Synopses
- It is impractical to scan through an entire data stream more than once. 多次扫描整个数据流是不切实际的。
- Sometimes, we cannot even look at every element of a stream. 有时,我们甚至不能看到流的每个元素。
- => Need to relax the requirement that our answers are exact 需要放宽要求
- => Willing to settle for approximate rather that exact answers 愿意接受近似而非精确的答案
- Synopses allows for this by providing summaries of the data based on synopsis data structures 概要通过提供基于概要数据结构的数据概要来实现这一点
- The summaries can be used to return approx imate answers to queries. 总结返回查询的近似答案
Examples of some common synopsis techniques are
- Random sampling 随机采样
- Sliding windows 滑动窗口
- Histograms 直方图
- Multi-resolution Methods 多分辨率方法
- Sketches 草图
Reservoir Sampling 蓄水池抽样
- Random sampling refers to the process of probabilistic choice of a data item to be processed (and therefore influential). 随机抽样是指对要处理的数据项进行概率选择的过程(因此具有影响力)。
- Simple sampling cannot be directly applied to a data stream in an unbiased way since we do not know the total dataset size. 简单采样不能以无偏的方式直接应用于数据流,因为我们不知道数据集的总大小。
- Reservoir sampling keeps a reservoir _of _
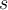 samples seen so far. 储层保存了迄今为止观察到的样品储层。
samples seen so far. 储层保存了迄今为止观察到的样品储层。 - Unbiased random samples of size up to
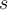 can be extracted from the reservoir for analysis at any time. 可随时从储层中提取大小不超过s的无偏随机样本进行分析。
can be extracted from the reservoir for analysis at any time. 可随时从储层中提取大小不超过s的无偏随机样本进行分析。 - To maintain the reservoir, on arrival of each new observation
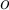 , 为了维护储水库, 每次有新的观测样本o出现时
, 为了维护储水库, 每次有新的观测样本o出现时- Assume we have seen
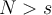 elements so far in the stream (including
elements so far in the stream (including 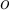 ) 假设我们已经在数据流中观察到了N个数据大于s个与元素。
) 假设我们已经在数据流中观察到了N个数据大于s个与元素。 - With probability
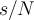 , replace a random old observation in the reservoir by
, replace a random old observation in the reservoir by 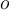 在储层中,用o代替一个旧观测值。
在储层中,用o代替一个旧观测值。
- Assume we have seen
- Then the set of
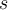 observations in the reservoir is always a random sample of the elements seen so far. 因此,储层中总是储存了s个观测对象由迄今为止所有的元素随机采样生成。
observations in the reservoir is always a random sample of the elements seen so far. 因此,储层中总是储存了s个观测对象由迄今为止所有的元素随机采样生成。
Example Assume our reservoir of size 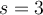 contains objects {1,2,3} and we have seen only those 3 objects in the stream so far. When the 4th object arrives, then with probability 3/4, we replace one of {1,2,3} that is selected with probabilty 1/3. Let’s say this means we replace 2 by 4, so then our updated reservoir is {1,3,4}. Let’s say we now want a random sample of size 2 from our stream to date, so we can select 2 objects randomly from {1,3,4} (say, 1 and 3). In fact, we have selected 2 objects randomly from the stream (so far comprising {1,2,3,4}), each with probability 1/4, even though we do not store all of that stream.
contains objects {1,2,3} and we have seen only those 3 objects in the stream so far. When the 4th object arrives, then with probability 3/4, we replace one of {1,2,3} that is selected with probabilty 1/3. Let’s say this means we replace 2 by 4, so then our updated reservoir is {1,3,4}. Let’s say we now want a random sample of size 2 from our stream to date, so we can select 2 objects randomly from {1,3,4} (say, 1 and 3). In fact, we have selected 2 objects randomly from the stream (so far comprising {1,2,3,4}), each with probability 1/4, even though we do not store all of that stream.
示例假设我们的大小为3的池包含对象{1,2,3},到目前为止,我们只在流中看到了这3个对象。当第四个对象到达时,概率为3/4,我们替换概率为1/3的{1,2,3}中的一个。假设这意味着我们用4替换2,那么我们更新的库是{1,3,4}。假设我们现在希望从我们的数据流中获得一个大小为2的随机样本,因此我们可以从{1,3,4}(比如说,1和3)中随机选择2个对象。事实上,我们已经从流中随机选择了2个对象(到目前为止包括{1,2,3,4}),每个对象的概率为1/4,尽管我们没有存储所有的流。
Sliding Window 滑动窗口
- Instead of random sampling, make a decision on some recent data. 做决定从最近的数据中做决定,而不是随机采样
- A new data arrived at time
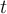 will be expired at time
will be expired at time  . 新数据会持续在t到t+w的时间窗口内。
. 新数据会持续在t到t+w的时间窗口内。 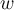 is the window size. w是窗口尺寸大小
is the window size. w是窗口尺寸大小 Useful for stocks or sensor networks where only recent events are important. 适用于只关注最近事件的股票或传感器网络。
Histograms 直方图
The histogram can be used to approximate the frequency distribution of element values in a data stream.
- A histogram partitions (bins) the data by attribute values into a set of contiguous buckets. It is possible to have a multidimensional histogram representing the frequency of values over each attribute dimension, or alternatively to transform all attribute values to a single dimension (by, for example, distance from the all-zeros object).
- Used to approximate query answers about data frequency (more efficient than sampling).
- 直方图可用于近似数据流中元素值的频率分布。
- 直方图通过属性值将数据划分(箱)成一组连续的桶。可以使用多维直方图来表示每个属性维上的值的频率,或者将所有属性值转换为单个维(例如,通过与全零对象的距离)。
- 用于近似查询关于数据频率的答案(比采样更有效)。

若有收获,就点个赞吧
0 人点赞
