Semantics is branch of linguistics and logic concerned with meaning 语义学是和意义相关的,和语言学和逻辑学相关分支
Modeling semantics is the holy grail of NLP and a central question in Artificial Intelligence 语义建模是自然语言处理的圣杯,也是人工智能的核心问题。
• Building a robot that can follow natural language instructions to execute tasks 建造一个能够遵循自然语言指令执行任务的机器人。
• Answering questions, such as where is the nearest coffee shop? 询问问题,例如:最近的咖啡店在哪里?
• Translating a sentence from one language into another, while preserving the underlying meaning 将一个句子翻译成另外一个,同时保留潜在语义。
• Fact-checking an article by searching the web for contradictory evidence 通过在网上搜索相互矛盾的证据来检查文章的事实
• Logic-checking an argument by identifying contradictions, ambiguity, and unsupported assertions 通过识别矛盾、歧义和不受支持的断言来检查论点的逻辑
Where is meaning? 语义在哪里?
• My brain
• Your brain
• Words
• Sentences
• Body language
Semantic theories explain how to linguistically represent meaning: 语义理论解释了如何用语言表达意义:
• logical semantics 逻辑语义
• lexical semantics 词汇语义学
Logical Semantice 逻辑语义学
In logical semantics, to semantically analyzed a sentence is to convert it into a meaning representation 在逻辑语义学中,从语义上分析一个句子就是把它转换成一个意义表示
A meaning representation that: 一种意义表示:
• is unambiguous: only one possible interpretation 无歧义的:只有一种可能的解释
• provides a way to link language to external knowledge 提供了一种将语言与外部知识联系起来的方法
• support computational inference 支持推理计算
• expressive enough 有足够的表现力
Unambiguous 无歧义的
Example, code 5 + 3 outputs 8. Also (44)-(33)+1 outputs 8.
These outputs are known as denotations
[[5+3]] = [[(44)-(33)+1]] = [[((8))]] = 8.
The denotations are determined by the meaning of constants (e.g., 3, 5) and the relations (e.g., +, *, (,))
[[double(4)]] = 8 or [[double(4)]] = 44 ?
What is the meaning of double? double的意思是什么?
• it is defined in a world model. 由文字模型定义。
• 𝑑𝑜𝑢𝑏𝑙𝑒 𝑀 = {(0,0), (1,2), (2,4), …},thus [[double(4)]] = 8
• then, denotation of string x in world model M can be computed unambiguously.
External knowledge and Inference 外部知识和推理
Connecting language to external knowledge, observations and actions 将语言和外部知识,观察和行为连接。
The capital of Australia → knowledge base of geographical facts → Canberra
Inference support is to automatically deduced new facts from premises, e.g., first order logic.
If anyone is making noise, then Max can’t sleep.
Abigail is making noise.
Inference: Max can’t sleep.
How?
Apply ‘generalized’ inference rules like modus ponens. 像模顿那样应用“广义”推理规则。
By repeatedly applying such inference rules to a knowledge base of facts it’s possible to infer new knowledge and produce proofs. 通过将这样的推理规则反复应用于事实的知识库,就有可能推断出新的知识并产生证明。
Algorithms: backward chaining, e.g., in prolog (logic programming language) 算法:反向链接,例如,在prolog(逻辑编程语言)中
Semantic parsing 语义分析
In NLP, semantic parsing is the transformation of sentences to a meaning representation, e.g., a logical formula 在自然语言处理中,语义分析是将句子转换成一种意义表示,例如一个逻辑公式
The logic formalism is usually lambda calculus (an extension of First Order Logic)
Alex likes Sam → (λx. LIKES (x, SAM))@ALEX
Alex likes Sam → LIKES (ALEX, SAM)
• Traditionally, semantic parsing analysis was based on syntax structures 传统上,语义分析基于句法结构
• Nowadays, semantic parsing is modeled as a sequenceTOsequence problem using deep learning (like machine translation) 如今,语义解析被建模为使用深度学习(如机器翻译)的序列问题
• Logicalformulas are hierarchical, thus sequenceTOtree algorithms are also used 逻辑公式是分层的,因此也使用顺序排序(sequenceTOtree)算法
Semantic parsing data sets 语义分析数据集
GEO
Input: Question
which is the longest river in USA?
