Boosting
Boosting extends the idea of bagging as follows
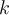 classifiers are learned iteratively. k个分类器进行迭代学习的
classifiers are learned iteratively. k个分类器进行迭代学习的- Boosting assigns a weight to each training tuple. Boosting 给每一个训练集分配一个权重。
- After training some classifier
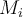 , the weights of tuples in the training set are updated to allow the subsequent classifier
, the weights of tuples in the training set are updated to allow the subsequent classifier 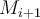 to pay more attention to the training tuples that were misclassified by
to pay more attention to the training tuples that were misclassified by 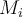 . 当训练过Mi模型后,训练集中的权重会被更新,Mi+1分类器会对之前误分类的数据集更多的关注。
. 当训练过Mi模型后,训练集中的权重会被更新,Mi+1分类器会对之前误分类的数据集更多的关注。 - The final classifier
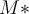 combines votes of classifiers, where the importance of a vote is measured by the accuracy of the classifier. 最后的分类器组合是分类器投票,投票的重要性由各个分类器的准确率来决定。
combines votes of classifiers, where the importance of a vote is measured by the accuracy of the classifier. 最后的分类器组合是分类器投票,投票的重要性由各个分类器的准确率来决定。
AdaBoost
AdaBoost is a boosting algorithm which adjusts the weight of each tuple adaptively after training each classifier 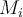 AdaBoost是一种boosting算法,它在训练每个分类器Mi后自适应地调整每个元组的权重
AdaBoost是一种boosting算法,它在训练每个分类器Mi后自适应地调整每个元组的权重
- Line (1): AdaBoost initialise each tuple with equal weight. 每个样本初始权重都为N分之一
- Line (3): To construct
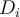 , sampling
, sampling 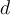 -tuples from
-tuples from 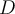 according to the weights with replacement. If a weight of certain tuple is relatively larger than the others, the tuple is more likely to be sampled from the dataset
according to the weights with replacement. If a weight of certain tuple is relatively larger than the others, the tuple is more likely to be sampled from the dataset 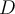 . 重新构建新的数据集,如果某个数据的权重大于其他,则其更容易被采样。
. 重新构建新的数据集,如果某个数据的权重大于其他,则其更容易被采样。- The next classifier
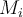 is more likely to focus on the tuples that have large weights. 接下来的分类器则更容易专注于权重较大的数据元组
is more likely to focus on the tuples that have large weights. 接下来的分类器则更容易专注于权重较大的数据元组
- The next classifier
- Line (5):
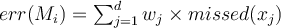
- where
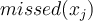 is 1 if the tuple is misclassified by
is 1 if the tuple is misclassified by 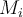 and 0 otherwise.
and 0 otherwise. - Note that we only use the tuples in
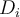 to compute the error, i.e.
to compute the error, i.e. 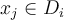 .
.
- where
- Line (10): Adjust the weights of tuples used to train classifier
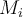
- The range of
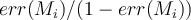 is
is 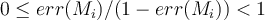 because
because 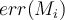 is always less than 0.5
is always less than 0.5 - We will decrease the weights of the correctly classified tuples! 正确分类的tuple 需要减去权重。
- The weights of unused and misclassified tuples are not changed. 没有被训练使用和未被正确分类的对象保持不变
- Note that the weight of a tuple will be updated once, although the tuple appears in
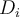 multiple times.
multiple times.
- The range of
- Line (11): Normalise the weights in order to ensure that the sum of weights is 1 (For the sampling in line (3))
- The normalised weight of
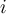 th tuple:
th tuple: 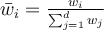
- Replace
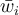 to
to 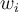 after the normalisation, and go back to step 3 if
after the normalisation, and go back to step 3 if  .
.
- The normalised weight of
Prediction with AdaBoost
Unlike bagging, where each classifier was assigned an equal vote, boosting and AdaBoost assign a different weight to the vote of each classifier. 不像bagging为等价投票,boosting将不同的权值赋给分类器投票。
The weight of classifier 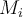 is given by
is given by
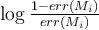 .
.
For each class 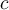 , we sum the weights of each classifier that assigns class
, we sum the weights of each classifier that assigns class 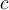 . The class with the highest sum is the winner.
. The class with the highest sum is the winner.
Boosting vs Bagging
- Boosting focuses on the misclassified tuples, it risks overfitting the resulting composite model. Therefore, sometimes the boosted model may be less accurate than a single model. 增强侧重于错误分类的元组,它有过度拟合合成模型的风险。因此,有时增强模型可能不如单一模型精确。
- Bagging is less susceptible to model overfitting. 装袋不易受模型过度拟合的影响。
- Both can significantly improve accuracy, but Boosting tends to achieve greater accuracy.两者都可以显著提高准确性,但Boosting往往会获得更高的准确性。
ACTION: Follow this worked example for AdaBoost. You can follow the example on paper, or in the video, or both; the example is the same.
Example: AdaBoost ensemble method
video walkthrough example for AdaBoost

若有收获,就点个赞吧
0 人点赞
