Evaluation
• We want to know how good our model is at making predictions for new data points. 我们想知道我们的模型对预测新的数据点效果如何
• We can use the loss to measure how well predictions match targets. 可以通过损失函数来衡量预测对目标的匹配程度
• But even if the loss is low we can’t be sure that it will work on new data. 即使损失函数很低,但是我们仍然很难确定模型是否可以在新的数据集上工作
– It could just be memorizing the training data. 模型可能只是记住了训练集数据
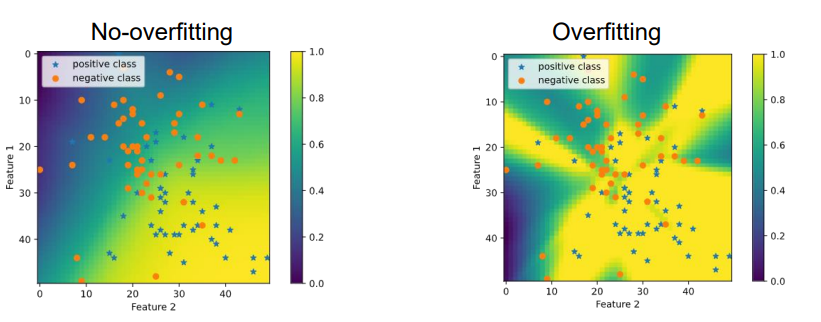
Note: we can’t know if a model has overfit just by looking at the training data or decision boundaries, we must consider performance on a new data. 我们不能仅仅通过观察训练数据或决策边界就知道一个模型是否过度,我们必须考虑新数据的性能。
In the above the data is synthetic and generated from gaussian blobs so we can say that the figure on the right has overfit. 在上图中,数据是合成的,是由高斯斑点生成的,所以我们可以说右边的图是过拟合的。
Data Splitting 数据分割
We typically split the data into three mutually exclusive sets. 我们通常将数据分成三个互斥的集合。
Data points are often randomly assigned 数据点通常是随机分配的
Typical split ratio is: 70:10:20 传统的分割比例是 7:1:2
Random Assignment 随机分配
Data points are often randomly assigned to train, val, test, but you might want to: 数据点通常随机分配给训练、val、测试,但您可能希望:
• Split by time (e.g. if publication labels are available) 按照时间分割
• Split by Document (e.g. if classifying sentences) 按照文档分割
• Stratify by Class (keep class ratios the same between splits) 按照类别进行分割
Testing data 测试数据集
• It is crucial that we reserve some of our data for evaluation – called the test set. 我们需要保留一些数据用于评估模型-称作测试集
• The model is not trained on test set. 模型没有在测试集上训练过。
• After training is finished, the model’s performance on the test set will give us a good idea of how well it can handle new data. 训练结束后,模型在测试集上的表现让我们更好的了解他处理新数据的能力(泛化能力)
Validation data 验证数据
• Often, we want to compare different models to choose the best one. We want to compare their performance on unseen data. 通常,我们希望比较不同的模型来选择最佳模型。我们想比较他们在看不见的数据上的表现。