Output: lambda formula
_answer (A, _longest ( A, ( _river (A), _loc (A, B), _const (B, _countryid (usa)))))
ATIS
Input: Question
show me a flight from ci0 to ci1 tomorrow
Output: lambda formula
(lambda $0 e (and ( flight $0) (from $0 ci0) (to $0 ci1) (tomorrow $0)))
WikiSQL
Input: Question
How many engine types did Val Musetti use?
Output: SQL query
SELECT COUNT Engine WHERE Driver = Val Musetti
Predicate-argument semantics 谓词-论元语义
Predicate-argument semantics is considered a light semantic representation 谓词-论元语义被认为是一种轻度语义表示
A predicate is seen as a property that a subject has or is characterized by. 谓词被看作是主语所具有的或以其为特征的属性。
She dances. – verb-only predicate 仅动词谓语
Ben reads the book. – verb-plus-direct-object predicate 动词+目标 谓语
Predicates have arguments 有参数谓语
(arg1: someone) dance
(arg1: someone) read (arg2: something)
(arg1: someone) rent (arg2: something), (arg3: x money), (arg4: n time)
Annie rents an apartment for $200 per week.
Predicates participants or arguments are constrained 谓词参与者或参数受到约束
• Semantic roles 语义角色
• John(AGENT发起者) dance salsa.
• John(EXPERIENCER 感受者) has a headache.
• Selection restrictions
• John rent a dance X
How can we model this in NLP? 如何用自然语言处理建模?
• PropBank: sentences annotated with semantic roles 用语义角色注释的句子
• FrameNet: a hierarchical database of events (e.g. ‘act of teaching’) and arguments to these events (e.g. ‘teacher’, ‘student’, ‘subject being taught’) 事件(如“教学行为”)和这些事件的参数(如“教师”、“学生”、“教学主题”)的分层数据库
• VerbNet: a hierarchical verb lexicon with verbs and their arguments organized as thematic roles ‘AGENT’, ‘RECIPIENT’ … 一个有层次的动词词典,动词和它们的参数作为主题角色被组织起来。
Using these resources, we can train machine learning models to tag predicates and arguments. 利用这些资源,我们可以训练机器学习模型来标记谓词和参数。
Lexical Semantics 词汇语义学
Lexical semantics: linguistic study of word meaning 词汇语义学:词汇意思的语义研究。
Key questions: 核心问题
What is the meaning of words? 单词的语义是什么
Most words have more than one sense 大多数单词都有多于一个多于一个的语义
How are the meanings of different words related? 不同语义的单词如何关联?
Specific relations between senses
Vehicle is more general than car
Semantic fields
travel is related to flight 旅行和飞行相关
Terminology 术语
• Word sense: a discrete representation of one aspect of the meaning of a word 词义的一个方面的离散表示
E.g., bank
• A financial institution: CommBank 金融机构:CommBank
• A particular branch of a financial institution: CommBank in Civic 一个金融银行机构分支
• The bank of a river: the bank of the Murrumbidgee 河岸
• A ‘repository’: blood bank In this example, Bank has four senses “储存库”:血库在本例中,血库有四种感觉
Homonymy 同名: coincidentally share an orthographic form. e.g.,
bank (financial institution), bank (sloping mound)
Polysemy 一词多义: two senses are semantically related两个意义在语义上是相关的, e.g., solution
Work out the solution in your head.
Heat the solution to 75° Celsius.
Homophone 同音字: same pronunciation发音相同, but different spellings但拼写不同. e.g.,
wood/would, to/two
Homograph 同形词: Same orthographic form相同的拼写方式, but different pronunciation但是发音不同 (this is a problem in speech synthesis), e.g., bass
I like to play the bass 乐器 (a musical instrument – bass guitar)
Fresh bass 鱼 is tasty (a fish)
Relations between senses
Synonymy 同义词: two word lemmas are identical or nearly identical 两个词引理相同或几乎相同
couch/sofa car/automobile
Antonyms 反义词: two word lemmas with opposite meaning 两个词有相反的意义
long/short big/little rise/fall in/out
Hyponyms 下位词: one sense is an hyponym of another sense if the first sense is more specific 如果第一种词意更具体,那么一种感觉就是另一种感觉的下位词
car is a hyponym of vehicle 汽车——交通工具
dog is a hyponym of animal 狗——动物
mango is a hyponym of fruit
Hypernyms 上位词**: one sense is an hypernym of another sense if the first sense Is its class 与下位词相反
vehicle is a hypernym of car
animal is a hypernym of dog
cheese is a hypernym of brie
WordNEt
A database of lexical (ontological) relations 词汇(本体)关系数据库
~120k nouns, ~115k verbs, ~20k adjectives, and ~5k adverbs
• Groups words into sets of synonyms called synsets, 将单词组成同义词词集
provides short definitions and usage examples 提供简短的定义和使用示例
• Synset: the set of near-synonyms for a sense Synset:一种意义的近义词集合
• ~80k noun synsets, ~15k verb synsets, ~20k adj. synsets, ~5k adv. Synsets 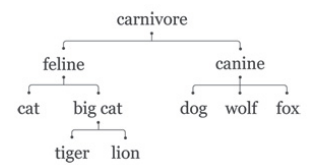
• Hand constructed!
