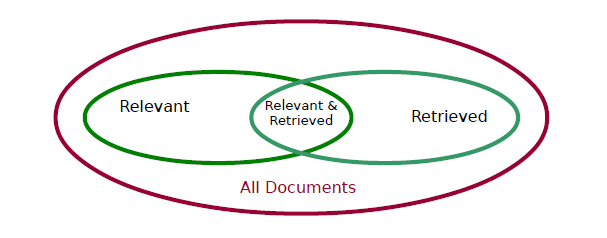
The documents that are relevant are the actual positives in the training set (P). The documents that are retrieved are those labelled positive by the information retrieval system (TP U FP). 相关文件为真是阳性,检索到的文件为标记阳性。 A good system will have a large intersection of the Relevant and Retrieved sets. Ideally all Relevant documents (and none other) are Retrieved. That is, ideally, TP = P and FP = {}. 一个好的系统将有一个相关集和检索集的大交集。理想情况下,检索所有相关文档(而不是其他文档)。即理想情况下TP = P,FP = {}。
Precision 精确度: the proportion of retrieved documents that are in fact relevant to the query (i.e., the “correct” responses)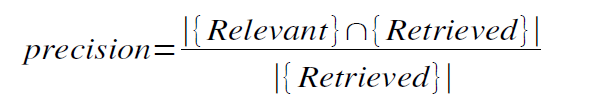
Recall: the proportion of documents that are relevant to the query and were, in fact, retrieved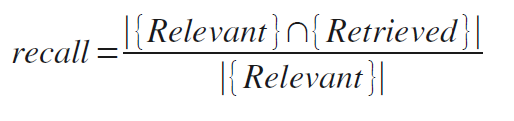
There is typically a tradeoff between precision and recall, as you can get perfect recall but very poor precision by retrieving everything. You can get perfect precision by retrieving just one relevant document, but the recall will be very poor if there were many more relevant documents that should have been retrieved.精确度和召回率之间通常有一个折衷,因为你可以通过检索所有东西来获得完美的召回率,但精确度非常低。您可以通过只检索一个相关文档来获得完美的精度,但是如果有更多应该检索的相关文档,召回率将非常低。
They can be combined into one measure, called the F-score, (or commonly F-measure, or F1) which is the harmonic mean of the two that disfavours one variable’s high performance at the expense of the other.它们可以被组合成一个度量,称为F-score(或通常的F-measure,或F1),这是两者的调和平均值,它以牺牲另一个变量的高性能为代价来损害一个变量的高性能。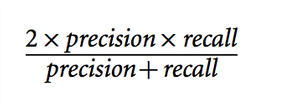
Action: Think where you have seen this before (see various evaluation measures in a confusion matrix). Although orignally developed for information retrieval these have become used for classification, too, as they emphasise the behaviour of positives in an asymmetric space where the negatives dominate.

若有收获,就点个赞吧
0 人点赞
