Syntactic Analysis – determining the syntactic structure of text by analyzing the underlying grammar (of the language) 句法分析——通过分析(语言的)基本语法来确定文本的句法结构
• Syntax = how words combine to form phrases and sentences 语法Syntax = 单词怎么样结合形成短语和句子
• Gives a deeper understanding of word groups and their grammatical relationships 更深入地理解词群及其语法关系
• Sentences are not simply bags of words: 句子不仅仅是一大堆单词:
Mary bought John a coffee
vs
John bought Mary a coffee
Parsing
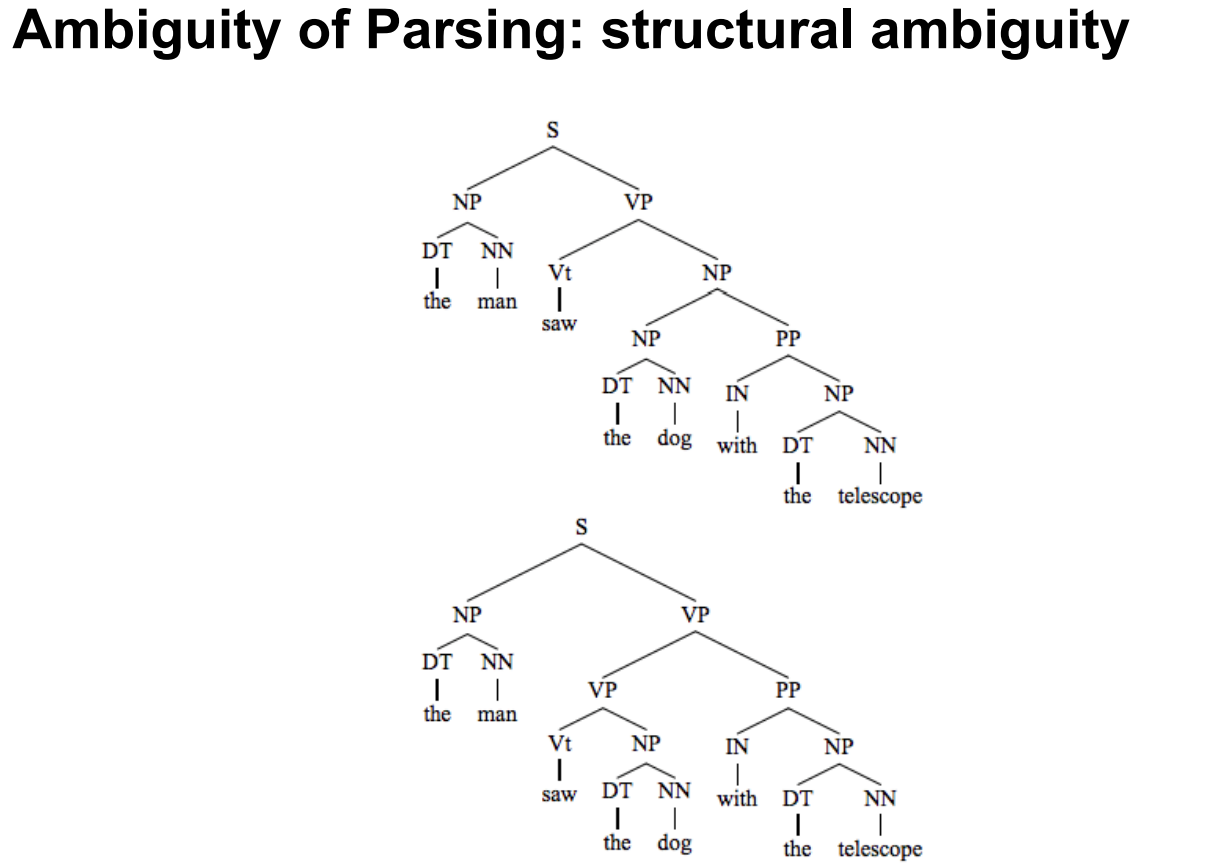
• Formally tries to resolve structural ambiguity in text E.g., Mary saw a cat with binoculars 尝试解决文本中的结构歧义
• Typically, in the broad context of the NLP Pipeline: Tokenize → POS Tag → Parse → …
• Applications: 应用
− Machine Translation 机器翻译
− Question Answering 问答
− Text Summarisation 文本总结
− Grammar Checking 语法检查
− Information Extraction 信息提取
• Constituency Parsing 选取分析
• Phrases represented as nodes in a tree 短语表示为树中节点的短语
• Dependency Parsing 依赖性解析
• Dependencies between words 单词之间的依赖关系
• Dependency parsing is typically faster and works for many (all?) languages 依赖解析通常更快,适用于许多(所有?)语言
• Constituency parsing tends to favor languages with somewhat fixed word order patterns, and clear constituency structures e.g., English 选区分析倾向于使用具有固定词序模式和清晰选区结构的语言,例如英语
How to represent sentence structure 怎样去表示句子结构?