• Website : http://wordnet.princeton.edu/
• In many languages:
• http://globalwordnet.org/resources/wordnets-in-the-world/
Another huge lexical graph is Dbpedia
• It use RDF triplets to encode relations between entities 使用RDF三元组来编码实体之间的关系
• RDF triplet: subj(Golden Gate Park) pred(location) obj(San Francisco) 主题(金门公园)预解码(位置)对象(旧金山)
• ~ 900 million RDF triplets
• Extracted from Wikipedia info-boxes
• http://dbpedia.org/
Wikidata
• well-known people, places, and things
• ~ 12.5 billion triples • Database of facts anybody can edit
• https://www.wikidata.org
Distributional hypothesis 分布假说
How to learn representations for word meanings from unlabeled data? 如何学习表达未标记的单词词义。
This idea is based on the theoretical principle of the distributional hypothesis:
You shall know a word by the company it keep (Firth, 1957). 单词的词义可以从上下文陪伴的单词中推测
E.g.,, the word “chicha” is not in my training data, but I know “chicha” is used in several contexts: 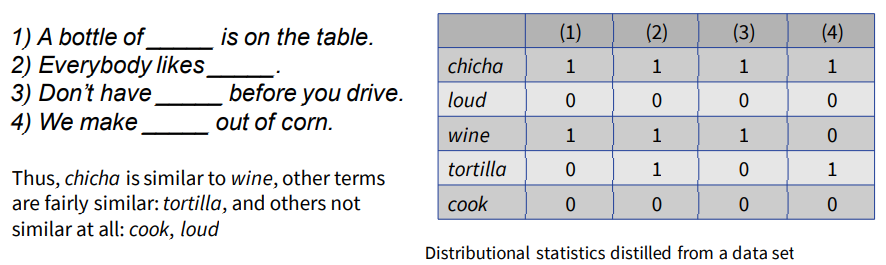
we called these vectors word representations 我们把这张表叫做单词向量表达
According to the distributional hypothesis, vector similarity implies semantic similarity. 根据分布假设,向量相似意味着语义相似。
• Distributional semantics are computed from context statistics (e.g., BROWN Clusters) 分布式语义是从上下文统计中计算得到。
• Distributed semantics represent meaning by numerical vectors, rather than symbolic structures (e.g., LDA, WORD2VEC) 分布式语义通过数字向量来表示意义,而不是符号结构(例如,LDA、WORD2VEC)
Brown clustering 布朗聚类
Some Learning algorithms like CRF and Perceptron perform better with discrete feature vectors.
