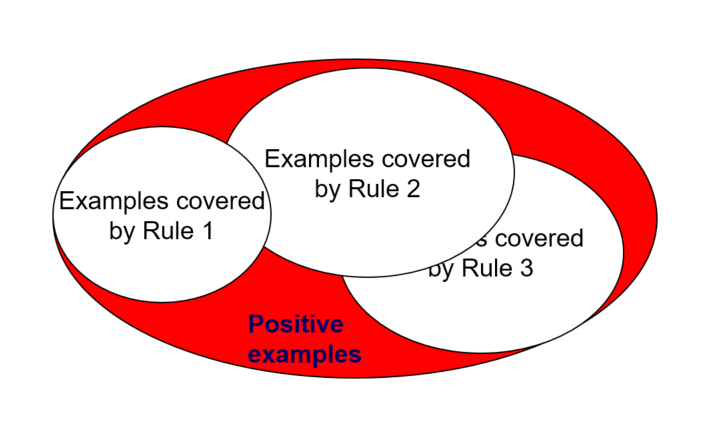
How each rule is learned
- Rules are grown in a general-to-specific manner.
- Choose a rule consequent (usually the positive class)
- Initialise an empty antecedent
- Repeat:
- Add an attribute test to the rule antecedent
- Until satisfied with this rule.
Example
Compared to rules derived from a Decision Tree
- Rules may be presented in a more expressive language, such as a relational language (e.g. can use relations like “adjacent” or “greater than” that relate attributes of covered tuples)
- Rules may be more compact and readable (do not branch from a common stem and tuples covered by an earlier rule are removed from training set)

若有收获,就点个赞吧
0 人点赞
