
1. Initialise the weights by training 初始化权值
- The weights in the network are set to small random numbers (e.g., ranging from −1.0 to 1.0, or −0.5 to 0.5) by training. 神经网络的初始权重是随机小数字。
- Each unit has a bias associated with it, as explained later. The biases are similarly set to small random numbers by training. 正如后面解释的那样,每个单元都有一个与之相关的偏差。类似地,这些偏差通过训练被设置为小的随机数。
Each testing tuple, is first normalised to [0.0 ~ 1.0]. Consider a normalised tuple 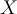 , processed by the following steps.
, processed by the following steps.
2. Propagate the inputs forward 输入向前传播
- First, the testing tuple is normalised to [0.0 ~ 1.0] and the normalised tuple
 is fed to the network’s input layer. The inputs pass through the input units, unchanged. 首先,将测试元组归一化为[0.0 ~ 1.0],并将归一化后的元组馈入网络输入层。输入通过输入单元,没有改变。
is fed to the network’s input layer. The inputs pass through the input units, unchanged. 首先,将测试元组归一化为[0.0 ~ 1.0],并将归一化后的元组馈入网络输入层。输入通过输入单元,没有改变。 - Hidden layer 隐层
- Input of hidden unit: all outputs of the previous layer, e.g. if the hidden unit is in the first hidden layer, then the inputs are
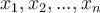 . 隐层的输入都是上一层的输出。
. 隐层的输入都是上一层的输出。 - Output of hidden unit
 : weighted linear combination of its input followed by an activation function 其输入的加权线性组合加上一个激活函数
: weighted linear combination of its input followed by an activation function 其输入的加权线性组合加上一个激活函数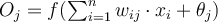
- where
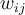 is the weight of the connection from input
is the weight of the connection from input  in the previous layer to unit
in the previous layer to unit 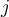
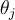 is the bias variable of unit
is the bias variable of unit 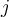
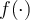 is a non-linear activation function which will be described later.
is a non-linear activation function which will be described later.
- If there is more than one hidden layer, the above procedure will be repeated until the final hidden layer will result outputs.
- Input of hidden unit: all outputs of the previous layer, e.g. if the hidden unit is in the first hidden layer, then the inputs are
- Output layer 输出层