• But if we choose the model with the best performance on the test set, then its test set performance is no longer a good indication of its performance on new data 如果我们选择测试集性能最好的模型,那么它的测试集性能就不再是它在新数据上性能的良好指标
Train, Val, Test data
• It is common to split data into 3 parts 通常把数据集分为三个部分
• Training set is used to train models 训练集用于训练模型
• Validation set is used to compare models during development 验证集用于比较模型
• Testing set is used to evaluate models. 测试集用于评估模型
Alternatives to Fixed Data Splits
If limited data and/or model is fast to train and evaluate: K-fold cross validation is a better solution. (rarely used for deep learning) 如果有限的数据和/或模型训练和评估很快:K倍交叉验证是更好的解决方案。(很少用于深度学习)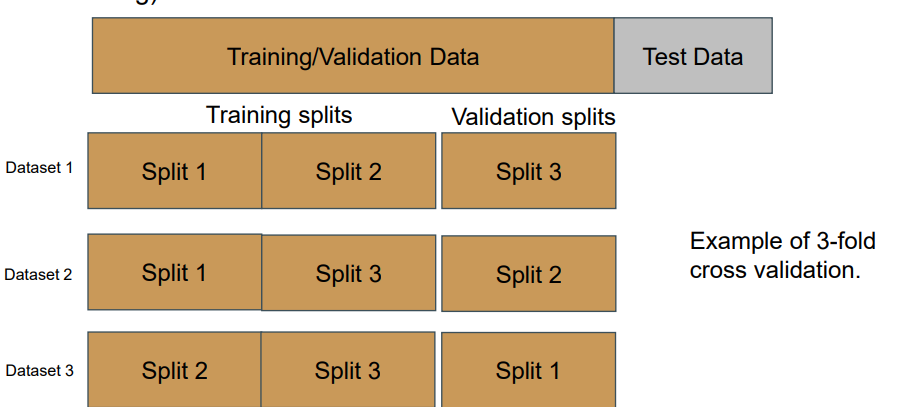
Epochs 迭代次数
Usually, neural networks are trained on batches. 通常,神经网络是分批训练的。
Batches are sampled without replacement from the training data. When the training data is empty, all points are added back in and the process is repeated. 批次的采样不需要替换训练数据。当训练数据为空时,所有的点都被加回来,并重复该过程。
Each iteration through the dataset is called one epoch of training. 数据集的每次迭代称为一个训练时期。
Standardizing
Standardizing Features 特征标准化
Many models perform badly if the features are not approximately normal with mean 0. 如果特征不是平均值为0的近似正态,许多模型的性能会很差
We typically try to make this true: 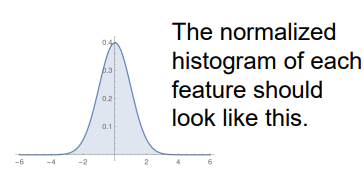
- subtract the mean of each feature 减去每一个特征的平均值
- divide by the standard deviation of each feature 除以每个特征的标准差
Sometimes you might also do a log transform if your data is very skewed. 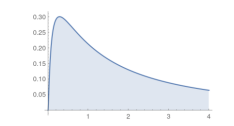 如果你的数据很不好,有时候需要做对数转换。
如果你的数据很不好,有时候需要做对数转换。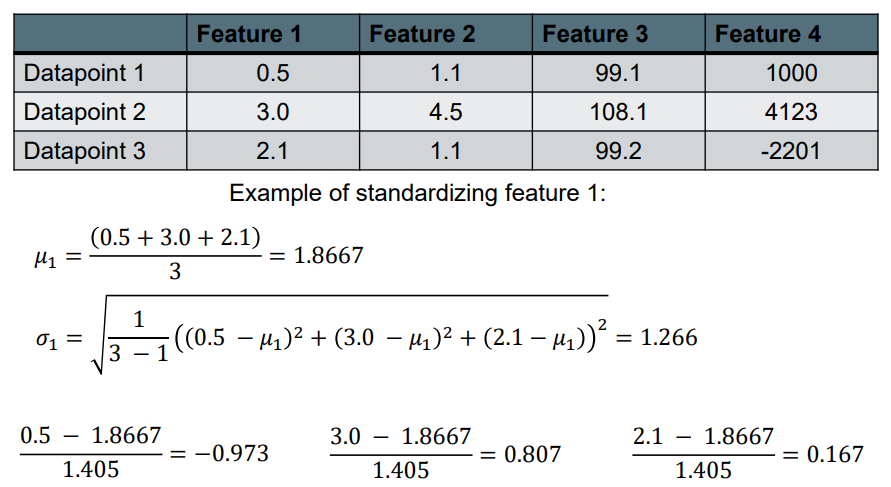
Standardizing Output Values 标准化输出值
For regression tasks: 对于回归任务
We also often want the output to be well behaved (homoscedastic). Possible transforms: 我们也经常希望输出表现良好(同质化)。可能的转换
• Log transform 对数转换
• Power transform
• Box-Cox transformations
Why Standardize?
