A few general-purpose methods are given here, and each can be varied acording to the clustering method, the cluster quality heuristic or domain knowledge. Note that the Elbow and Cross-validation methods require many clustering attempts with different numbers of clusters, so could be prohibitively expensive over the full data set. Consider selecting a random sample of the data for this purpose.
Empirical method 经验方法
- Try number of clusters
 for a dataset of n points. Then each cluster would be expected to have
for a dataset of n points. Then each cluster would be expected to have 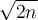 points.
points.
Elbow method
- As the number of clusters goes up, the within-cluster variance, that is the distances amongst points in the cluster (defined as the sum of squared distances between each object and the centroid) decreases to zero. So aim to choose a number that tends to reduce the sum of each within-cluster variance, but increasing the number any further would have only have marginal effect on the variance.
- Use the turning point in the curve of sum of within cluster variance w.r.t the number of clusters.
- To implement:
- For many choices of k>0 (in the extreme, k = 1.., n), execute the clustering with parameter k and calculate sum of within-cluster variances for that k. Plot each k against its sum. Choose the k corresponding to a notable bend in the curve to be the “right” number of clusters.
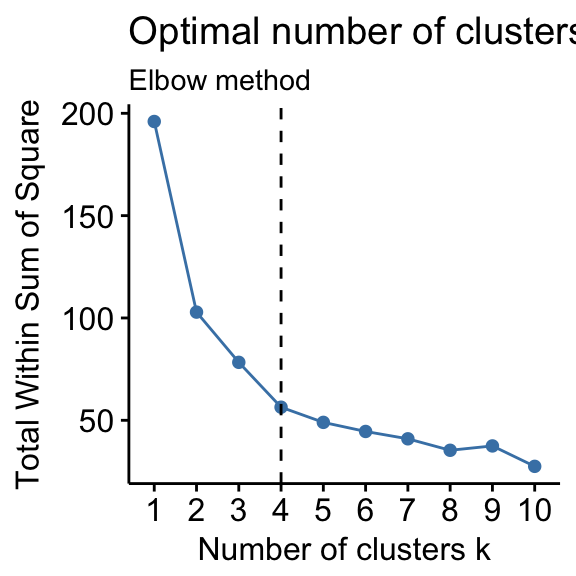 Figure from www.sthda.com demonstrating the elbow method. In this case k = 4 would be a good choice.
Figure from www.sthda.com demonstrating the elbow method. In this case k = 4 would be a good choice.
Cross validation method
- Divide a given data set into m parts 将给定的数据集分成m个部分
- Use m – 1 parts to obtain a clustering model. 使用m-1部分获得聚类模型。
- Use the remaining part to test the quality of the clustering. 使用剩余部分测试聚类的质量。
- E.g., For each point in the test set, find the closest centroid, and use the sum of squared distance. between all points in the test set and the closest centroids to measure how well the model fits the test set 用测试集中的每个点和最近的聚类中心做方差,检测聚类分析效果。
- For several choices of k > 0, repeat it m times and compute the overall quality as the average for each of the m times. Compare the overall quality measure w.r.t. different k’s, and choose the number of clusters that corresponds to the k that has the best overall quality.
- 对于k > 0的几个选项,重复m次,并计算m次中每一次的平均整体质量。比较不同k的总体质量度量,并选择与具有最佳总体质量的k相对应的聚类数。

若有收获,就点个赞吧
0 人点赞