Constituency tree 选区树
(phrase structure tree) (短语结构树)
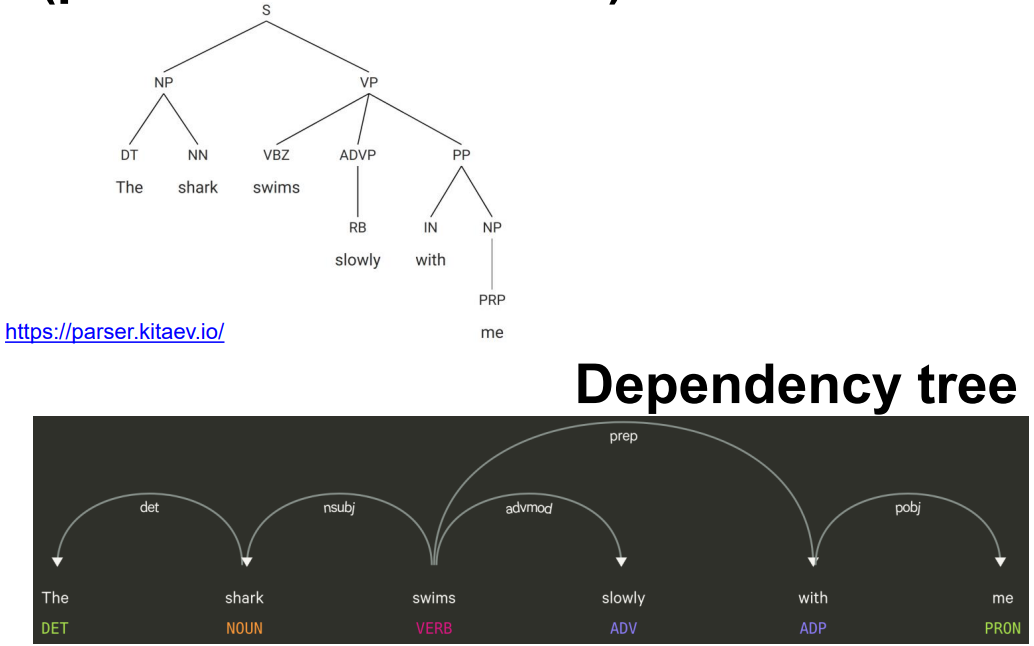
Constituency Parsing
Adds more structure to POS tagged sentences 给词性标注的句子增加更多的结构
Splits sentences into sub-phrases or constituents 将句子分成子短语或成分
Tree form:
Types of phrases = non-terminals 短语类型=非终结符
Words in the sentence = terminals 句子中的单词=终端
Also known as Phrase Structure Trees 也称为短语结构树
Constituent Parse Tree
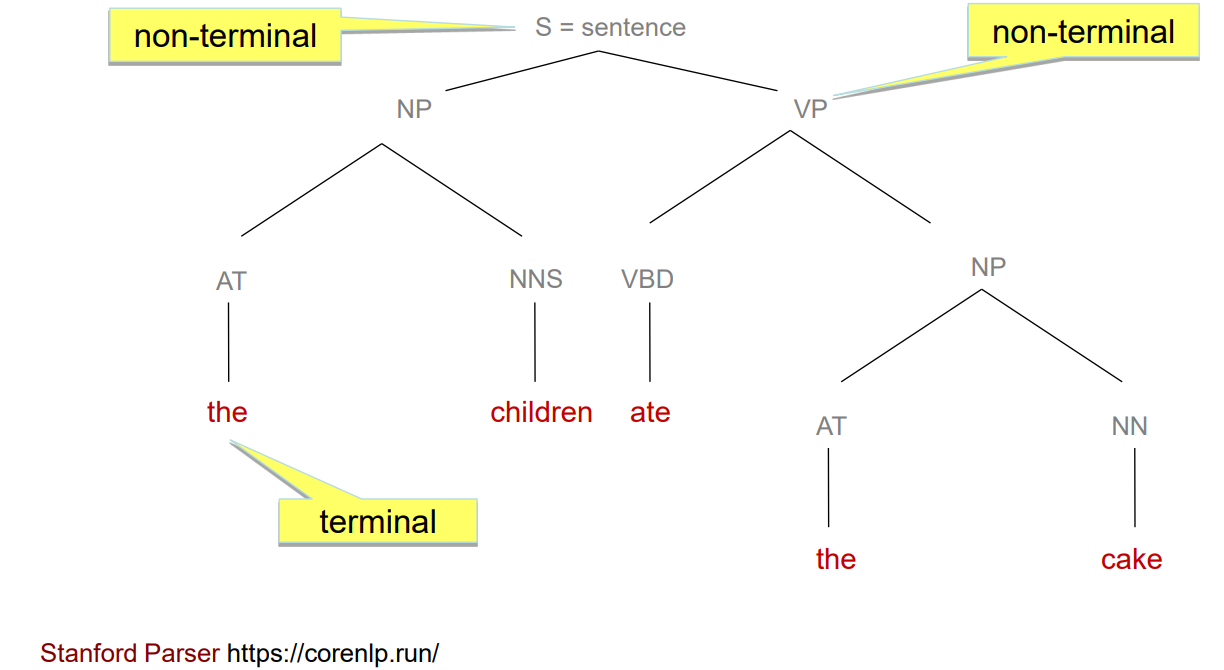
Constituent: a word or a group of words that behaves as a single unit 一个单词或一组单词表现成一个单独的单元格
Why do these words group together? 为什么他们需要成组?