- The outputs of the final hidden layer will be used as inputs of the output layer.
- The number of output units are determined by a task 由任务决定输出层单元数
- If our goal is to predict a single numerical variable, then one output unit is enough 如果目标是预测一个数值变量,那么一个输出单位就足够了
- Final output
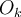 :
: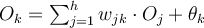 or
or 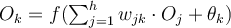
 is the final predicted value given
is the final predicted value given 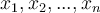 .
.
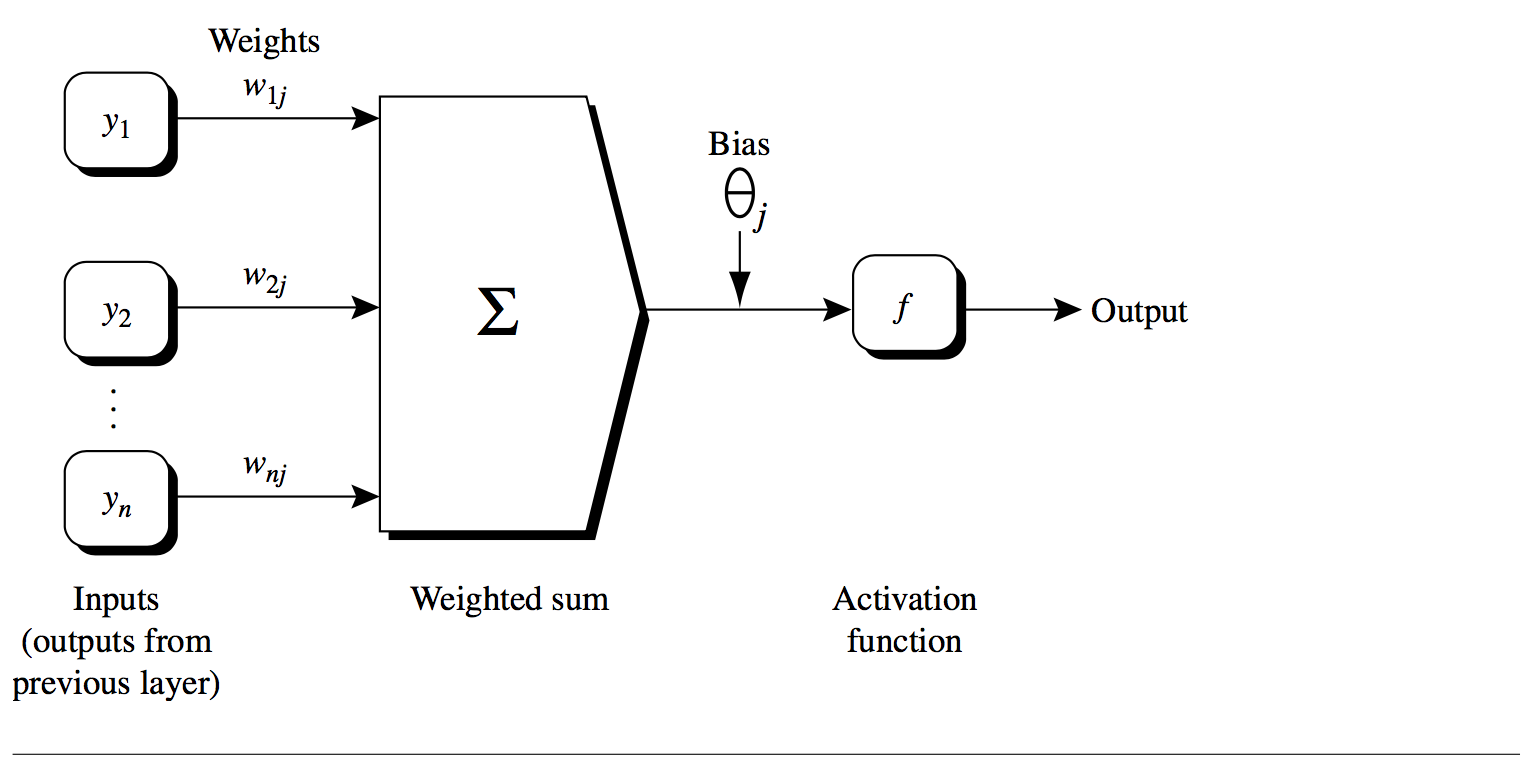
> Graphical illustration of the computational flow of hidden unit 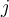 : The inputs to unit
: The inputs to unit 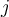 are outputs from the previous layer. These are multiplied by their corresponding weights to form a weighted sum, which is added to the bias
are outputs from the previous layer. These are multiplied by their corresponding weights to form a weighted sum, which is added to the bias 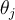 associated with unit
associated with unit 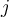 . A nonlinear activation function
. A nonlinear activation function 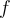 is applied to the net input. Again the output of this unit will be used as an input of the successive layer.
is applied to the net input. Again the output of this unit will be used as an input of the successive layer.
Non-linear activation function
An activation function imposes a certain non-linearity in a neural network. There are several possible choices of activation functions, but sigmoid (or logistic) function is the most widely used activation function.
- Sigmoid function
- Sigmoid functions have domain of all real numbers, with return value monotonically increasing most often from 0 to 1.
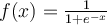
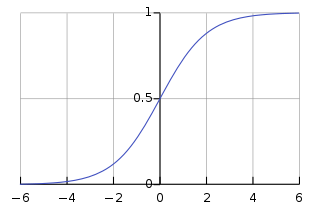
- Also referred to as a squashing function, because it maps the input domain onto the range of 0 to 1
- Other activation functions
- Hyperbolic tangent function (tanh)
- Softmax function (use for output nodes for classification problems to push the output value towards binary 0 or 1)
- ReLU
- etc.
- Hyperbolic tangent function (tanh)

若有收获,就点个赞吧
0 人点赞
