Recap 概述
• RNNs to process sequential data. RNN处理序列数据的
• Encoder-Decoder models for sequence-to-sequence mappings. 序列2序列映射的编码解码模型
• Attention helps the decoder. 注意力机制帮助解码器
Attention
It was found that the recurrent part of the model was not necessary if you use a more sophisticated type of attention and some other tricks.
人们发现,如果你使用更复杂的注意力类型和一些其他技巧,模型的循环部分是不必要的。
Transformer Models Transformer模型
• Transformers do not do any recurrent processing of inputs. 变压器不对输入进行任何重复处理
• Instead, they use self-attention to create representations of the input sequence. 相反,他们利用自我关注来创建输入序列的表示。
• In self-attention, every input vector is used as a query over all input vectors. 在自我关注中,每个输入向量都被用作对所有输入向量的查询。
– In contrast standard attention uses the previous decoder output as query over all encoder outputs. 相比之下,标准注意力使用先前的解码器输出作为对所有编码器输出的查询。
• Transformers use Query Key Value attention 变压器模型使用查询键值注意力
Self-Attention 自我关注
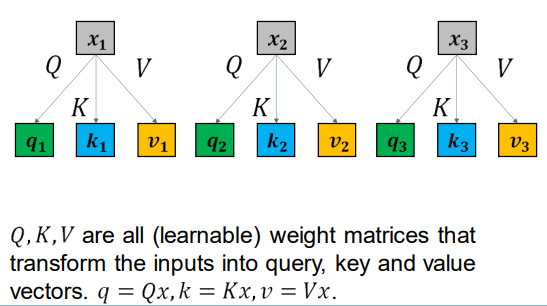
Q,K,V是可学习的权重矩阵,将输入转换为q查询,k键和v值向量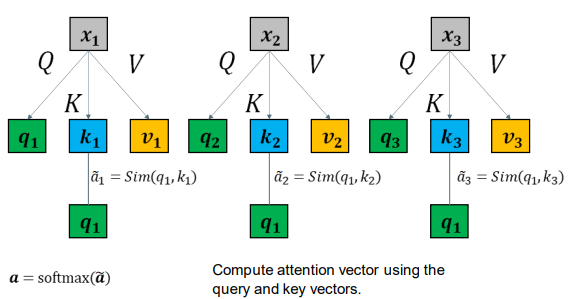