• Appear in similar syntactic environments 出现在一些小的语境中
• Preposed or postposed construction 前置或后置结构
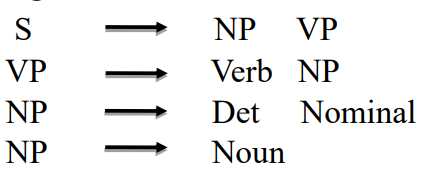
A context free grammar consists of: 上下文无关语法包括:
• a set of context-free rules, each of which expresses the ways that symbols of the language can be grouped and ordered together 一组与上下文无关的规则,每条规则都表达了语言符号可以分组和排序的方式
NP是名词短语、VP是动词短语、PP是介词短语。
• a lexicon of words and symbols, and a set of rules which express facts about the lexicon. 词汇和符号词典,以及一套表达词典事实的规则。
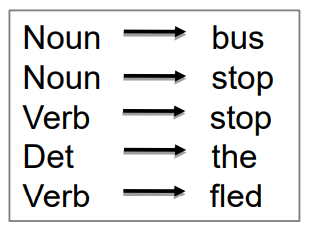
These are the building blocks of a Constituency Parser 这些是选区解析器的构建块
Context-Free Grammars (CFGs) 上下文无关法
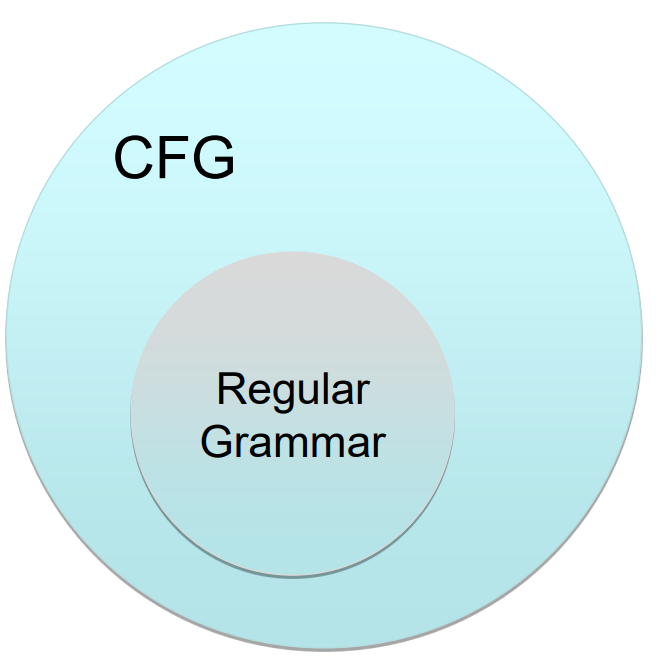
CFGs are more general than Regular Grammars
Formal Definition of CFG

CFGs Derivations CFG衍生
The sequence of rule expansions is called a derivation of the string of words 规则扩展的序列被称为单词串的派生
A Toy Example

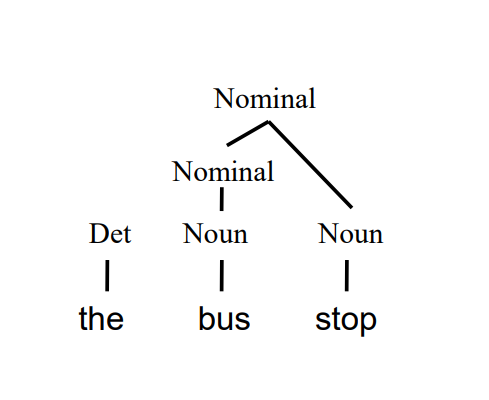
