Here are three weighting heuristics based on term frequency and document frequency, but many other variants are used in practice. TF-IDF is a very common choice. 这里有三种基于术语频率和文档频率的加权启发式方法,但在实践中也使用了许多其他的变体。TF-IDF是非常常见的选择。
TF (Term Frequency)
- More frequent within a document => more relevant to semantics of document as a whole 文档中出现的越多,和文档的整体语义越相关。
- Raw TF = tf(t,d) from the term-document matrix i.e. how many times term t appears in doc d
- However,
- Document length varies => relative frequency within the document preferred to avoid bias against short documents. 文件长度会变化,因此使用相对频率,避免对长短文件的偏见。
- Relevance is not linearly proportional to the term frequency. 相关性和出现频率非线性相关。
- So perform normalisation or scaling. Many ways are possible. 有多种方法来执行标准化和缩放。
For example, use Logarithmic Term frequency 对数项数频率: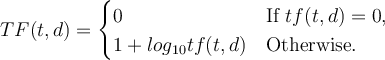
e.g.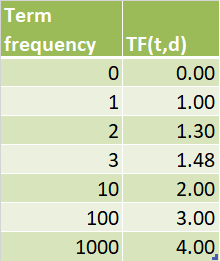
IDF (Inverse Document Frequency) 反向文件频率
• Terms less frequent among documents in collection ==> more discriminative and hence more useful 在总的文档集合中出现频率越低的词越具有代表性。
So assign a higher weight to rare terms than frequent terms using IDF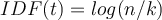 , where**
, where**
n = total number of documents
k = number of documents with term t appearing in them at least once (also called DF(t))
Example:
Let’s assume have n = 1,000,000 documents in the collection.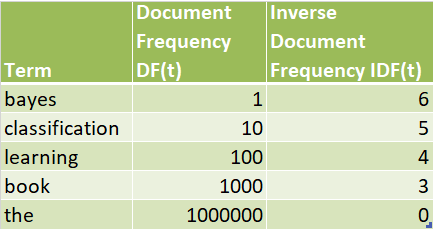
TF-IDF (Inverse Document Frequency)
TF and IDF may be combined to form the TF-IDF measure
TF-IDF(t, d) = TF(t, d) * IDF(t)
• Terms that are frequent within a doc tend towards a high TF which tend towards a high TF-IDF weight 在文档中频繁出现的术语倾向于高TF,这倾向于高TF-IDF权重
• Terms that are selective among docs tend towards a high IDF which tend towards a high TF-IDF weight 在文档中有选择性的术语倾向于高信息密度,而信息密度倾向于高TF-信息密度权重

若有收获,就点个赞吧
0 人点赞