使用查询q和键k的向量计算注意力向量。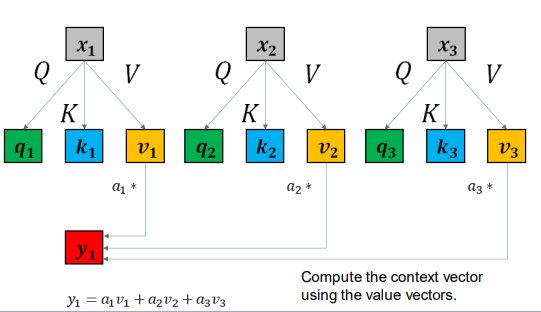
使用值向量计算上下文向量。
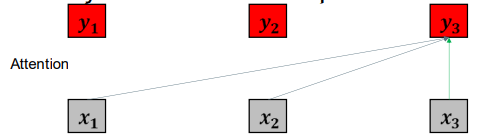
• We have calculated 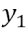 , the new vector representation of
, the new vector representation of 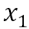 . 我们先计算y1, x1新的向量表示。
. 我们先计算y1, x1新的向量表示。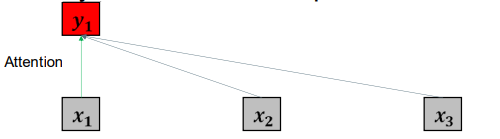
• We need to repeat this computation to calculate a 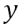 for every input
for every input 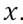 . In practice they can all be done in parallel. 然后重复这个计算步骤,为每一个输入X都计算y。实际上,他们可以并行完成。
. In practice they can all be done in parallel. 然后重复这个计算步骤,为每一个输入X都计算y。实际上,他们可以并行完成。

Multi-head Attention 多注意机制
Have multiple attention heads, so the model can focus on more input regions. 为了让模型可以注意到更多的输入区域。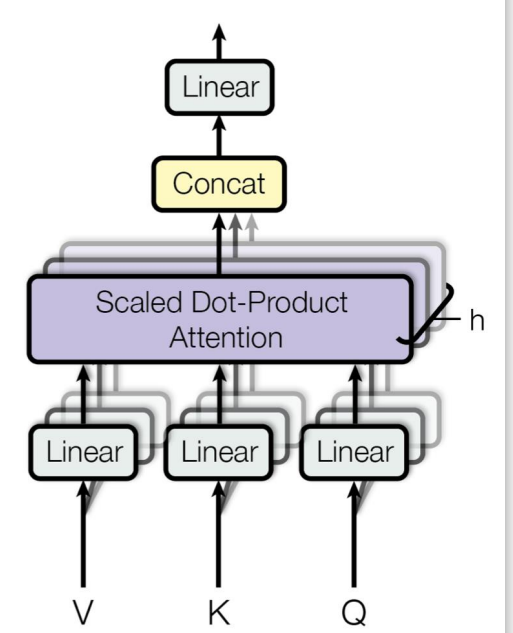
 W0 是一个新的线形层,去结合所有的注意力关注点
W0 是一个新的线形层,去结合所有的注意力关注点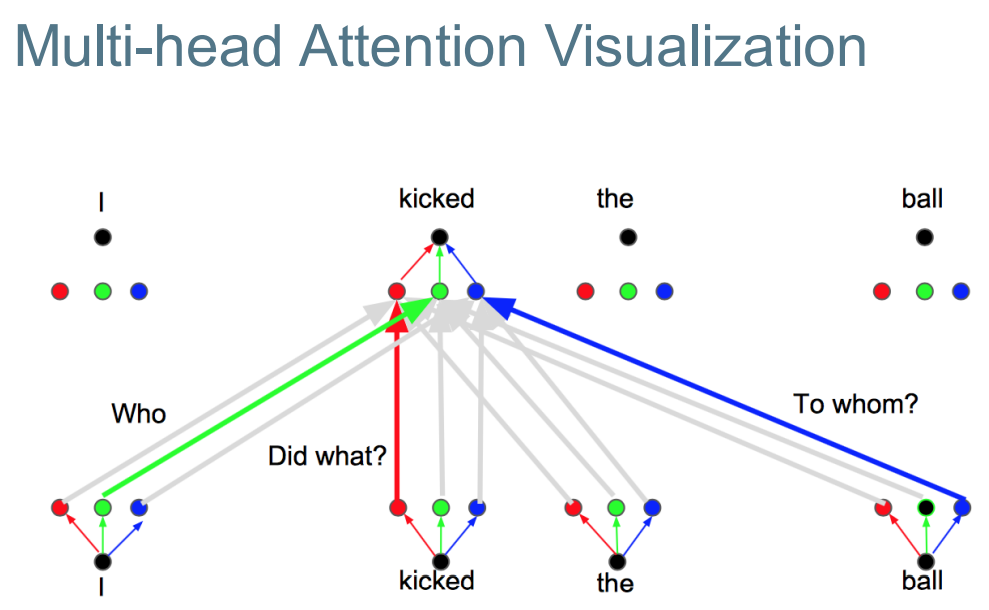
Positional Encodings 位置编码
