Motivation
• Automatic classification for the large number of on-line text documents 大量在线文本文档的自动分类
(Web pages, e-mails, corporate intranet documents, etc.)
Classification process 分类过程
• Data pre-processing 数据预处理
• Definition of training set and test sets 定义训练集和测试集
• Creation of the classification model using the selected classification algorithm 用选择的分类算法训练模型
• Classification model validation 评估分类模型
• Classification of new/unknown text documents 用来预测新的文本对象
Text document classification differs from the classification of relational data 文本文档分类不同于关系数据的分类
• Document databases are not structured according to attribute-value pairs 文档数据库不是根据属性值对构建的
**
Class labels (categories) may be developed by hand
- Pre-given classes (categories) and labeled documents (examples)
- Categories may form hierarchy/taxonomy
- Classify new documents
- A standard classification (supervised learning) problem
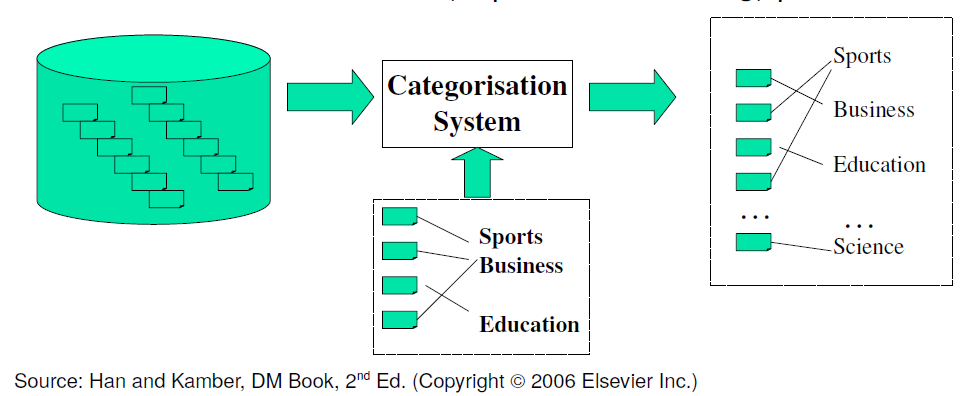
Classification algorithms that are used:
- Support vector machines
- K-nearest neighbors
- Naïve Bayes
- Neural networks
- Decision trees
- Association rule-based
- Boosting
- more..
Here are some methods from the literature used for such classification.
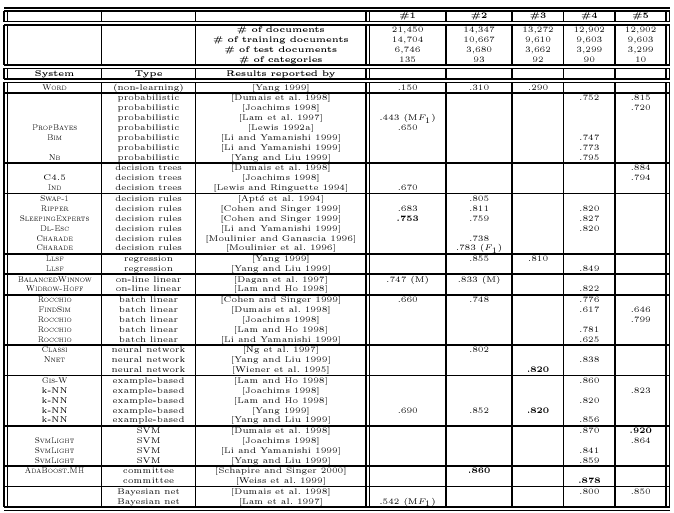

若有收获,就点个赞吧
0 人点赞