Can improve performance significantly. 可以显著的优化性能
Ensures each feature has similar effect on the loss. 可以确认每个特征对损失函数的影响是相近的
Makes regularization techniques applied to all parameters equally a reasonable approach. 使正则化技术同样适用于所有参数是一种合理的方法。
Standardizing Sparse Vectors 稀疏向量的标准化
We can’t subtract the mean: 我们不能减去平均值:
• If the mean is non-zero it would make most vectors non-sparse 如果平均值不为零,将使大多数向量不稀疏
Alternatives: 备选方案:
• Just divide by the standard deviation 除以标准偏差即可
• Just divide by another value e.g. tf max normalization 只需除以另一个值,例如tf max归一化
Regularization 正则化
We want our model to generalize well to examples it was not trained on. 我们希望我们的模型能很好地推广到没有经过训练的例子。
Occam’s razor: the simplest explanation is usually the best one. 奥卡姆剃刀原理:最简单的解释通常是最好的解释
The simplest model that fits the data is usually the one that generalizes best 最简单的模型往往泛化性能最好
Bias Variance Trade-off 偏差差异权衡
There is a trade-off between fitting the training data well and having a simple model. 在简单的模型和拟合数据集之间做权衡。
Overfitting 过拟合
When a model gets so good at fitting the training data that its performance on the test data suffers. 当一个模型非常善于拟合训练数据,以至于它在测试数据上的表现受到影响。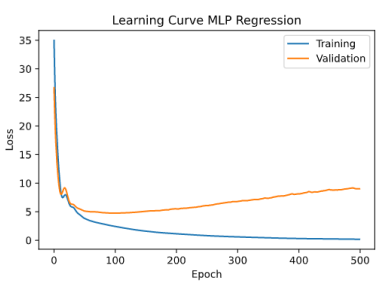
Types of Regularization 正则化类型
Explicitly constrain parameters as part of the loss function: 将参数明确约束为损失函数的一部分: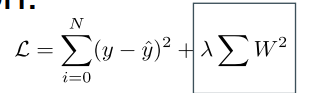
Implicitly:
• SGD
• Early stopping
• Batch normalization
• Layer normalization
• Dropout
Loss Function Regularization
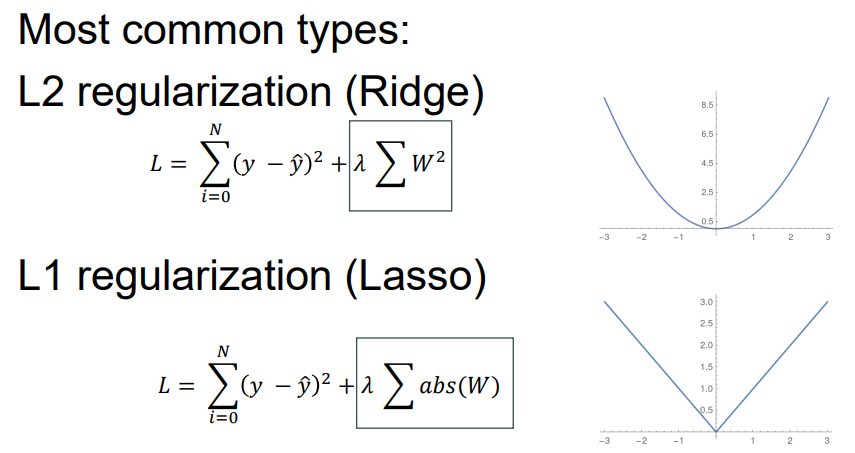
Typically encourages all the parameters to be closer to 0. (normally don’t regularize bias) 通常会促使所有参数接近0。(通常不规范偏见)
- Limits the space of reasonable parameters 限制合理参数的空间
- Makes linear models have a shallower slope (encodes the prior belief that there is no trend) 使线性模型具有较浅的斜率(编码没有趋势的先验信念)
- Leads to sparser models where unimportant features are ignored (L1) 导致忽略不重要特征的稀疏模型(L1)
Early stopping 过早的停止训练
• In order to know how long to train model for, after each epoch evaluate model on held-out validation set. 为了知道训练模型需要多长时间,在每个epoch之后,在持续验证集上评估模型。
• If validation performance does not increase, then stop training. 如果验证性能没有提高,则停止培训。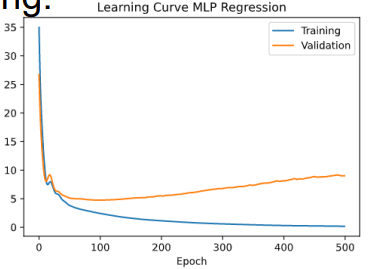
Regularization 正则化
Regularization is very important 正则化很重要
More important when you have many parameters and/or a small amount of training data. 当参数多、数据集少的时候,正则化就更重要了。