• The self attention mechanism does not take into account the order of words! 自我注意力机制不将单词的词序纳入考虑
• We need to encode positional information directly into the input vectors. 我们需要将单词的位置信息直接编码进输入向量。
The t’th input element is created by adding the embedding of the t’th word and a vector that represents the t’th position. 第t个个输入元素为,第t个单词的词嵌入向量+第t个位置的表示向量。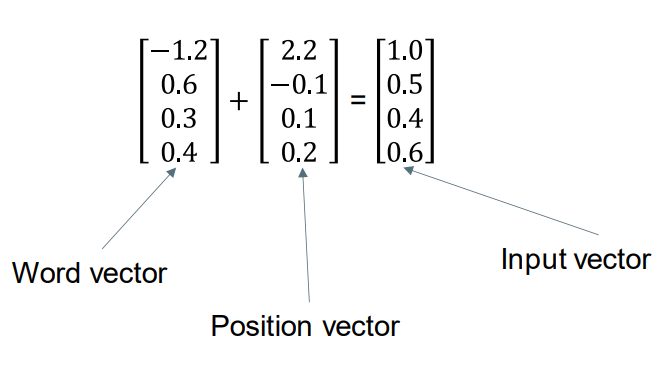
Position encoding vectors are constructed from sine and cosine functions 位置编码向量 由正弦和余弦函数构成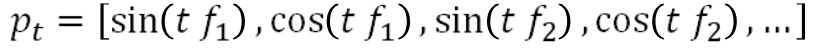
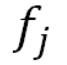 are frequencies of the different sine waves. fj是不同正弦波的频率。
are frequencies of the different sine waves. fj是不同正弦波的频率。
• You can think of this vector as a ‘clock’. 你可以把这个向量想象成一个“时钟”。
• Different positions will have different position vectors . 不同的位置会有不同的位置向量。
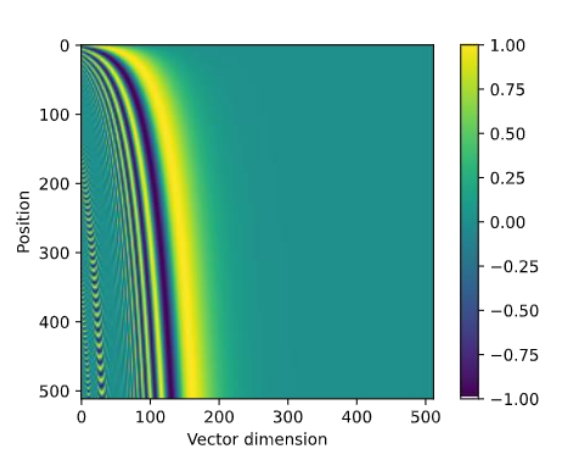
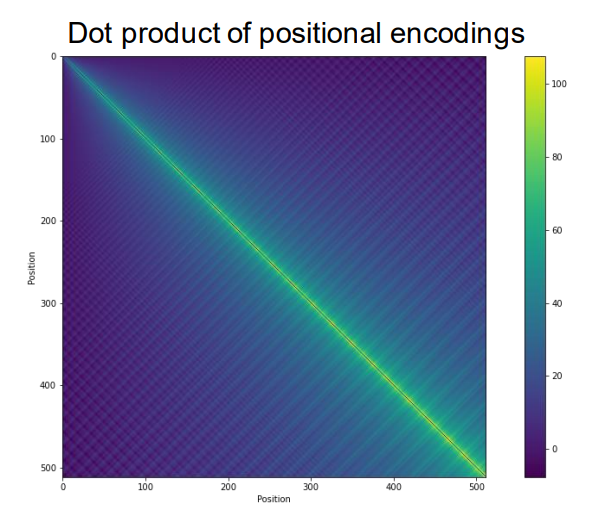
Note: for this visualization, the dot product of a positional encoding with itself is set to 0. 注意:对于该可视化,位置编码与其自身的点积被设置为0
