- Recap 概述
- Neural Network Language Models
- Unigram Language Model 元语言模型
- A Neural Network Language Model
- Probability of a Sequence 句子序列的可能性
- Generating a Sequence 生成一个序列
- Neural Networks of Sequences
- Recurrent Neural Network 递归神经网络
- Recurrent Cell 递归单元
- Recurrent Neural Network
- RNN for Classification
- Backpropagation Through Time 反向传播
- Problems with the Simple RNN 简单RNN神经网络的问题
- More Advanced Recurrent Modules 更多改良的递归模型
- Gated Recurrent Unit (GRU) 递归门单元网络
- Long Short-Term Memory (LSTM)
- RNN and Terminology
- RNN for Language Modelling
- Multi-layer RNN
- Bi-directional RNN
- Padding
- Recursive neural network: Tree structure
Recap 概述
• Neural networks estimate a function which maps vectors to vectors 神经网络估计出将向量映射到向量的函数
• Now we want neural networks that can handle structured input and structured output 现在我们需要能够处理结构化输入和结构化输出的神经网络
NN for NLP: Structured Input 结构化输入
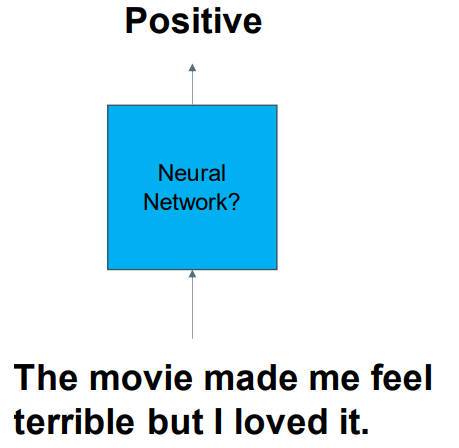
NN for NLP: Structured Output 结构化输出
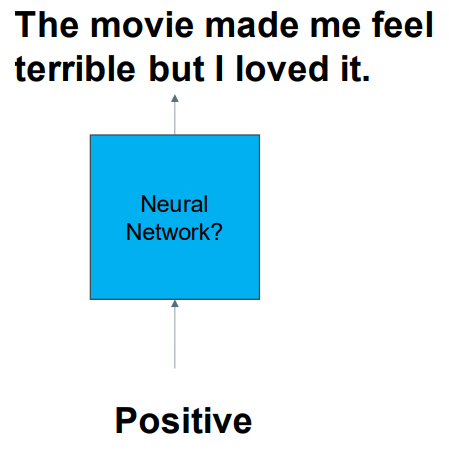
Text is Structured 结构化文档
We couldn’t shuffle the words or characters of a sentence and expect to retain the meaning. 我们不能打乱一个句子的单词或字符,并期望保留意思。
The meaning of a word, phrase or sentence is determined by the surrounding context. Eg “The bank was grassy.”, “The bank took my deposit.” 一个单词、短语或句子的意思是由周围的语境决定的。“银行长满了草。”,“银行拿走了我的存款。”
Text has a sequential reading order (e.g. left to right in English). 文本具有连续的阅读顺序(例如,英语中从左到右)。
Neural Network Language Models
Build a neural network that: 建立一个神经网络
• Generates text 生成文档
• Gives the likelihood of a text sequence 给出文本序列的可能性
Auto-regressive: 自动回归
• Take the previous k words and build a classifier to predict the next word. 取前k个单词,构建一个分类器来预测下一个单词。
Unigram Language Model 元语言模型
Let’s, choose k=1 for this example: 选择前k=1 个单词来作为例子。
Sentence: The best city in Australia.
Step 1: -> The
Step 2: The -> best
Step 3: city -> in
Step 4: in -> Australia.
A Neural Network Language Model
输出关于下一个单词的概率分布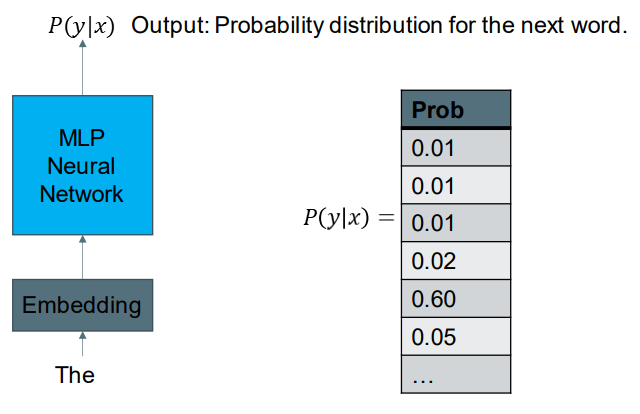
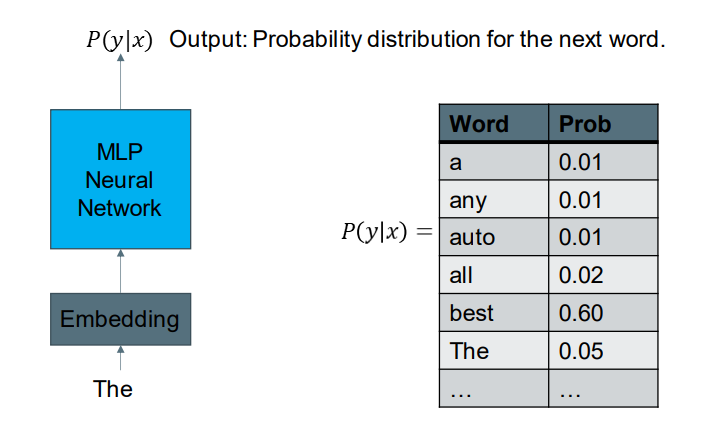
Probability of a Sequence 句子序列的可能性
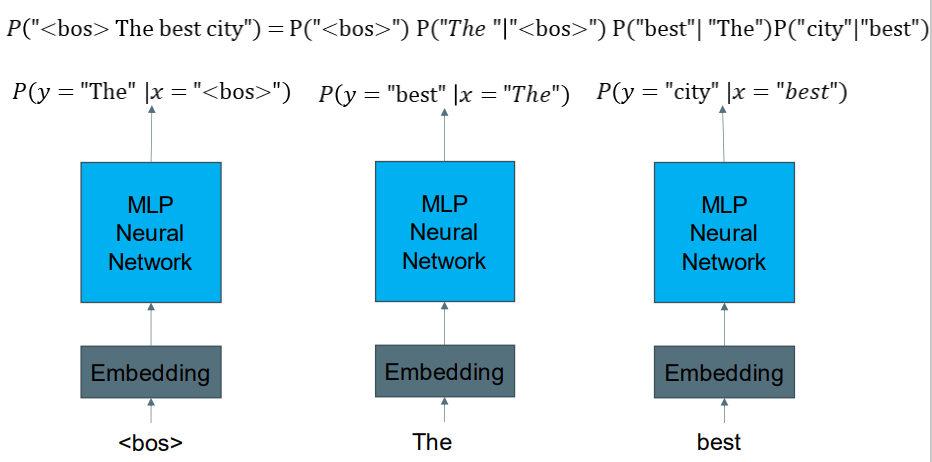
Generating a Sequence 生成一个序列


Choosing the largest probability at every step is called argmax decoding.
