Multivariate data 多元数据 refers to a data set involving two or more attributes or variables (the usual case!).
This is addressed by transforming the multivariate outlier detection task into a univariate outlier detection problem. 这是通过将多变量异常检测任务转换成单变量异常检测问题来解决的。
Method 1. Compute Mahalaobis distance
Let ō be the mean vector for a multivariate data set. Let S be the covariance matrix协方差矩阵.
Mahalaobis distance for an object o to ō is defined as 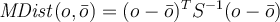
where 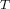 and
and 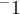 are the operators for matrix transpose and inverse respectively.
are the operators for matrix transpose and inverse respectively.
Using this transformation, we now have a univariate data set 
Then use the Grubb’s test on this univariate data set to identify outliers.
Method 2. Use χ2 –statistic
**
This method assumes a normal distribution.
For each 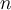 dimensional object
dimensional object 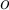 with dimension values
with dimension values 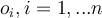 , calculate
, calculate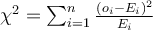
where 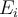 is the mean of the i-dimension among all objects.
is the mean of the i-dimension among all objects.
If this χ2 –statistic is large for 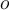 , then
, then 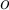 is an outlier.
is an outlier.

若有收获,就点个赞吧
0 人点赞