Positional encodings that are closest to each other have the largest dot product. 彼此最接近的位置编码具有最大的点积。
Transformers
Transformers are created by stacking self-attention layers and feed-forward layers in an alternating pattern. 变压器是通过交替堆叠自关注层和前馈层而产生的。
• Self-attention extracts features from all the inputs. 自我关注从所有输入中提取特征。
• Feed-forward layers perform a non-linear transform independently on each input vector. ReLU is often used here. 前馈层对每个输入向量独立执行非线性变换。这里经常用ReLU。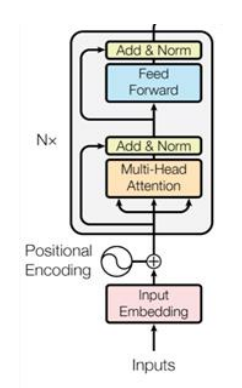
The input is a sequence the output is a sequence of the same length (just like with the RNN models) 输入是一个序列,输出是相同长度的序列(就像RNN模型一样)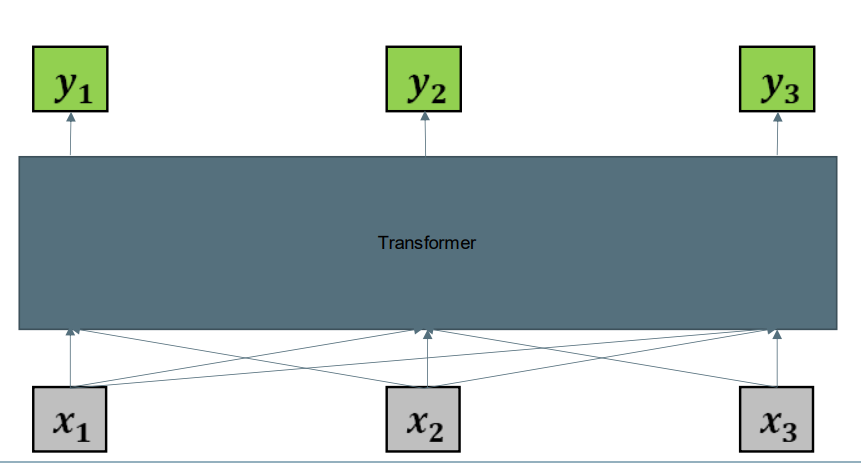
Usually, transformers also include residual connections and layer normalizations 通常,变压器还包括残余连接和层标准化
– Residual connections skip a layer and then add the input to the output of that layer. 剩余连接跳过一层,然后将输入添加到该层的输出。
– Layer normalization means that each layer output is normalised (subtract mean, divide by standard deviation). 层标准化意味着每个层输出都被标准化(减去平均值,除以标准偏差)。