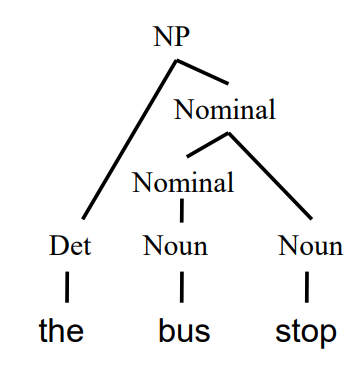
Probabilistic Context Free Grammars (PCFGs) 概率上下文无关法则
A parameter to each grammar rule [3]
Learning PCFG from Treebanks
• Penn treebank and English Web treebank
Grammar Equivalence
• Two grammars are equivalent if they generate the same language (set of strings)
• Chomsky Normal Form (CNF)
• Allow only two types of rules. The right-hand side of each rule either has two non-terminals or one terminal,
• except 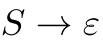 (where is the empty string)
(where is the empty string)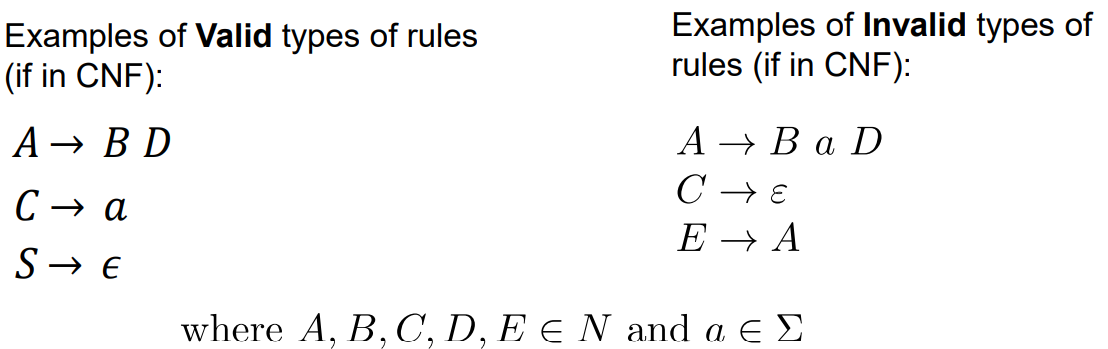
Top Down Parsing 上到下编译
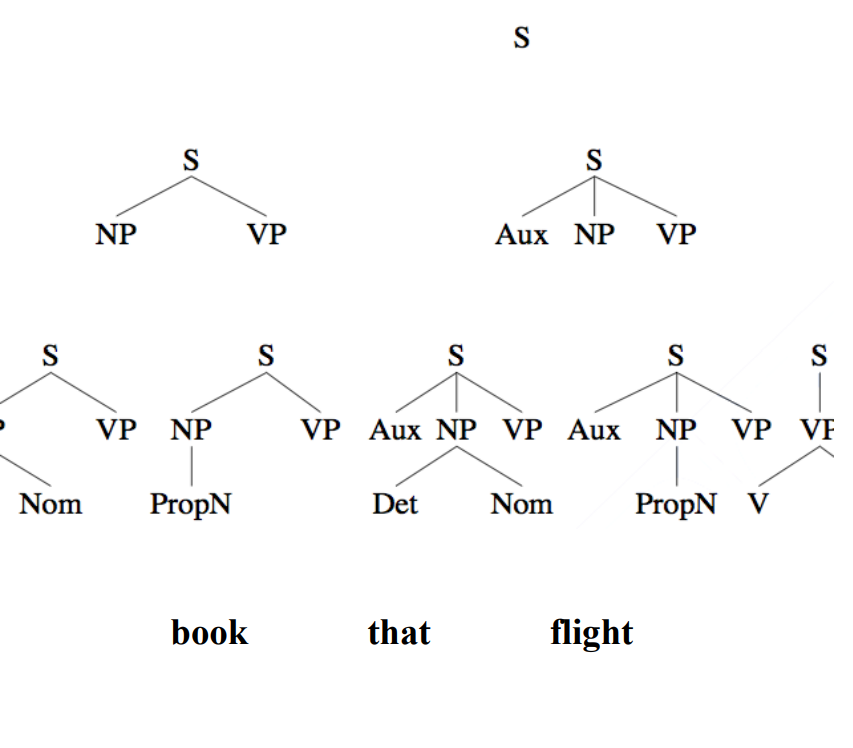
Bottom Up Parsing 从下到上编译
Available Constituency Parsers
Stanford Parser http://nlp.stanford.edu/software/srparser.shtml
Berkley Neural Parser https://spacy.io/universe/project/self-attentive-parser
UCSD Rethinking Self-Attention https://github.com/KhalilMrini/LAL-Parser

若有收获,就点个赞吧
0 人点赞