We can also sample from the probability distribution to generate random sequences.
Neural Networks of Sequences
Major problem: sequences can have different lengths 主要问题:序列可以有不同的长度
MLP Neural networks take a fixed size input. MLP多层感知器神经网络采用固定大小的输入。
We want neural networks to accept sequences as input. 我们希望神经网络接受序列作为输入。
We can input the vector representation of a word and do classification. 我们可以输入一个单词向量并对其分类。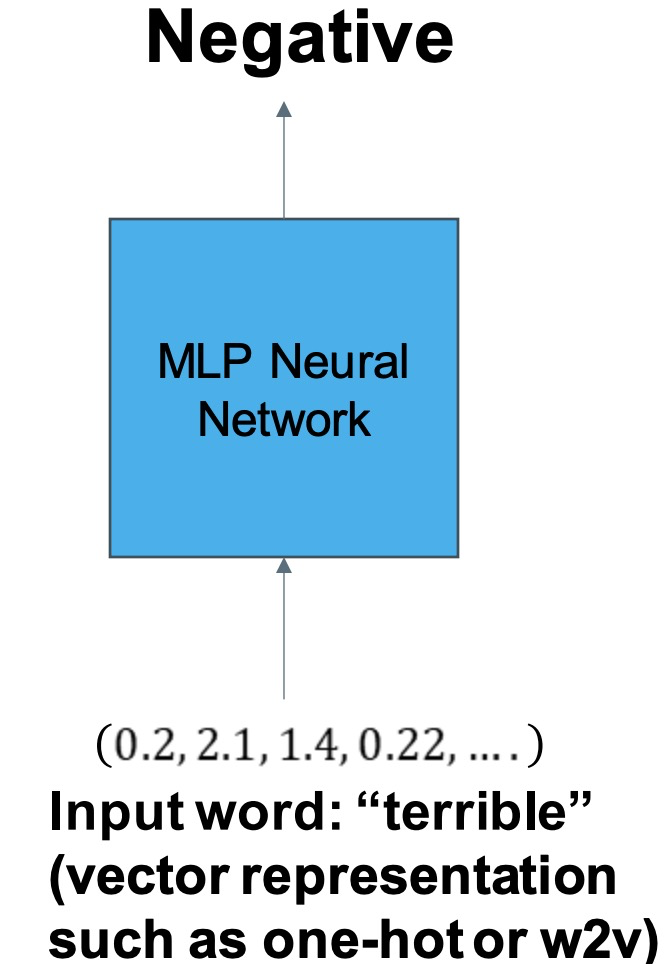
But what about the other words in the document, and the structure? 但是文档中其他的单词和结构呢?
Recurrent Neural Network 递归神经网络
• Process the input sequence one word at a time 一次处理一个单词的输入序列
• Assume we have a fixed length vector representation of all of the words up to the current index. Called the history 假设我们有一个固定长度的矢量表示,表示到当前索引为止的所有单词。叫做历史
• Then we use a neural network to map the current history and the current word to the next history representation. 然后,我们使用神经网络将当前历史和当前单词映射到下一个历史表示。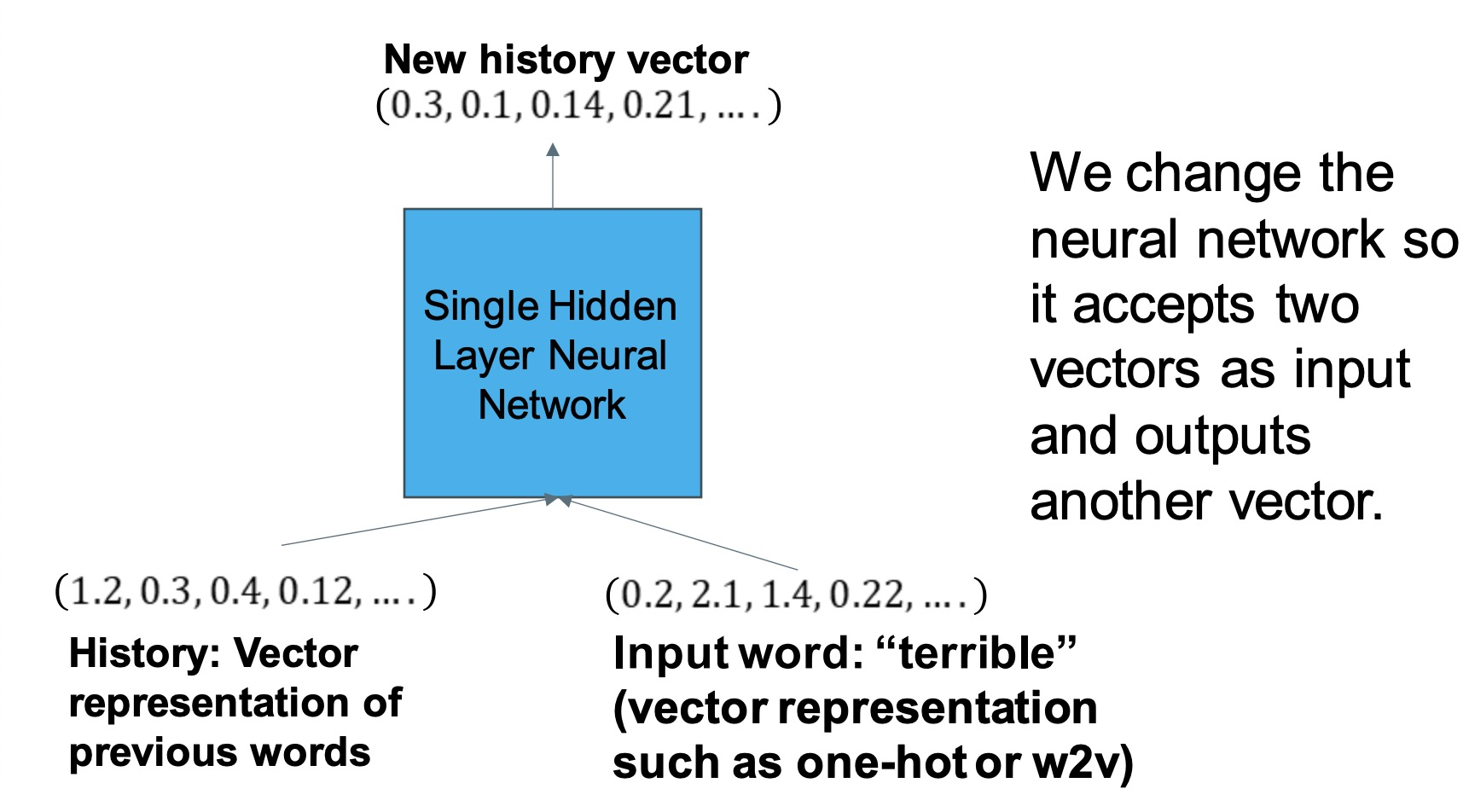