You might use multiple types of regularization to get the desired effect 可以使用多种正则化类型来得到想要的效果
Hyper-parameter tuning 超参数调节
Neural Networks have many hyper-parameters 神经网络有很多超参数
– Architecture (number of neurons and layers) 架构参数(神经元、层数)
– Learning rate 学习率
– Regularization parameters 正则化参数
How do you choose good settings?
Grid search 网格搜索
• Specify possible options for each hyper-parameter. 为每个超参数设置可能的数值
– e.g. learning rate: [0.001, 0.01, 0.1, 1], number of neurons: [10, 50, 100, 200] 例如学习率:[0.001,0.01,0.1,1],神经元数量:[10,50,100,200]
• Then train a neural network for every possible combination of settings, and pick the best one. 然后为每种可能的设置组合训练一个神经网络,并选择最佳的一个。
• Can take a very long time! 可能需要很长时间
Usually it is good enough to select hyper parameters one at a time 通常一次选择一个超级参数就足够了
– Initialize hyper parameters to some reasonable defaults. 将超级参数初始化为一些合理的默认值。
– Then select one of them and tweak it to be optimal with all others held constant. 然后选择其中一个,并在所有其他参数保持不变的情况下将其调整到最佳状态。
– Then optimize the next hyper parameter, and so on. 然后优化下一个超级参数,以此类推。
Random Search 随机搜索
Often it is more efficient to randomly search the space of hyper parameters. 通常,随机搜索超参数空间更有效。
1. Select a random set of hyperparameters within the grid 在网格中选择一组随机的超参数
2. Evaluate the model 评估模型
3. If the computation budget is not exhausted goto step 1 如果计算预算没有用完,转到步骤1
Bayesian Hyperparameter Optimization 贝叶斯超参数优化
Each point is an evaluation of the model with different hyperparameter x . The y axis is the loss. 每个点都是具有不同超参数的模型的评估。x轴是超参数,y轴是损失。
We can guide the search to try hyperparameters that have a greater probability of being good. 我们可以引导搜索尝试更有可能是好的超参数。
Hyperparameters Practical Advice
• If your method is fast to train or you have a lot of compute resources, then use one of the methods presented here. 如果您的方法训练速度很快,或者您有大量的计算资源,请使用这里介绍的方法之一。
• Otherwise, it is better to guide the search by tuning a single parameter at a time and using intuition about the problem. 否则,最好通过一次调整一个参数并利用对问题的直觉来指导搜索。
• The best parameter(s) to start tuning is (are) typically the regularization parameter(s) and learning rate. 开始调整的最佳参数通常是正则化参数和学习速率。
• Generally, for deep learning you should make your model as large as possible given your training and test constraints and then use regularization to prevent overfitting. 一般来说,对于深度学习,在给定训练和测试约束的情况下,您应该使模型尽可能大,然后使用正则化来防止过度拟合。
