Attribute selection methods are also called splitting rules. 属性选择方法也称为拆分规则。
- Techniques to choose a splitting criterion comprised of a splitting attribute and a split point or splitting subset 选择由分割属性和分割点或分割子集组成的分割标准的技术
- Aim to have partitions at each branch as pure as possible — i.e. all examples at each sub- node belong in the same class. 目标是每个分支的分区尽可能的纯——即每个子节点的所有例子都属于同一个类。
Example
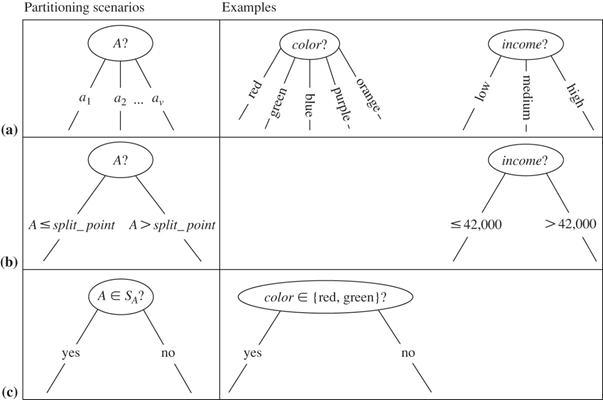
This figure shows three possibilities for partitioning tuples based on the splitting criterion, each with examples. Let A be the splitting attribute. (a) If A is nominal-valued, then one branch is grown for each known value of A. (b) If A is continuous-valued or ordinal, then two branches are grown, corresponding to A  split_point and A > split_point. (c) If A is nominal and a binary tree must be produced, then the test is of the form A
split_point and A > split_point. (c) If A is nominal and a binary tree must be produced, then the test is of the form A  S, where S is the splitting subset for A.
S, where S is the splitting subset for A.
Heuristics, (or attribute selection measures) are used to choose the best splitting criterion.
- Information Gain, Gain ratio and Gini index are most popular.
- Information gain:
- biased towards multivalued attributes 偏向于多值属性
- Gain ratio:
- tends to prefer unbalanced splits in which one partition is much smaller than the others 倾向于不平衡分割,其中一个分区比其他分区小的多
- Gini index:
- biased towards multivalued attributes 偏向于多值属性
- has difficulty when number of classes is large 类别数量多时会有困难
- tends to favour tests that result in equal-sized partitions and purity in both partitions 倾向于进行测试,使两个分区的大小和纯度相等

若有收获,就点个赞吧
0 人点赞