These tricks help with training very deep networks. 这些技巧有助于训练非常深的网络。
Residual Layer Connection 残差层链接
The residual layer copies the input and adds it to the output of one or more stacked layers. 残差层复制输入,并将其添加到一个或多个堆叠层的输出中。
This means the Neural Network is learning: 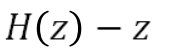
We can interpret this as: it is fitting a residual. 我们可以把这解释为:它是拟合残差。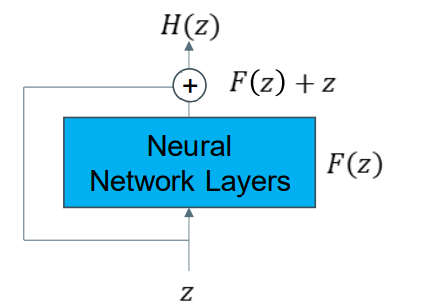
Layer Normalization 图层规范化
During training, the weights change. 在训练的过程中,权重会发生变化
Changes in the weights cause layer outputs to change. 权重变化会导致层输出的变化。
If the output changes too much, then the next layer may not have been trained on the new input space. 如果输出变化太多,下一层可能无法在新的空间上进行训练
Called the “covariate shift” problem. 叫做“协变量转移”问题。
Layer normalization is one solution to “covariate shift”. 层规范化是其中的一种解决办法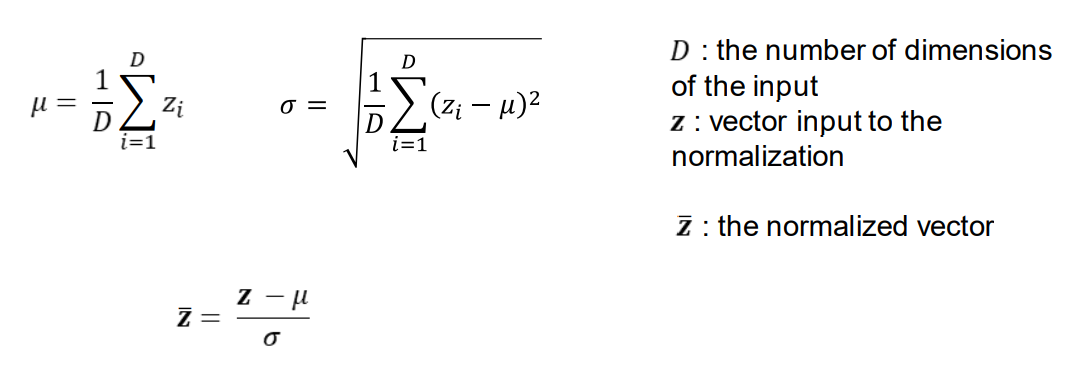 \
\
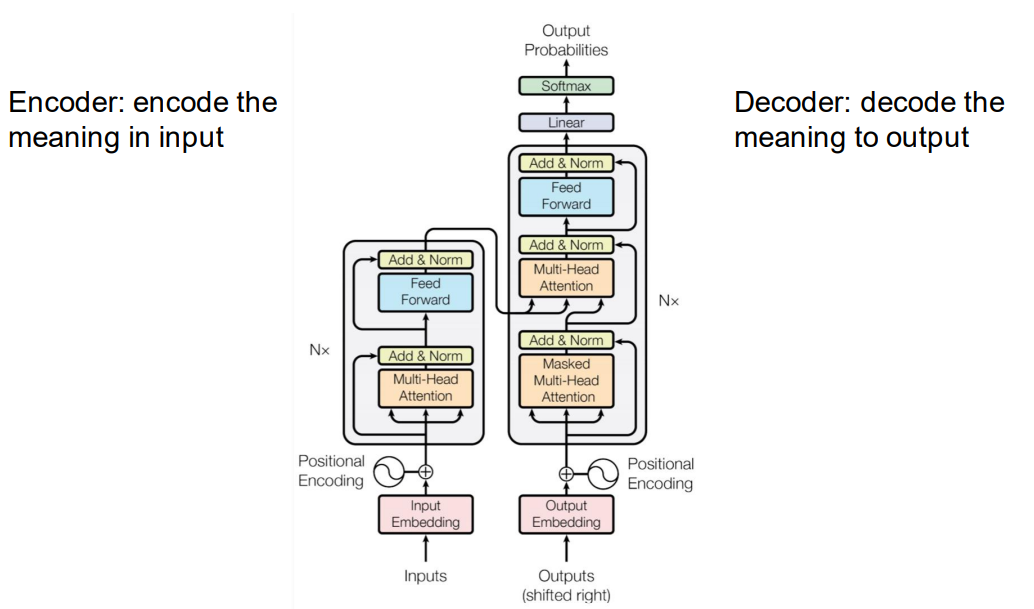
Transformer Encoder-Decoder 迁移编码和解码
Limitations of transformers 变压器的局限性
• Expensive in terms of both computation and memory. 计算和内存都很昂贵。
