If we have a labelled training set of outliers and non-outliers, then classification methods can be used. 如果我们把离群点和非离群点打上标签,那么分类器方法就可以被使用。
However, the training set would typically be heavily biased in favour of non-outlying data, so classification has to be sensitive to this asymmetry of classes. 然而,训练集通常会严重偏向于非离群点数据,因此分类必须对类的这种不对称性敏感。
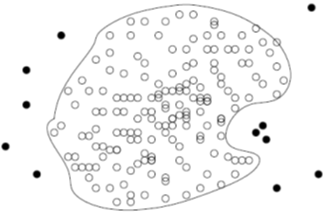
One-class model: A classifier is built to describe only the normal class 单类别模型: 建立一个分类器来描述普通的类
- Learn the decision boundary of the normal class using classification methods such as SVM e.g. diagram above 使用分类方法,如上面的SVM图,学习正常类的决策边界
- Any samples that do not belong to the normal class (not within the decision boundary) are declared as outliers 任何不属于正常类别(不在决策边界内)的样本都被声明为异常值
Advantage: Can easily detect new outliers that were not close to any outlier objects in the training set 优点:可以很容易地检测到新的异常值,这些异常值与训练集中的任何异常值对象都不接近
Extension: Can also have normal objects may belong to multiple classes — can be more selective if labels available 扩展:也可以有正常的对象,可能属于多个类别-可以更有选择性,如果标签可用
Strengths and Weaknesses of Classification-based approaches 分类器方法的优势和劣势
Strength: human knowledge can be incorporated by selection of training data 人类只是可以同构选择训练数据来整合
Strength: Outlier detection is fast 离群点检测非常快速
Bottleneck: Quality heavily depends on the availability and quality of the training set, but often difficult to obtain representative and high-quality training data 质量很大程度上取决于训练集数据质量。 但是很难获得有代表性的高质量训练数据

若有收获,就点个赞吧
0 人点赞
