Group linkage
● Traditional (probabilistic) record linkage considers individual record pairs, and classifies each pair individually
● In some applications we have groups of records
– People living in the same household (for example in census databases)
– Publications written by a group of co-authors
● Group linkage algorithms make use of such information to improve linkage quality
– First they generally calculate similarities between individual records
– Then calculate group similarities based on graph algorithms
● Example: Linking households in historical census databases (PhD thesis by Zhichun (Sally) Fu, ANU 2014)
● Calculate household similarities using Jaccard or weighted similarities (based on pair-wise links)
● Promising results on UK Census data from 1851 to 1901 (town of Rawtenstall, around 17,000 to 31,000 records)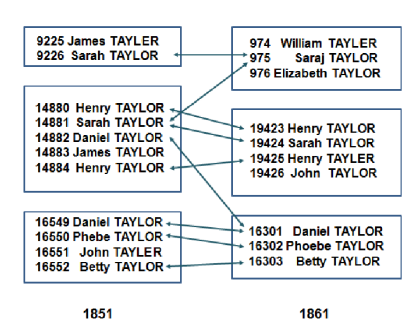
Graph-matching based on household structure
● One graph per household, find best matching graphs using both record attribute and structural similarities
● Edge attributes are information that does not change over time (like age differences)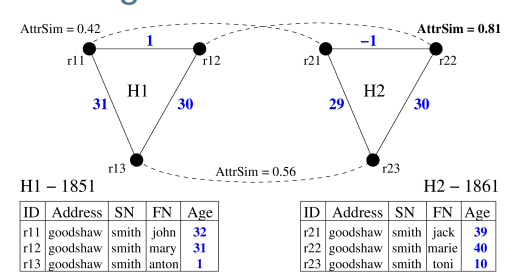
Collective linkage techniques
● Group and graph techniques generally still are based on pair-wise similarities, and they classify each group individually 群组和图表技术通常仍然基于成对的相似性,并且它们对每个群组进行单独分类
– Still have the problem of possibly violating transitivity 仍然可能出现违反传递性的问题
● Recently developed collective techniques aim to find an overall based linkage solution 最近开发的集体技术旨在找到一个基于整体的链接解决方案
– Generally based on some form of clustering (grouping) of records, where each cluster should contain all records about the same entity 通常基于某种形式的记录聚类(分组),其中每个聚类应该包含关于同一实体的所有记录
– These approaches take relationships into account when calculating similarities (not just attributes) 这些方法在计算相似性(不仅仅是属性)时会考虑关系
– Generally lead to improved linkage quality, but at much higher computational costs 通常会提高链接质量,但计算成本要高得多
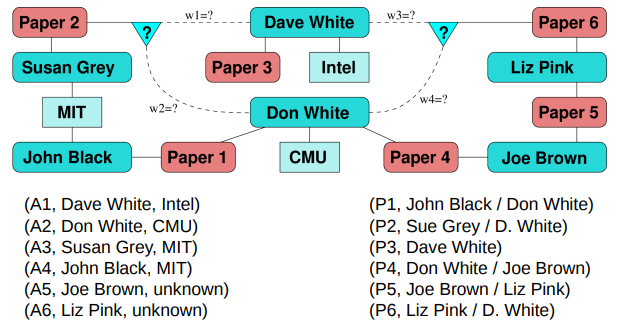
Active learning
● Supervised classification techniques for record linkage generally result in improved linkage quality 记录链接的监督分类技术通常会提高链接质量
● However, training data in the form of true matches and true non-matches are rarely available in practice 然而,真实匹配和真实非匹配形式的训练数据在实践中很少可用
● They have to be manually generated, which is generally difficult both in terms of cost and quality 它们必须手动生成,这通常在成本和质量方面都很困难
● Two challenges stand out:
1. How can we ensure good examples (record pairs) are selected for training? 们如何确保选择好的示例(记录对)进行训练?
2. How can we minimise the user’s burden of labeling examples?我们如何最大限度地减少用户标记示例的负担?
● Active learning is the process of combining a supervised machine learning classifier with manual classification
● An iterative process where
1) A machine learning classifier is trained on some initial training data (possibly already available or manually generated) 机器学习分类器基于一些初始训练数据(可能已经可用或手动生成)进行训练
2) A set of difficult to classify training examples (record pairs) are given to a domain expert for manual classification and added to the training set 将一组难以分类的训练实例(记录对)交给领域专家进行人工分类,并添加到训练集中
3) An improved machine learning classifier is trained 训练一个改进的机器学习分类器
4) The process is repeated until (a) high enough linkage quality is achieved or (b) a budget for the amount of manual classifications possible is reached重复该过程,直到(a)达到足够高的链接质量或(b)达到可能的人工分类数量的预算
Monotonicity of similarities相似性的单调性
● Assumption of most active learning techniques for record linkage: The higher the overall similarity between records is the more likely they are true matches
● In practice, monotonicity does generally not hold实际上,单调性一般不成立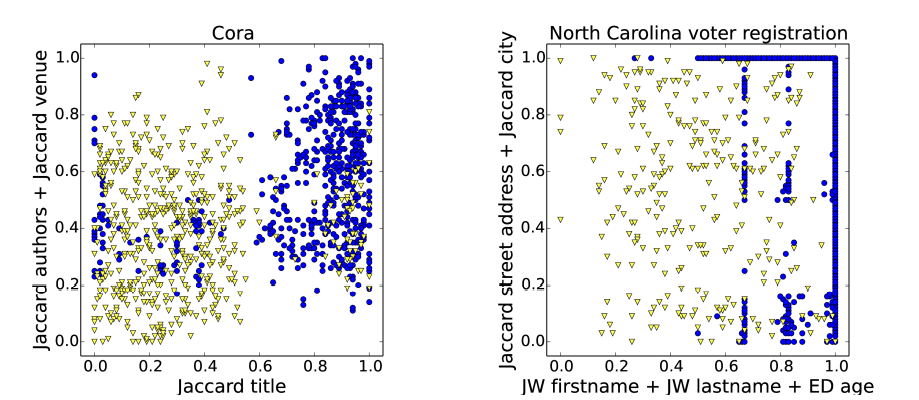
Adaptive and interactive training data selection 适应性和交互式训练数据选择
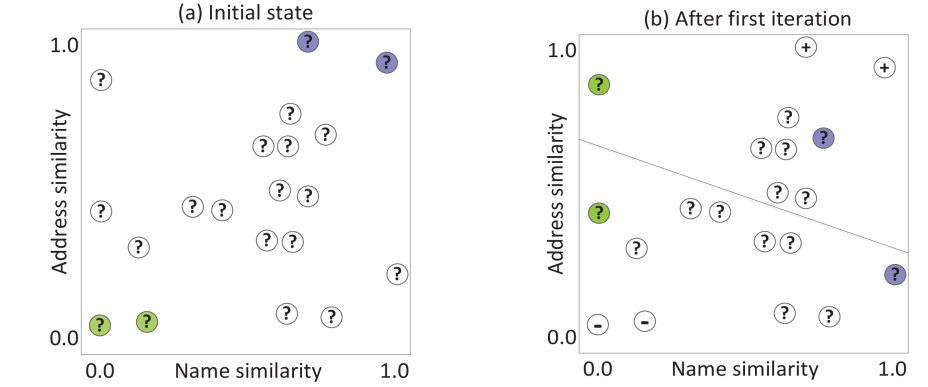
● Our approach exploit the cluster structure of similarity vectors calculated from compared record pairs 我们的方法利用了从比较记录对计算的相似性向量的聚类结构
● In each iteration, a selected set of record pairs is manually classified在每次迭代中,一组选定的记录对被手动分类
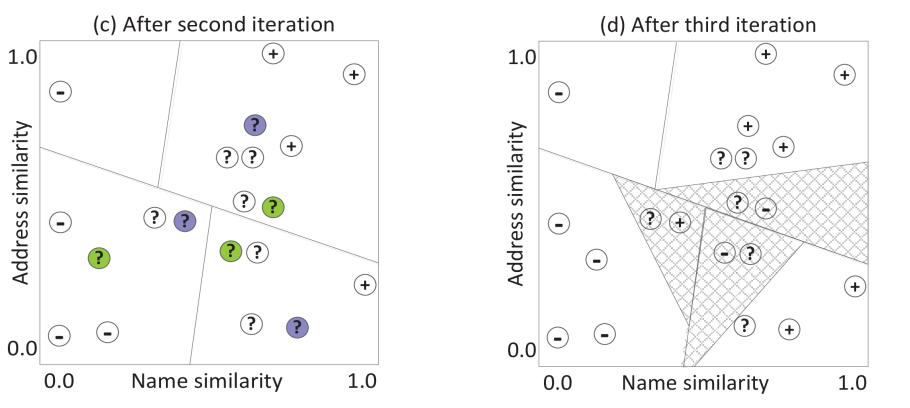
● We recursively split the set of similarity vectors to find pure enough sub-sets for training 我们递归地分割相似向量集,以找到足够纯的子集用于训练
● We select clusters into the training set if they have a minimum purity, otherwise they are inserted into a queue for further recursive splitting 如果聚类具有最小纯度,我们将它们选择到训练集中,否则它们被插入到队列中用于进一步递归拆分
Geocode matching 地理编码匹配
● Aim is to match addresses against geocoded reference data (addresses and their geographic locations: latitudes and longitudes) 目的是将地址与地理编码参考数据(地址及其地理位置:纬度和经度)进行匹配