Discrete representations can be distilled from word vectors by clustering
BROWN clusteringinduces hierarchical representations using cluster mergers that optimise an objective defined on word occurance counts. (no distributed vectors used)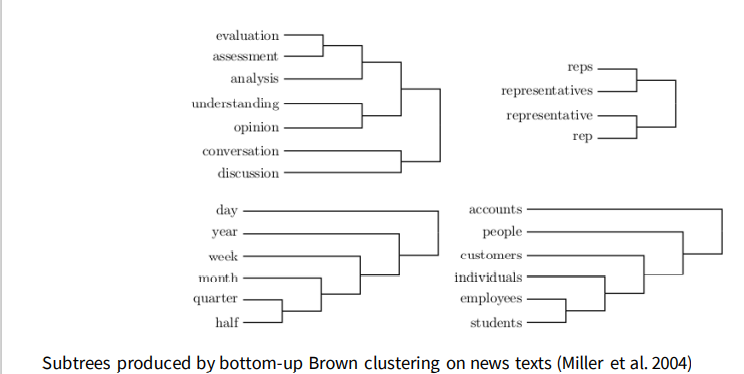
Word embedding
Word embedding: Ensurewords with similar context occupy close spatial positions in multidimensional space, as represented by the vector representations
Character embedding: same idea, but encode at the character level to overcome unseen words (out-of-vocabulary)
Sentence embedding: learn representations from sentences
Reference resolution
Intro
In NLP we can model semantics by looking at the words and the logical structures underlying sentences 在自然语言处理中,我们可以通过观察单词和句子背后的逻辑结构来模拟语义
However, we still need to model other aspects of language such as references and grammar. 但是我们仍然需要对语言的其他方面进行建模,例如引用和语法。
Some of these aspects are easy for humans, but very hard for machines. 其中一些方面对人类来说很容易,但对机器来说很难。
Reference resolution aims to solve referential ambiguity 目标是解决引用歧义

Mentions: text spans that mention an entity e.g. Tim Cook, China, he, the firm 提及一个实体的文本
Coreferent: text spans that refer to the same entity e.g. Tim Cook, he 指提及一个相同实体的文本
Antecedents共指词 of a mention are all coreferent mentions earlier in the text e.g. the antecedent of ‘he’ is ‘Tim Cook’ Grouping text spans which refer to the same entity is typically called coreference resolution.
Referring expressions: pronouns, proper nouns, and nominals 指称表达:代词、专有名词和名词
Tim Cook has jetted in for talks with officials as [he] seeks to clear up a pile of problems.
Pronouns 代词
• Search for candidate antecedents 搜索候选先行词: any noun phrase is the proceeding text is a candidate 任何名词短语都是候选词
• Match against hard agreement constraints 与硬性协议约束相匹配
• he: singular, masculine, animate, third person 奇数、男性、有生命的、第三人称
• officials: plural, animate, third person 复数、有生命的、第三人称
• talks: plural, inanimate, third person
• Tim Cook: singular, masculine, animate, third person
• Select using heuristics 使用试探法进行选择
• Recency – close in the sentence 相邻 - 离句子距离最近的
• Subject over objects – nouns in the subject position (in a dependency parse) are more likely to be coreferent 主语优先于宾语 - 主语位置的名词(在依存分析中)更有可能是共指的。
Proper nouns often corefers with another proper nouns 专有名词经常与另一个专有名词连用
Apple Inc Chief Executive [Tim Cook] has jetted into China… [Cook] is on his first business trip to the country…
Strategies (easier to solve):
- Match the syntactic head words of the reference with the referent 将参考文献的句法中心词与所指对象相匹配
- In machine learning, a solution is to include range of matching features: exact match, head match, and string inclusion. 在机器学习中,解决方案是包括一系列匹配特征:精确匹配、头部匹配和字符串包含。
- Gazetteers of acronyms (e.g., Australian National University/ANU, and other aliases (Queensland Technology University/Queensland Tech) 首字母缩略词的地名录(例如,澳大利亚国立大学/ANU,以及其他别名(昆士兰科技大学/昆士兰科技)
Nominals are noun phrases that are not pronouns nor proper nouns. 名词是既不是代词也不是专有名词的名词短语。
The firm [Apple Inc]; the firm’s biggest growth market [China]; and the country [China]
Hard to solve, as it requires world knowledge: 这很难解决,因为需要外部世界知识
Apple Inc. is a firm
China is a growth market
Algorithms for coreference resolution 共指解析算法
Can be model as structure prediction problem with two tasks: 可以建模为具有两个结构预测问题的任务:
- Identifying spans of text mentioning entities: get noun phrases from a sentence structure (using constituency parsing) and filter using simple rules (remove numeric entities, remove nested noun phrases). 识别提及实体的文本范围:从句子中获取名词短语并简单规则过滤(删除数字 实体,移除嵌套的名词短语)
- Clusteringthose mentions: 集群这些提及
• Mentioned-based models: supervised learning or ranking 基于提及的模型:有监督的学习或者排名机制
• Entity-based models: clustering 基于提及的模型:聚类
Mentioned-based models as classification: 将基于提及的模型视作分类
Mention-pair models: binary label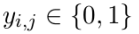 提及配对模型:二 进制标签
提及配对模型:二 进制标签
is assigned to each pair of mentions (i, j), where i < j.