我们改变了神经网络,让其可以接受两个向量作为输入,并输出另外一个向量。
Recurrent Cell 递归单元
To accommodate two input vectors we use the following network: 为了适应两个输入向量,我们使用以下网络:
Recurrent Neural Network
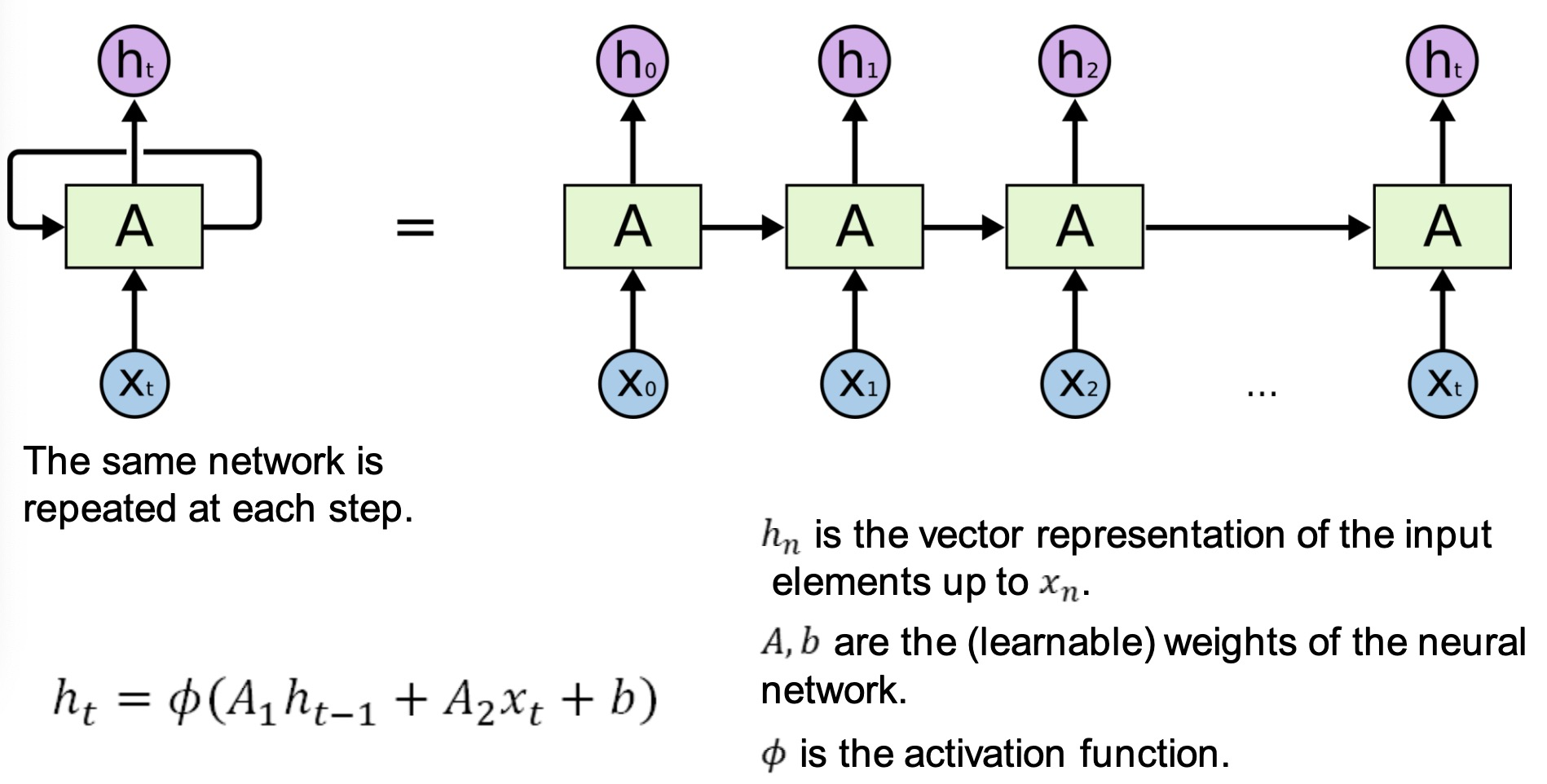
hn是直至输入向量xn的向量表示
A,b是可以训练学习得到的神经网络参数
RNN for Classification
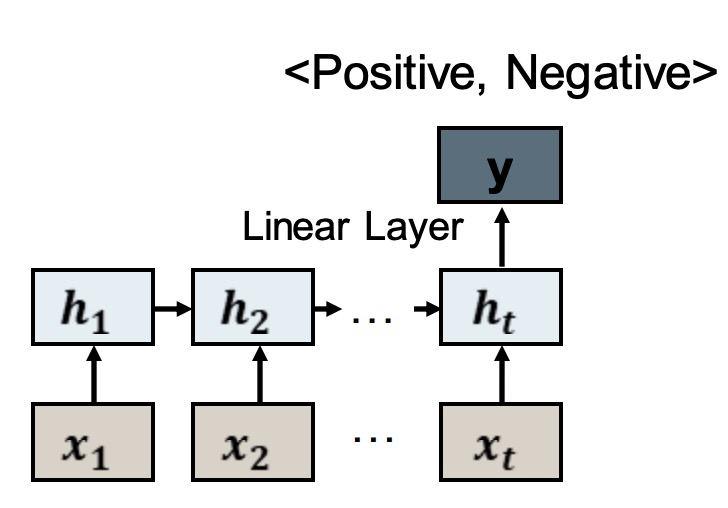
We don’t have to use the outputs at each step we can ignore them and use the last one 我们不必在每一步都使用输出,我们可以忽略它们,使用最后一步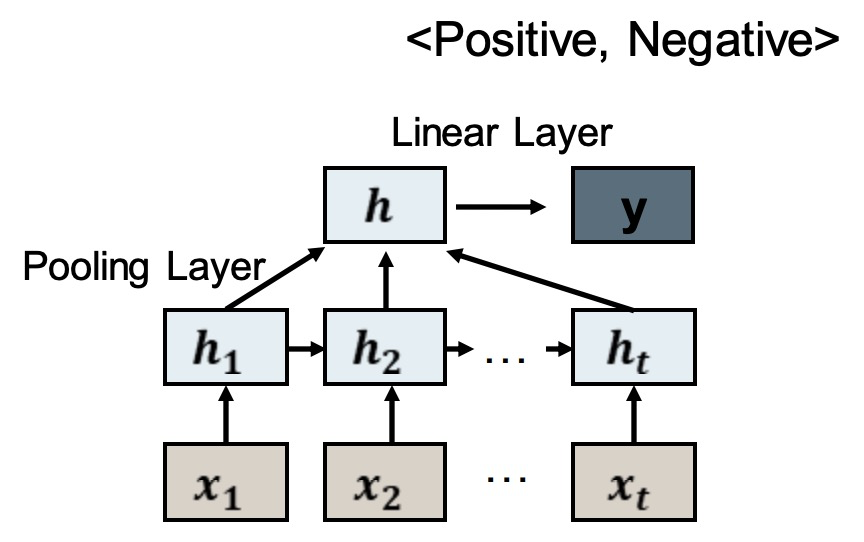
We could also use the outputs at each step and pool them using a function such as: sum, mean, max. 我们还可以使用每一步的输出,并使用一个函数(如:sum、mean、max)来汇集它们。
Backpropagation Through Time 反向传播
The loss is calculated using the output of the network. 使用网络的输出来计算损失函数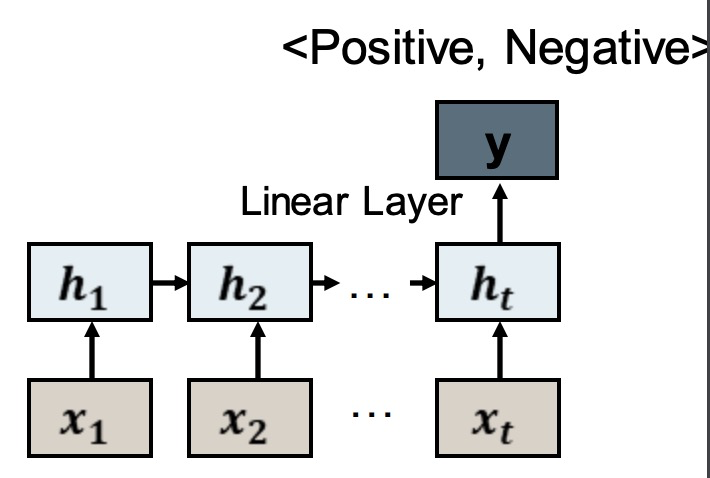