Optimizers
• Several improvements can be made to the basic stochastic gradient descent optimization algorithm. 可以对基本的随机梯度下降优化算法进行一些改进。
• Currently the 2 most popular optimizers are SGD+momentum and Adam.目前最受欢迎的两个优化器是SGD+动量和Adam。
SGD with Momentum 具有动量的SGD
Momentum helps traverse gullys quicker. 动量有助于更快地穿过低谷。
This can drastically reduce the number of steps needed for training. 可以减少训练所需要的步骤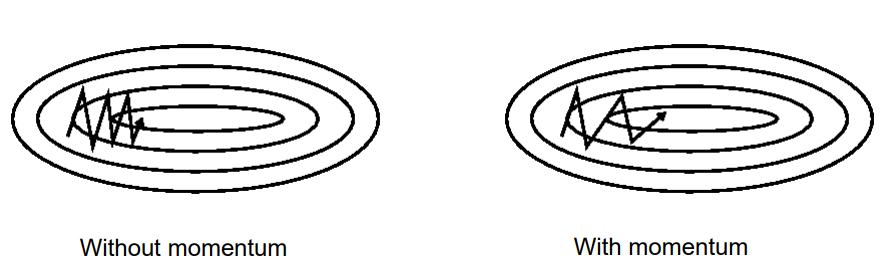
SGD+momentum
Momentum is a running average of gradients from previous batches. 动量是先前批次梯度的运行平均值。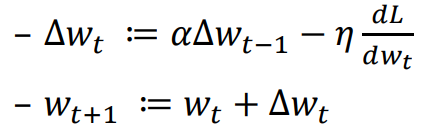
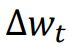 is a weighted combination of the previous change and current derivative. Initialized to 0. 是先前变化和当前导数的加权组合。初始为0。
is a weighted combination of the previous change and current derivative. Initialized to 0. 是先前变化和当前导数的加权组合。初始为0。
𝛼 is a value between 0 and 1, called the momentum coefficient typically around 0.9. 𝜂 is the learning rate. 𝛼 是0到1之间的数值, 叫做动量系数,通常约为0.9。 𝜂为学习率。
Adam (Adaptive Moment Estimation) Adam自适应矩估计
• Adam keeps a running average of gradients and variances of gradients and uses them to normalize changes. Adam保持梯度和梯度方差的运行平均值,并使用它们来标准化变化。
• Adam is less sensitive to the learning rate that SGD+momentum. Adam相较于SGD+动量对学习速率不太敏感。
• In practice Adam often converges in fewer iterations than SGD+momentum. Though this is not always the case. 实际上,Adam的迭代次数通常比SGD+动量少。尽管情况并非总是如此。
Learning rate schedules 学习进度计划
• Change the learning rate throughout training. 在整个培训过程中改变学习速度。
• Exponentially decaying schedule multiplies learning rate by some 0 < 𝜆 < 1 after every step. 指数衰减的时间表在每一步后将学习率乘以0 < 𝜆 < 1。
• Allows for larger learning rate to be used initially, while still converging. 允许最初使用更大的学习速率,同时仍能收敛。
Deep Neural Networks: Why now?
There are several reasons why deep networks have become feasible in the last 10 years: 深度网络在过去10年变得可行有几个原因:
• Enthusiasm from the research community 来自研究团体的热情
• More and better data available 更多更好的可用数据
• Increase in Compute (including GPU compute) 计算能力的提高(包括图形处理器计算)
• Autograd libraries (Theano, TensorFlow, torch) 亲笔签名的图书馆(茶座、天束、火炬)
• ReLU is easier to train ReLU更容易训练
• Better layer initialization 更好的层初始化
• Better methods for regularization (eg dropout) 更好的正规化方法(如辍学)

若有收获,就点个赞吧
0 人点赞
