Similarity metrics: measure the closeness of a document to a query (a set of keywords). 相似性度量:衡量文档与查询(一组关键词)的接近程度
Boolean queries
For Boolean queries such as in a library catalogue, a query is composed of index terms linked by three
connectives: not, and, and or.
That is, for queries of the form W_AND WAND NOT Wfor words _W, the index can be used directly to retrieve matching documents (possibly after query pre-processing to remove stop words etc).
Vector space model
If querying, the query itself is modelled as any other document for matching. We want to be able to _rank _matching documents by similarity to the query. For this we use dot product or cosine similarity, over weighted term vectors.
We can use simple boolean weights, i.e. 0 for a term’s absence and 1 for a term’s presence, or, the count of the number of times a term occurs, but more sophisticated weightings have shown to be beneficial.
Given two documents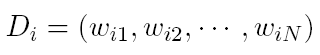 and
and 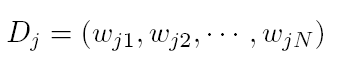
**
Dot Product similarity:
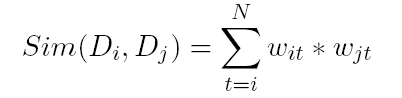
Normalised Dot Product (cosine similarity):
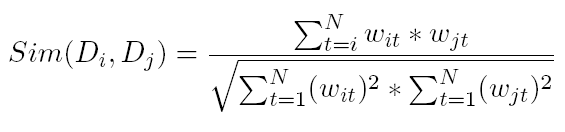
Action: Recall cosine similarity for sparse vectors? Revisit the worked example there.
- If the document vectors are orthogonal in vector space, the angle between the vectors will be 90° and similarity = cos(90) = 0 如果文档向量在向量空间中是正交的,向量之间的角度将为90°,相似度= cos(90) = 0
- If the document vectors are co-linear, the angle betwen them will be 0° and similarity = cos(0) = 1 如果文档向量是共线的,它们之间的角度将为0,相似度= cos(0) = 1

若有收获,就点个赞吧
0 人点赞