• Fixed context window 固定上下文窗口
• May require more training data compared to recurrent models 与循环模型相比,可能需要更多的训练数据
– The transformer must learn sequential structure, whereas recurrent models are natively sequential. 转换器必须学习顺序结构,而递归模型本身是顺序的。
Usages of self-attention 自我关注的使用
Self-attention is a flexible way of creating vector representations for many types of structured data. 自我关注是为多种类型的结构化数据创建向量表示的一种灵活方式。
– You need a way of encoding position 你需要找到一种编码位置的方法
State-of-the-art models for text processing are now almost always transformer based. 最先进的文本处理模型现在几乎都是基于transformer的。
Transformers are also useful for graph and tree structured data. 转换器对于图形和树结构数据也很有用。
Memory Augmented Neural Network 记忆增强神经网络
Motivation:
Introduce external knowledge 引入额外知识
Memorize more states of sequence 记忆更多的序列
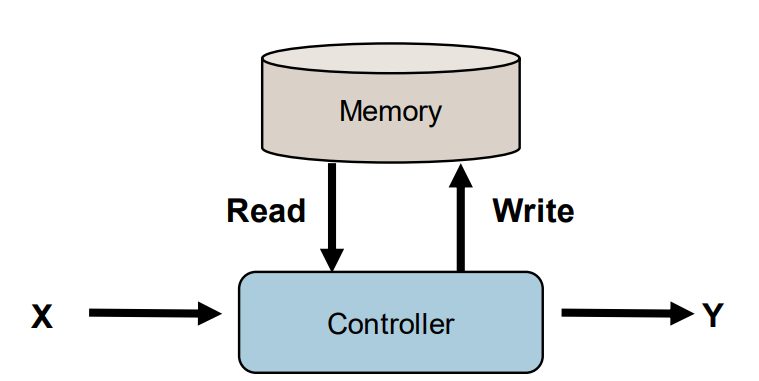
External Memory
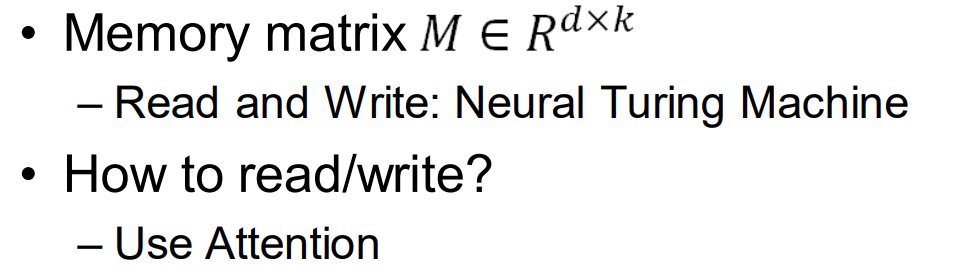
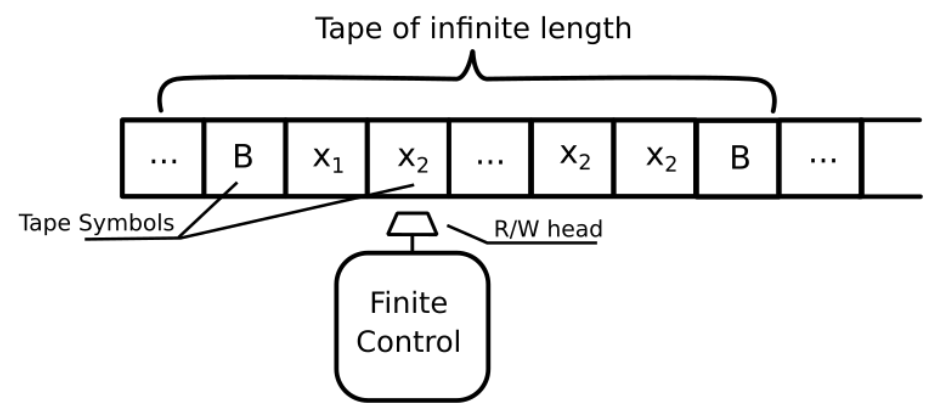
Turing Machine 图灵机
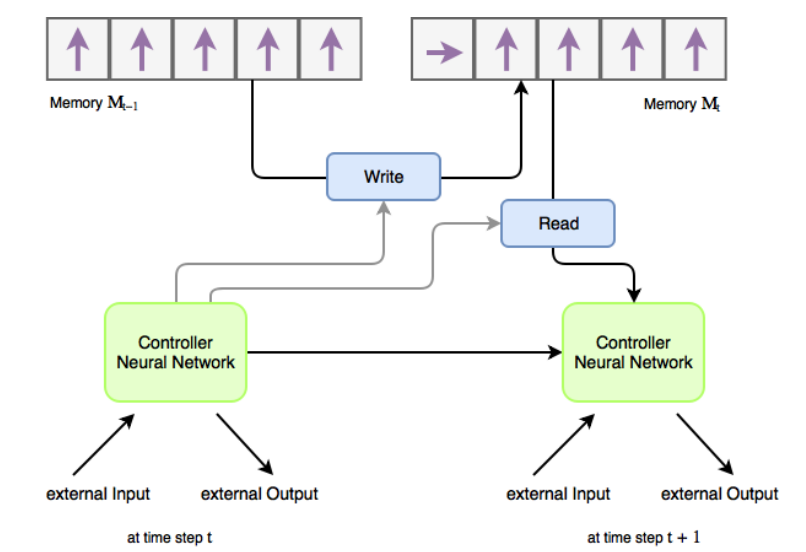
Neural Turing Machine 神经网络图灵机

若有收获,就点个赞吧
0 人点赞