● Useful for spatial data analysis / mining and for loading data into geographical information systems 有助于空间数据分析/挖掘和将数据载入地理信息系统
● Matching accuracy is critical for good geocoding (as is accurate geocoded address data) 匹配精度对于良好的地理编码至关重要(精确的地理编码地址数据也是如此)
● Australia has a Geocoded National Address File (G-NAF) since early 2004 (all Australian property addresses and their locations)
● Commercial geocoding systems in the past have been based on street centreline data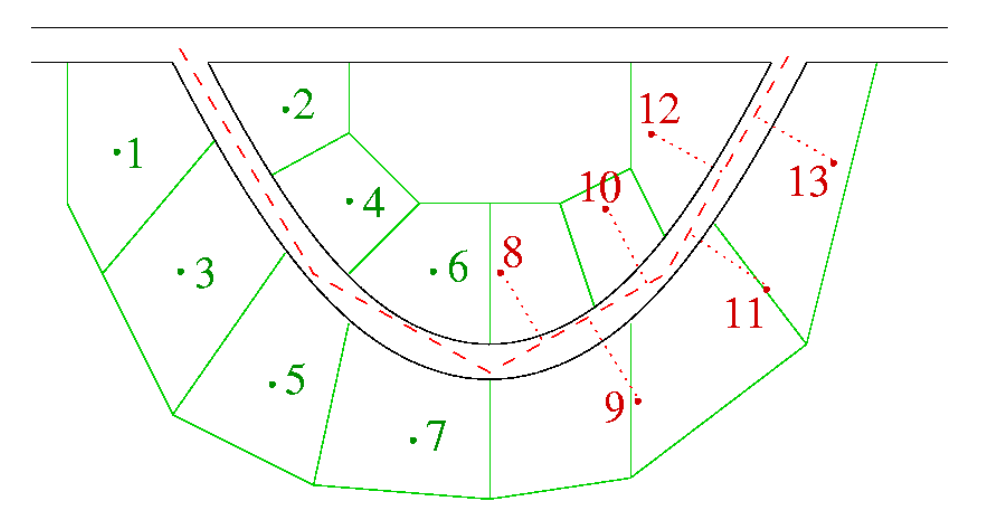
Linking temporal and dynamic data 链接时态和动态数据
● So far we assumed the databases to be linked are static and do not contain temporal information
● However, many databases contain time-stamps for all records 很多随时间变化的动态数据库
– When a record was added to the databases (a new customer or a new patient) 向数据库中添加数据
– When a record was modified (change of name or address details of a person) 调整数据
● Approaches to linking temporal data aim to make use of patterns in such changing details 连接时态数据的方法旨在利用这些不断变化的细节中的模式
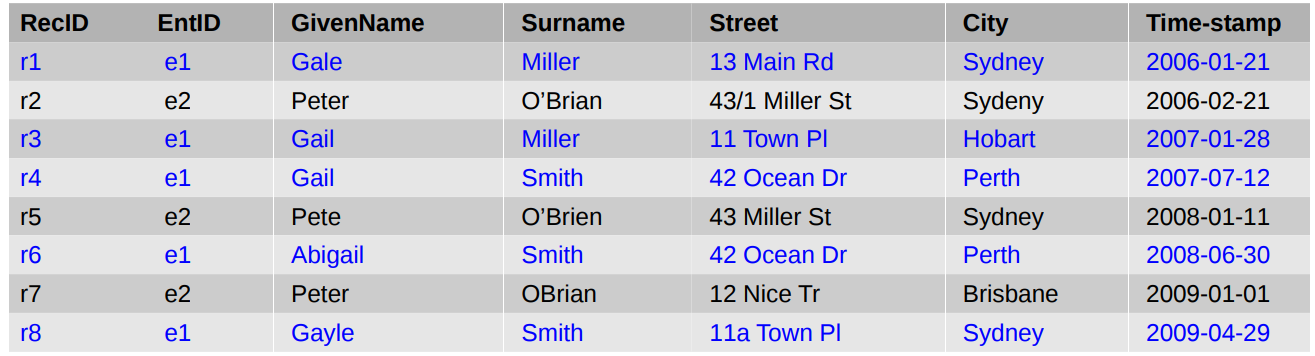
● An entity changes address values more often than surname values
● Small variations in values are possible (no actual changes)
● Several entities can have the same value in an attribute
● Basic ideas of linking temporal and dynamic data are to adjust the similarity weights based on probabilities of attribute values changing over time 链接时态和动态数据的基本思想是基于属性值随时间变化的概率来调整相似性权重
– For example, if two records are five years apart and they have a different address then this doesn’t mean they necessarily refer to different people 例如,如果两个记录相隔五年,并且地址不同,这并不意味着它们一定指的是不同的人
– Therefore, a low address similarity is given a small weight in a weighted similarity calculation (as discussed in the intensive week) 因此,在加权相似度计算中,低地址相似度被赋予较小的权重(如密集周中所讨论的)
● We calculate temporal agreement and disagreement based on temporal value changes over time 我们根据时间值随时间的变化来计算时间一致性和不一致性
– For example, address and surname values are more likely to change compared to given name or gender例如,与给定的姓名或性别相比,地址和姓氏值更有可能发生变化

若有收获,就点个赞吧
0 人点赞