We backpropagate through the entire sequence to train the weights. 我们反推整个序列来训练权重。
Problems with the Simple RNN 简单RNN神经网络的问题
• We are using the same neural network at each step of the sequence. 我们在每一步处理序列的时候都是用简单的神经网络
• At each step the previous representation gets multiplied by the weight matrix . 每一步都要用权重矩阵乘以之前的表示
• Then the derivative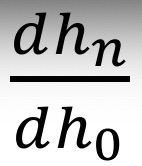 is proportional to
is proportional to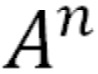 倒数和A的n次方成正比
倒数和A的n次方成正比
• If the weights in A are less than 1 then 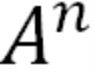 decays exponentially (vanishing gradients). 如果在A的权重比1小,那么A的n次方会指数衰减(梯度消失)
decays exponentially (vanishing gradients). 如果在A的权重比1小,那么A的n次方会指数衰减(梯度消失)
• If the weights in A are greater than 1 then 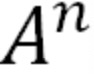 grows exponentially (exploding gradients). 如果在A的权重比1大,那么A的n次方会指数增长(梯度爆炸)
grows exponentially (exploding gradients). 如果在A的权重比1大,那么A的n次方会指数增长(梯度爆炸)
• This makes it very difficult for the RNN to learn representations of long sequences. 这使得RNN很难学习长序列的表示。
More Advanced Recurrent Modules 更多改良的递归模型
• Better architectures allow learning of longer temporal dependencies. 更好的架构允许学习更长的时间依赖性。
• They all make use of residual connections and gating mechanisms. 它们都利用残余连接和门控机制。
• Residual connections add the representation from the previous step to the output of the current step. 剩余连接将前一步的表示添加到当前步骤的输出中。
• Gates are vectors with elements in [0,1], they are multiplied with the output vectors. 门是元素在[0,1]中的向量,它们与输出向量相乘。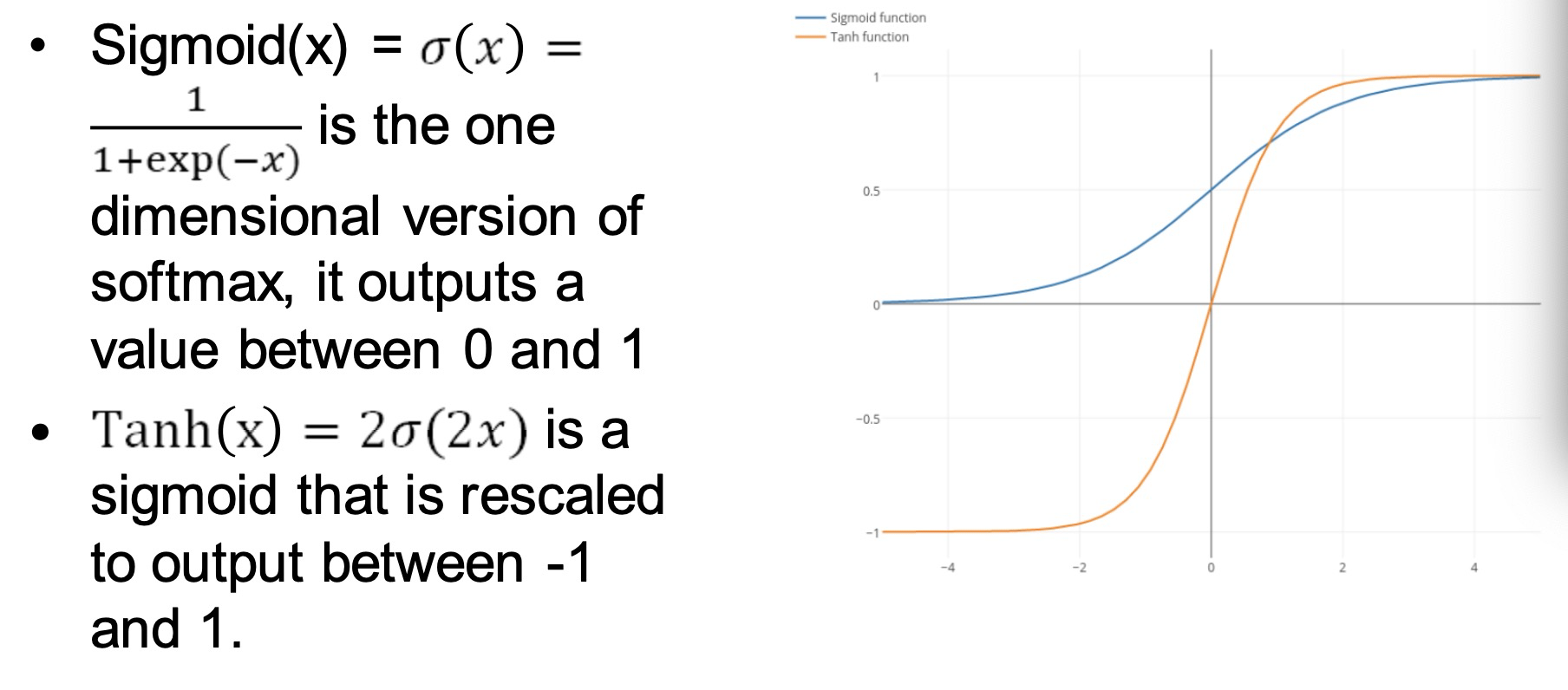
Gated Recurrent Unit (GRU) 递归门单元网络

Update gate: which parts of the history to update to new values. 更新门z: 将历史记录的哪些部分更新到新值。
Reset gate: which parts of the history to forget. 重置门r:决定那一部分历史记录需要被忘记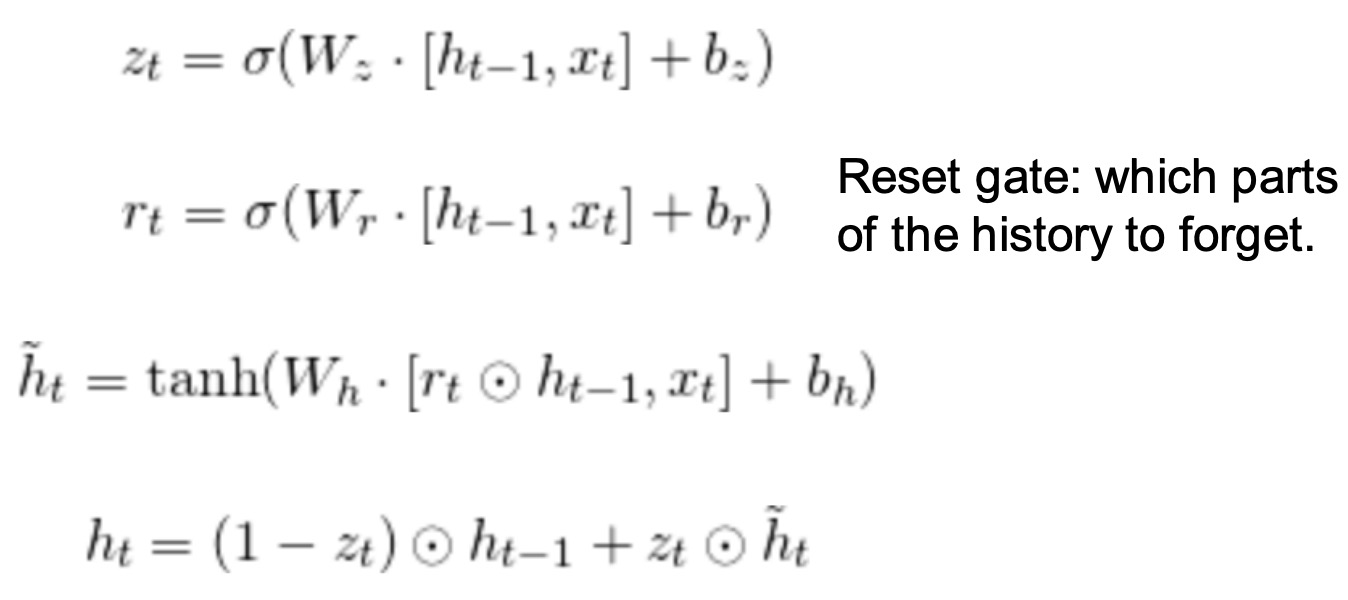