If I and j corefer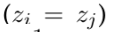 如果i和j共指
如果i和j共指
then,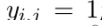 则 y = 1
则 y = 1
otherwise,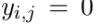 否则 y = 0
否则 y = 0
Use any off-the-shelf classifier to solve this binary problem. 使用任何现成的分类器来解决这个二分类问题。
Also need to use heuristics to construct coherent groups for each entity 还需要使用试探法为每个实体构建连贯的组
Mentioned-based models as ranking
A classifier learns to identify a single antecedent 分类器学习识别单一的先行词
for each refering expression i,
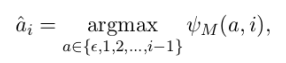
where 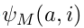 is a score for the mention pair (a, i) if a = ∈, then mention i does not refer to any previously introduced entity.
is a score for the mention pair (a, i) if a = ∈, then mention i does not refer to any previously introduced entity.
• Mention ranking is like the mention-pair model, but all candidates are considerd simultaneously, and at most one antecedent is selected. 提及排名类似于提及对模型,但同时考虑所有候选人,最多选择一个先行词。
• As a learning problem, ranking can be trained using the same objectives as in discriminative classification 作为一个学习问题,可以使用与区分分类中相同的目标来训练排名
• For each mention i, we can define and antecedent , and an associated loss e.g., hinge loss or negative log-likelihood 对于每次提及I,我们可以定义和先行,以及相关损失,例如铰链损失或负对数似然
Mention embedding 提及嵌入
Entity mentions can be embedded into a vector space, providing the base layer for neural networks that score coreference decisions (Wiseman et al., 2015) 实体提及可以嵌入到向量空间中,为对共指决策评分的神经网络提供基础层(Wiseman等人,2015)
Constructing the mention embedding 搭建提及嵌入
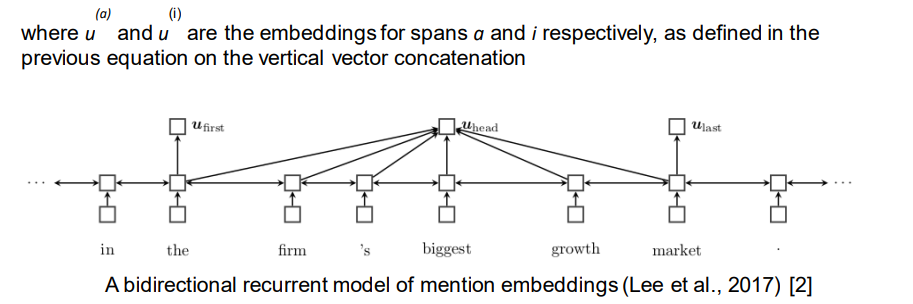
One approach is inspired in embedding multi-word expressions. 一种方法是从嵌入多单词表达式中得到启发。
• Run a bidirectional LSTM over the entire text, obtaining hidden states from the left-to-right and right-to-left passes
Each candidate mention span (s, t) is then represented by the vertical concatenation of four vectors: 然后,每个候选提及跨度(s,t)由四个向量的垂直串联表示:
Using mention embedding 使用提及嵌入
Given a set of mention embedding, each mention i and candidate antecedent a is scored as,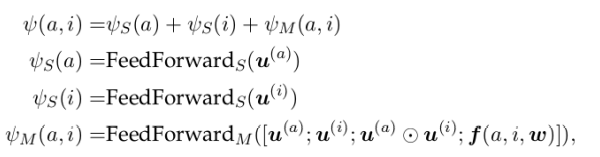
Entity-based models 基于实体的模型
It’s more realistic as coreference resolution is a clustering problem rather than classification or ranking
Entity-based model require a scoring function at the entity level, e.g.,
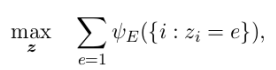
where z i is the entity referenced by mention i, and 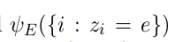 is a scoring function applied to all mentions i that are assigned to entity e.
is a scoring function applied to all mentions i that are assigned to entity e.
To implement this in practice requires some form of search to group mentions so that they can be scored:
• Brute force
• Incrementally build up clusters
• Actions learnt by reinforcement learning
Take away
Meaning in natural language can be modeled in several ways, e.g.,
• using logic or
• using relations between words (synonyms, hyperonyms, etc.)
In NLP we use formalism (first order logic, predicate structures, etc.) and resources (WordNet, DBPedia, etc.) to enrich text with meaning and knowledge about the world
Modeling reference expressions add another layer of knowledge to the text, and it’s crucial in applications such as machine translation and automatic summarization

若有收获,就点个赞吧
0 人点赞
