Step 1: Training phase or learning step: Build a model from the labelled training set.
Each tuple/sample/record/object/example/instance/feature vector of the training dataset is assumed to belong to a predefined class, as determined by the class label attribute. Ideally, the tuples are a random sample from the full population of data.
- The set of tuples used for model construction is the training set:
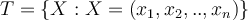 and each
and each 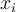 is an attribute value and
is an attribute value and 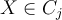 for some
for some 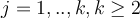 and
and 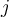 is the class label for
is the class label for 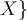 .
.
- Commonly, each
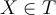 is assumed to belong to exactly one class
is assumed to belong to exactly one class 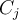
- In the very common special case of exactly 2 classes, i.e. binary learning, the training classes are called the positive examples
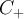 or P and negative examples
or P and negative examples 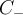 or N.
or N. - The model is represented as classification rules, decision trees, mathematical formulae, or a “black box”. The model can be viewed as a function
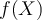 that can predict the class label for some unlabelled tuple
that can predict the class label for some unlabelled tuple 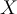 .
. - For classification models, the built model may be called a classifier.
Step 2: Use the model to classify unseen objects
- Need to estimate the accuracy of the model
- The known labels of a set of independent test samples is compared with the classified results for those same samples from the model
- Accuracy is the proportion of test set samples that are correctly classified by the model
- If the accuracy and all other evaluation measures are acceptable, apply the model to classify data objects whose class labels are not known in the world.
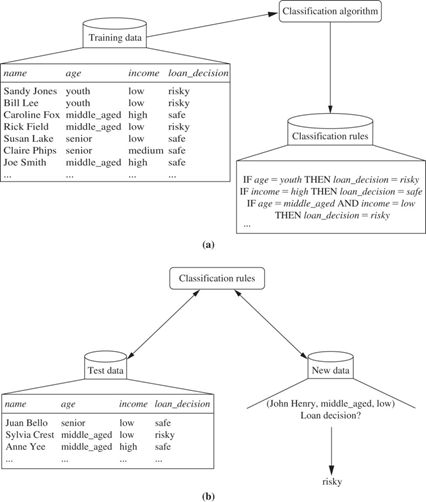
Example:
The data classification process:
(a) Learning: Training data is analysed by a classification algorithm. Here, the class label attribute is loan_decision, and the learned model or classifier is represented in the form of classification rules.
(b) Classification: Test data are used to estimate the accuracy of the classification rules. If the accuracy is considered acceptable, the rules can be applied to the classification of new, unlabelled, data tuples.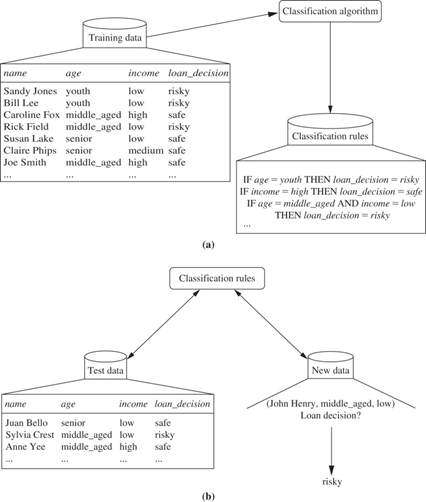

若有收获,就点个赞吧
0 人点赞