Candidate history: compute new history from input ignoring update gate for now ht~ 候选历史: 从输入忽略更新门暂时计算新历史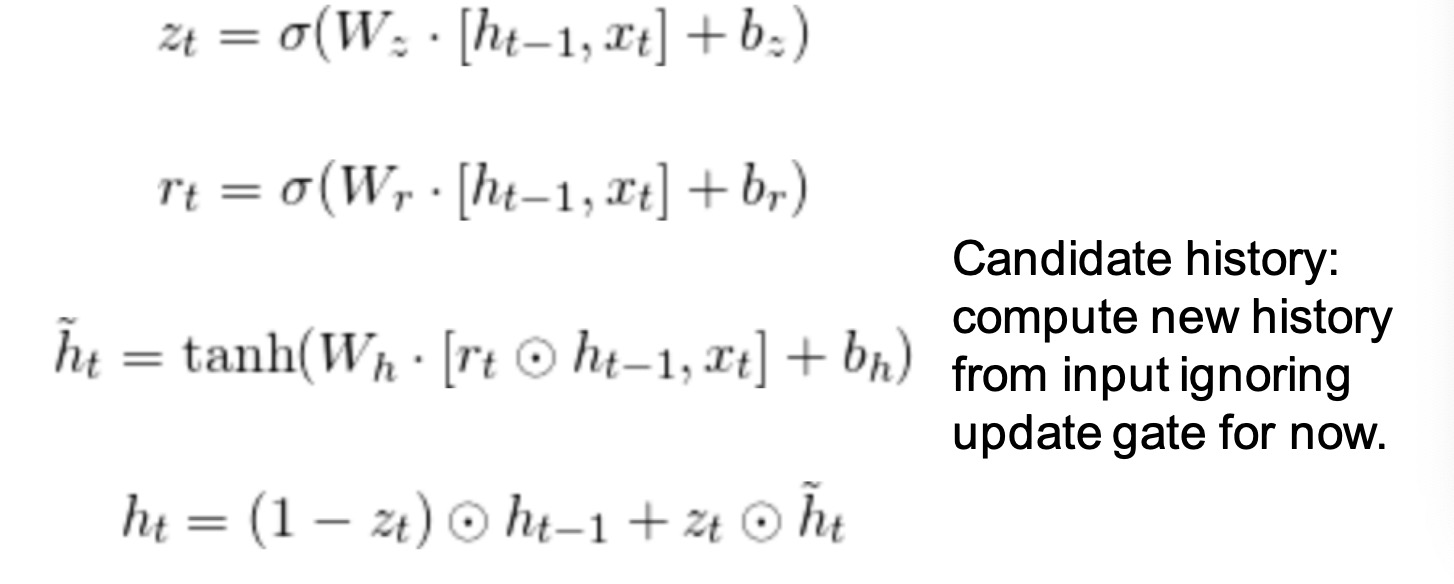
New history: Apply the update gate to calculate the new history. ht 新历史:应用更新门计算,得到新的历史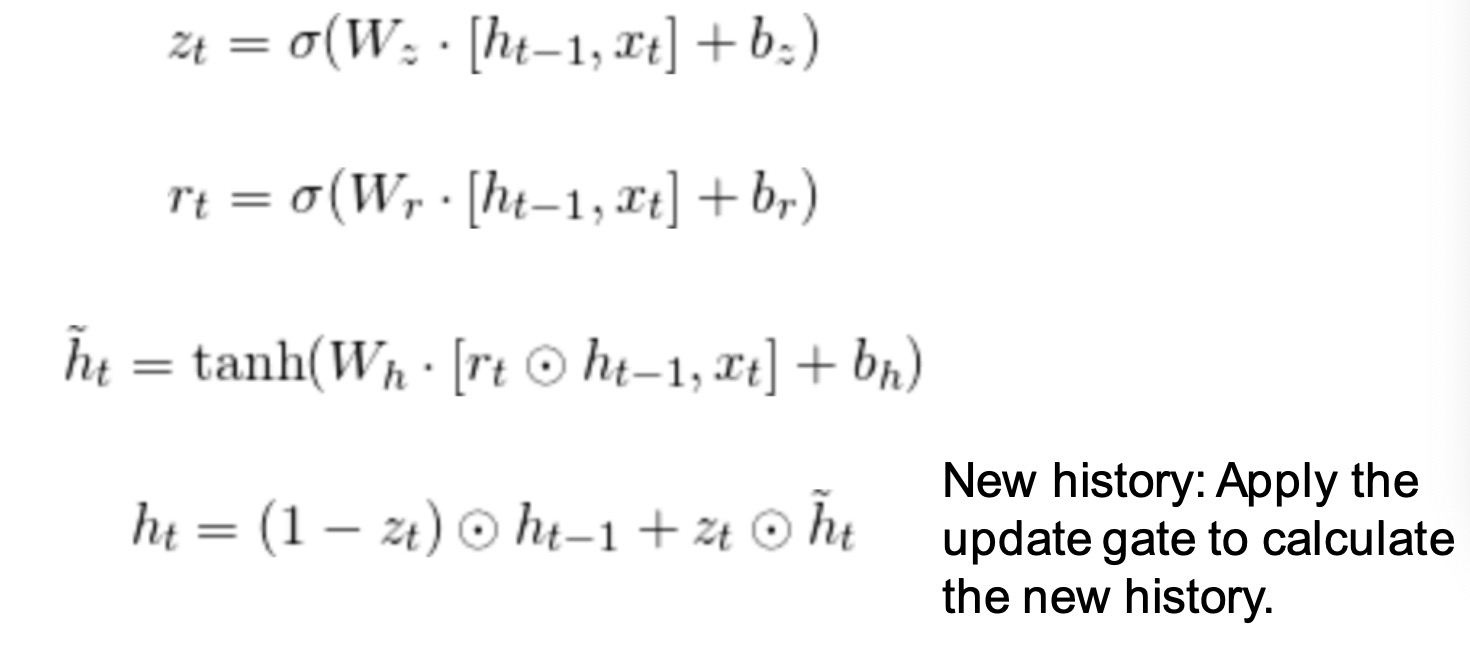
Long Short-Term Memory (LSTM)
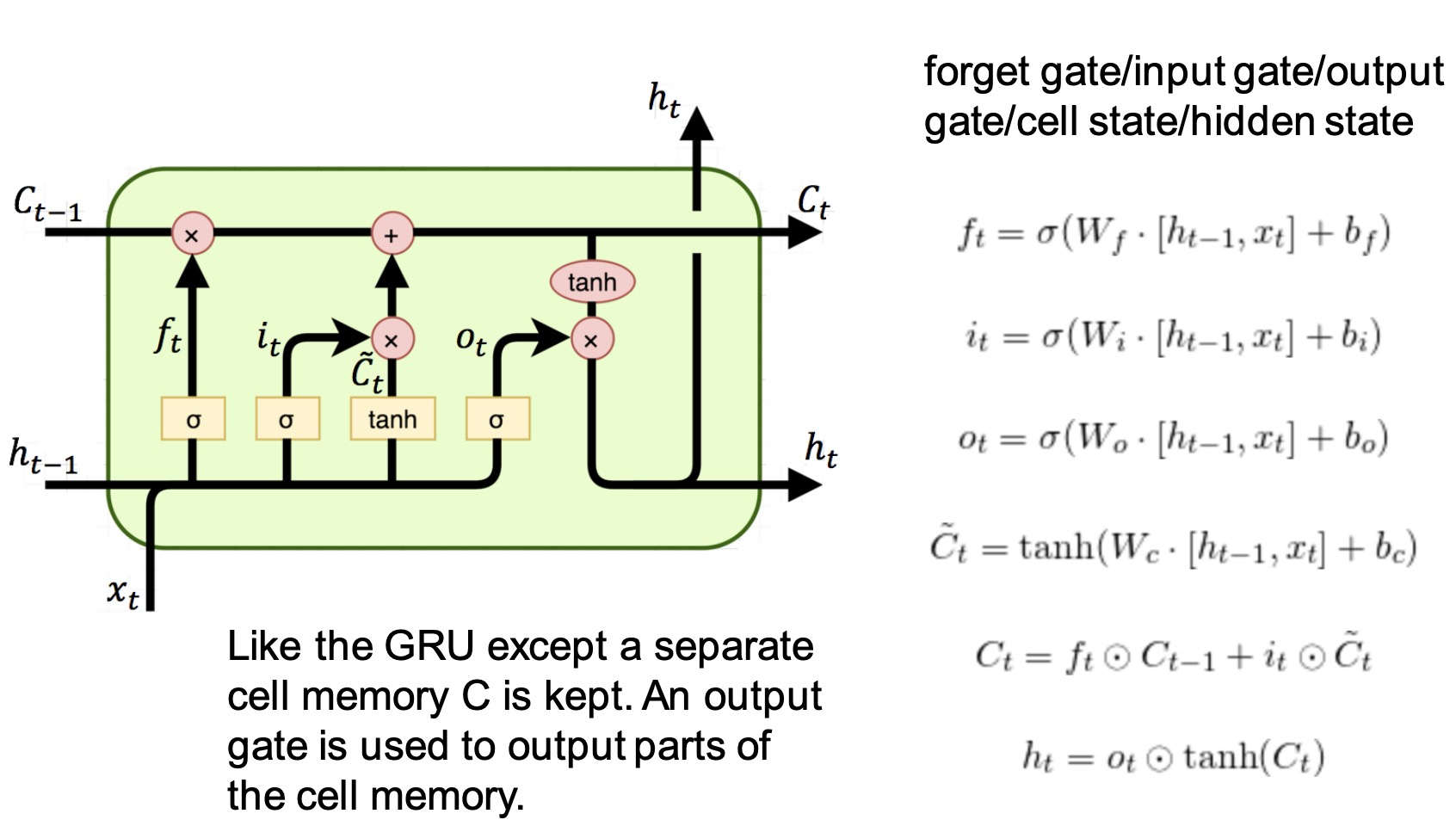
RNN and Terminology
• LSTM and GRU are both drop-in replacements for the Simple RNN. LSTM和GRU都是简单RNN的替代产品。
• The Simple RNN might also be called a Vanilla RNN or an Elman RNN. 简单的RNN也可以被称为香草RNN或埃尔曼RNN。
• RNN is a generic term for any of these types of models. RNN是这些类型模型的通称。
• RNN refers to the entire sequential structure, to refer to the network that is repeated we often use RNN Cell or RNN Unit RNN指的是整个序列结构,指的是我们经常使用的RNN细胞或RNN单位重复的网络
RNN for Language Modelling
The RNN takes the word generated in the last step as the input to the next step.
