Outlier:离群值
- A data object that deviates significantly from the normal objects as if it were generated by a different mechanism. 数据对象明显偏离正常对象,好像它是由不同的机制生成的。
- Example Unusual credit card purchase, Sports stars, Tax frauds
- Outliers are different from noise data: Noise is random error or variance in a measured variable 异常值不同于噪声数据:噪声是测量变量中的随机误差或方差
- Noise should be removed before outlier detection 在检测异常值之前,应去除噪声
- Outliers are interesting: They violate the mechanism that generates the normal data
- Outlier detection vs. novelty detection: early stage is an outlier; but later could be novelty and then merged into the model
Applications:
Credit card fraud detection - fraudulent transactions
Telecom fraud detection -stolen phones
Customer segmentation
Medical research
Students at risk of failing -> novelty detection?
National security
Network intrusion detection
Types: Global, Contextual or Collective 全局、上下文或集体
- A data set may have multiple types of outlier.
- One object may belong to more than one type of outlier.
Global outlier (or point anomaly)
- Object is O if it significantly deviates from the rest of the data set
- e.g. Intrusion detection in computer networks
- Issue: Find an appropriate measurement of deviation
- 全局异常值(或点异常) 对象是Og,
- 如果它明显偏离数据集的其余部分 例如,计算机网络中的入侵检测
- 问题:找到合适的偏差测量方法
Contextual outlier (or conditional outlier)
- Object is O if it deviates significantly based on a selected context 如果对象基于选定的上下文发生显著偏离
- e.g. 0 C in Canberra outlier? (depends if it is summer or winter)
- Attributes of data objects should be divided into two groups
- Contextual attributes: defines the context, e.g., time & location 上下文属性:定义上下文,例如时间和位置
- Behavioral attributes: characteristics of the object, used in outlier evaluation, e.g., temperature 行为属性:用于异常值评估的对象特征,如温度
- Can be viewed as a generalization of local outliers—whose density significantly deviates from its local area 可视为局部异常值的概括——其密度明显偏离其局部区域
- Issue: How to define or formulate meaningful context?
Collective outliers 集体离群值
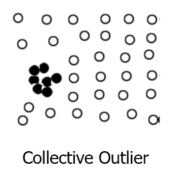
- A subset of data objects _colle_ctively deviate significantly from the whole data set, even if the individual data objects may not be outliers 数据对象的子集总体上明显偏离整个数据集,即使单个数据对象可能不是异常值
- Applications: e.g., intrusion detection: When a number of computers keep sending denial-of-service packets to each other. 数据对象的子集总体上明显偏离整个数据集,即使单个数据对象可能不是异常值
- Detection of collective outliers
- Consider not only behaviour of individual objects, but also that of groups of objects 不仅要考虑单个物体的行为,还要考虑一组物体的行为
- Need to have the background knowledge on the relationship among data objects, such as a distance or similarity measure on objects.需要了解数据对象之间关系的背景知识,例如对象的距离或相似性度量。
Challenges in Outlier Detection
- Modeling normal objects and outliers properly
- Hard to enumerate all possible normal behaviours in an application 很难列举应用程序中所有可能的正常行为
- The border between normal and outlier objects is often a grey area 正常和异常对象之间的边界通常是灰色区域
- Can assign a data object into class “normal” vs “outlier” , or assign an “outlier-ness” measure 可以将数据对象分为“正常”和“异常”两类,或者指定“异常”
- Application-specific outlier detection
- Choice of distance measure among objects and the model of relationship among objects are often application-dependent 对象之间距离度量的选择和对象之间关系的模型通常取决于应用
- e.g., clinical data: a small deviation could be an outlier; while in marketing analysis, larger fluctuations are expected
- Applications associate different costs with detecting or missing an outlier.
- Difficult to develop generic, application independent outlier detection methods 难以开发通用的、独立于应用的异常值检测方法
- Handling noise in outlier detection
- Noise may distort the normal objects and blur the distinction between normal objects and outliers. It may help outliers to hide and reduce the effectiveness of outlier detection
- 噪声可能会扭曲正常对象,模糊正常对象和异常值之间的区别。这可能有助于离群点的隐藏和降低离群点检测的有效性
- Understandability
- Understand why these are outliers: Justification of the detection
- Specify the degree of an outlier: the unlikelihood of the object being generated by a normal mechanism
One of the really challenging problems in outlier detection is turning the human perception of “I know one when I see it” into an objective algorithm that knows one when it sees it. Unlike other mining problems, there are very few accepted objective quality measures of outlier-detection. Generally, the best we can do is to assume that an outlier is a good one if it ranks most highly compared to other potential outliers in the same data set, according to the measure we use to define outliers. If, subjectively, we don’t like what we see, we try a different method or a different measure.

若有收获,就点个赞吧
0 人点赞
