Clustering-based approaches select outliers by examining the relationship between objects and clusters. 基于聚类的方法通过检验对象和聚类之间的关系来找到离群值
An outlier is an object that belongs to a small and remote cluster, or belongs to no cluster. 离群点是属于一个小的远程集群的对象,或者不属于任何集群。
Case 1: Not belonging to any cluster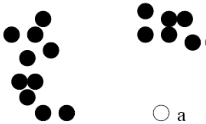
Use a density-based clustering method such as DBSCAN and consider the unclustered points (noise) to be outliers. 使用基于密度的聚类方法,如DBSCAN,并将未聚类的点(噪声)视为异常值。
Example: Identify animals that are not part of a flock of animals e.g. sheep
Case 2: Far from its closest cluster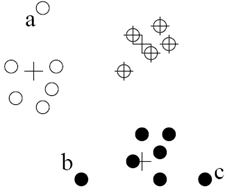
Use k-means clustering (here) to partition data points into clusters.
For each object o, assign an outlier score based on its distance from its closest cluster centre (cluster centres are marked with + in the diagram)
Let 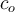 be the closest cluster centre to object
be the closest cluster centre to object 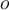 . Let
. Let 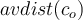 be the average distance of all the objects in the cluster from
be the average distance of all the objects in the cluster from 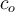 .
.
- If
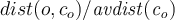 is large then
is large then 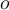 is considered an outlier
is considered an outlier - Alternatively for the case of unseen data
 ,
,
if  for all training data
for all training data 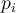 with closest cluster centre
with closest cluster centre  , then
, then  is considered an outlier.
is considered an outlier.
ACTION: Check the Example below
Example: Clustering Based Approaches
Example: Application to Intrusion detection
- Group TCP connections into a segement per day.
- Find frequent itemsets in each segment
- Frequent itemsets occurring in most segments are treated as attack-free
- Segments containing frequent itemsets are the “training data”
- Cluster the training data
- Compare new data points with the clusters mined—Outliers from those clusters are possible attacks
Case 3: Belonging to a small, distant cluster 属于一个小的、遥远的聚类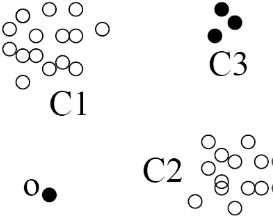
Use, e.g. FindCBLOF algorithm as follows:
- Find clusters, and sort them in decreasing size 找到聚类、并将他们按倒序排序。
- To each data point, assign a cluster-based local outlier factor (CBLOF) 给每一个数据点制定一个基于聚类的局部异常因子:
- If obj p belongs to a large cluster, CBLOF = clustersize X similarity between _p and it’s cluster 如果obj p属于一个大的集群,那么CBLOF =集群大小 X p与其集群之间的相似度
- If p belongs to a small cluster, CBLOF = cluster size X similarity between p and the closest large cluster 如果p属于一个小集群,则CBLOF =集群大小 X p和最近的大集群之间的相似性
- Data points with low CBLOF are considered outliers 低CBLOF则被认为是离群点。
In the diagram above, CBLOF can find that o is an outlier, and that all the objects in cluster C3 are outliers.
Strength of Clustering Based Approaches
- Labelled data not required (unsupervised) 非监督学习
- Works for many data types 支持多种数据类型
- Clusters may be useful data summaries 聚类可能是有用的数据汇总
- Fast checking once clusters are built 一旦聚类搭建成功,检验快速
Weaknesses of Clustering Based Approaches
- Effectiveness dependent on clustering effectiveness 有效性取决于聚类有效性
- Typically high computational cost for clustering 聚类的计算成本通常很高

若有收获,就点个赞吧
0 人点赞