Multi-layer RNN
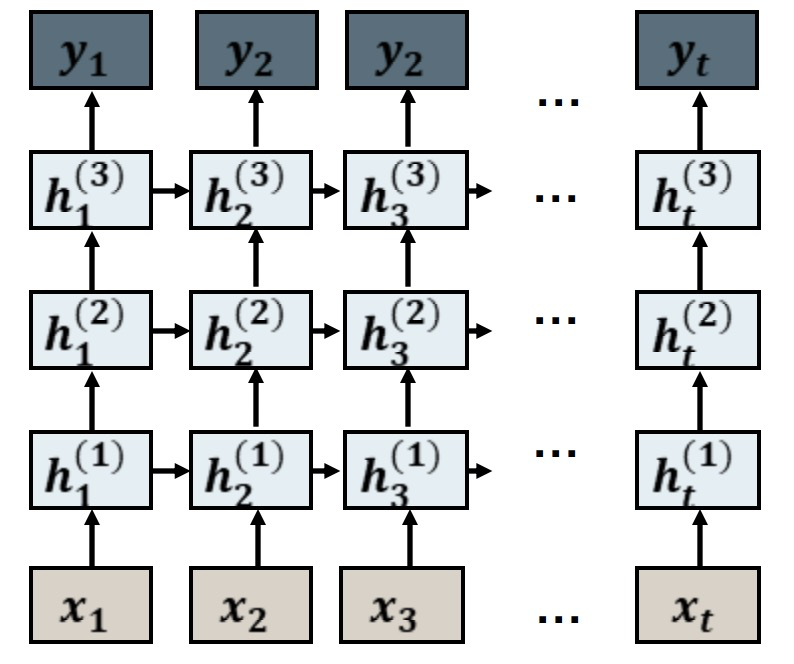
Bi-directional RNN

Padding
When training on sequential data, different elements in the batch can have different lengths. This means they can’t be concatenated into one tensor. 在顺序数据上训练时,批次中的不同元素可以有不同的长度。这意味着它们不能连接成一个张量。
• A work-around is to pad sequences with a special ‘pad’ token so that they all have the same length. 解决办法是用一个特殊的“填充”标记填充序列,使它们具有相同的长度。
Recursive neural network: Tree structure
Trees
• Tree structure 树结构
– Multiple children 多个分支
– Single parent 一个父节点
– No loops 没有循环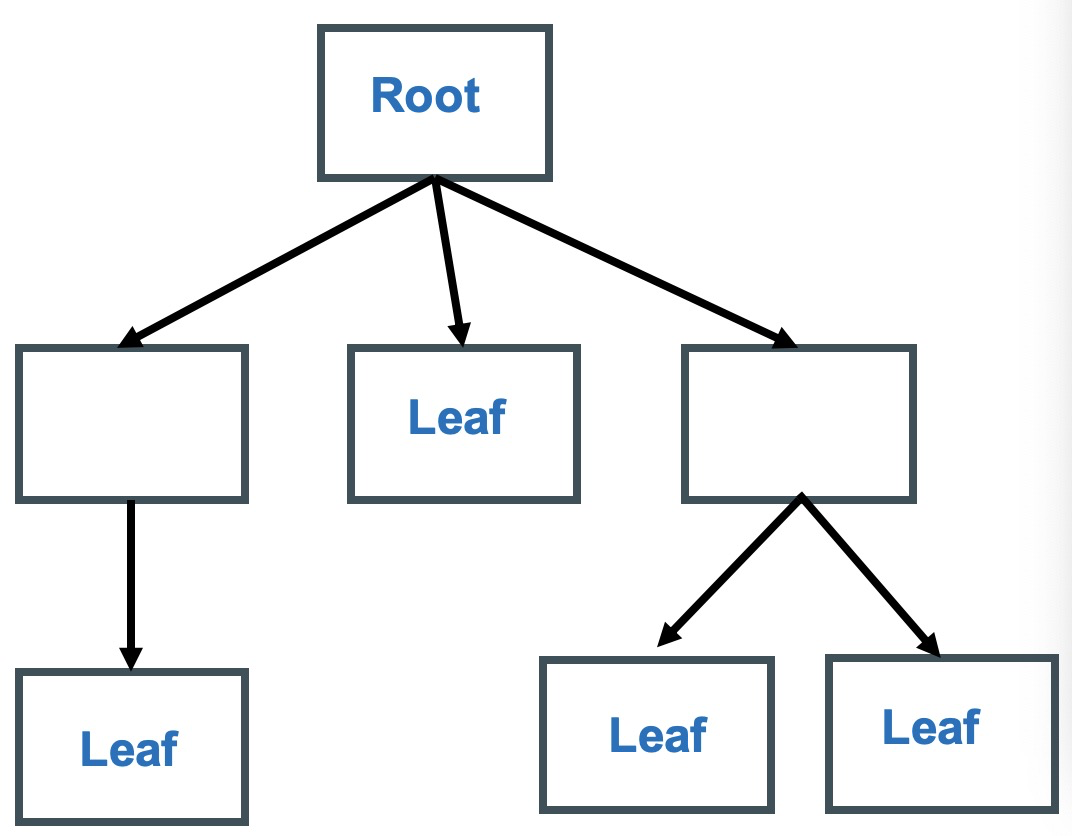
Syntactic Structure
Constituency parser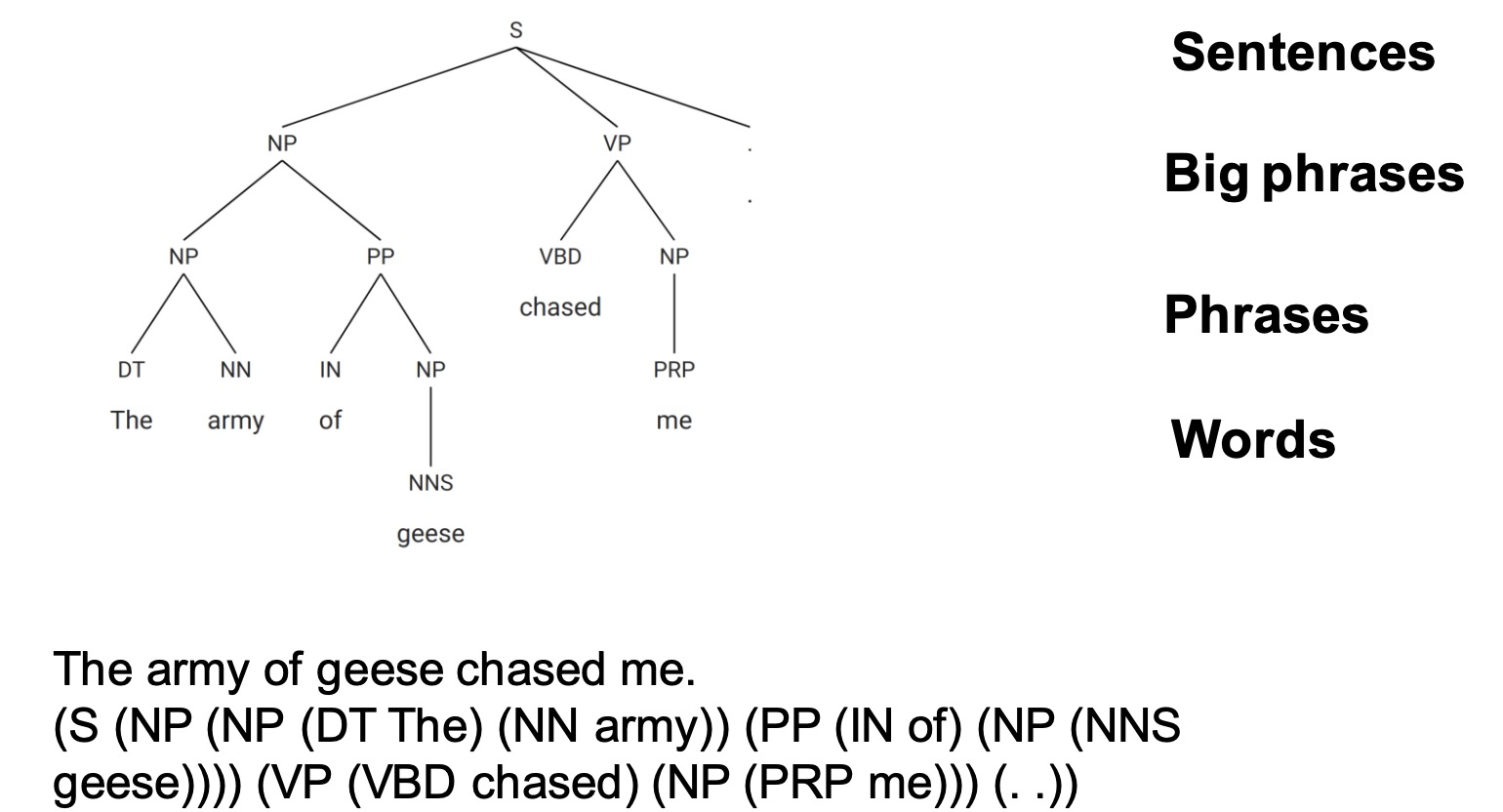
Recursive Neural Network
From recurrent to recursive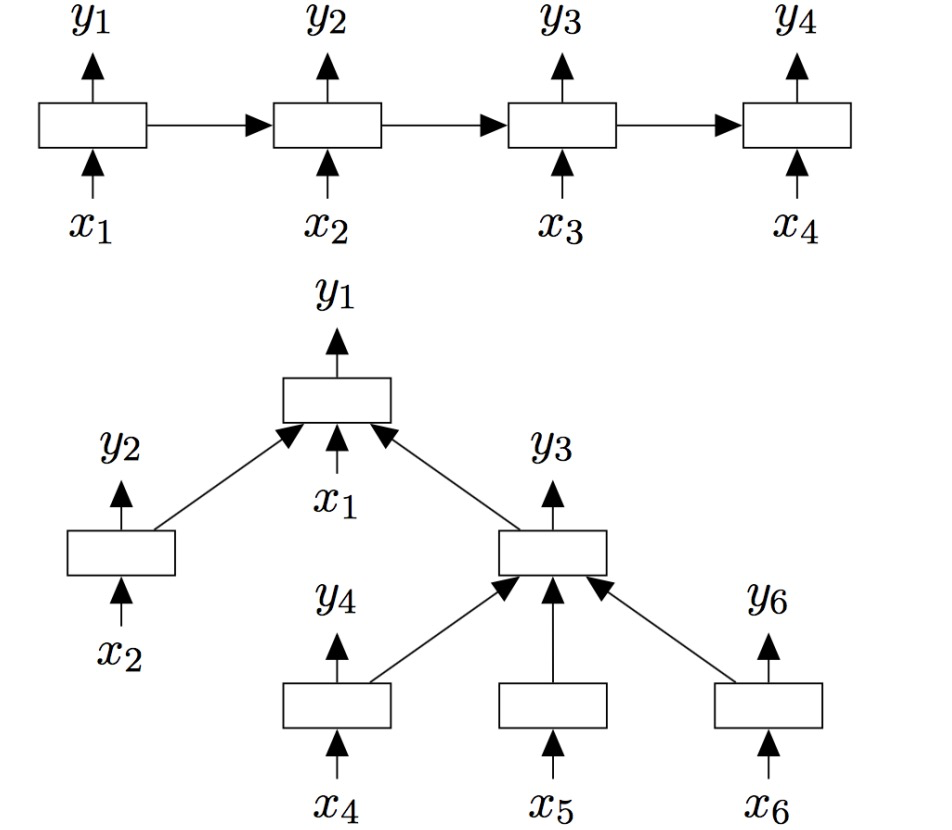
Child-Sum Tree-LSTM

Unknown Implicit Structure
Known structure:
– Sequential (List of words) 顺序(单词列表)
– Hierarchical (Syntactic Tree) –分层(语法树)
Unknown structure?
– We infer structure with attention 使用注意力机制推断
Summary
• Recurrent Neural Network 递归神经网络
– Repeat the same network at every step 每一步都重复相同的网络
– Takes history from previous step as input 将上一步的历史记录作为输入
– Train with backpropagation 通过反向传播进行培训
• Hierarchical Structure 分层结构
- Recursive Neural Network 递归神经网络
– Used for tree structured data 用于树形结构数据
– The Child-Sum Tree-LSTM is similar to the LSTM 子树-总和树-LSTM类似于LSTM

若有收获,就点个赞吧
0 人点赞
