
Why clerical review?
● The traditional (probabilistic) record linkage process classifies record pairs into the class of potential matches if no clear decision can be made 如果不能做出明确的决定,传统的(概率)记录链接过程将记录对分类为潜在匹配的类别
● These record pairs are given to a domain expert for manual classification 这些记录对交给领域专家进行手动分类
● Manual classification requires inspection of the attribute values of a record pair, and possibly also external information – Other records about the same entities from related databases 手动分类需要检查记录对的属性值,可能还需要检查外部信息——相关数据库中关于相同实体的其他记录
– Information found on the Internet 在互联网上找到的信息
– Information from the linkage process (how many other similar records are there 来自链接过程的信息(还有多少其他类似记录
– is a record pair unique or highly connected?) 记录对是唯一的还是高度关联的?)

Using clerical review results to improve classification 使用文书审查结果改进分类
● A major challenge with record linkage classification is the lack of ground truth data in many applications 记录关联分类面临的一个主要挑战是许多应用中缺乏基本真实数据
– Preventing the use of supervised machine learning classification techniques 这阻碍了监督机器学习分类技术的使用
● The clerical review process generates training data
– Of the difficult to classify cases
– These can be used in a process called active learning which combines manual with machine learning based classification 仅适用于数据不敏感的情况
● Recent research has investigated crowed-based approaches to clerical review (using systems such as Amazon’s Mechanical Turk)
– Pay small amount of money for each manual classification 为每个人工分类支付少量费用
– Applicable only in situations where the data are not sensitive仅适用于数据不敏感的情况
Test databases and benchmarks 测试数据库和基准
● To evaluate a record linkage system or software, it needs to be employed on a set of suitable databases from the same domain 要评估记录链接系统或软件,需要在同一领域的一组合适的数据库上使用
– Similar in size and characteristics to the databases it will be deployed on 与将要部署的数据库大小和特征相似
– Ground truth needs to be available in these test databases to evaluate blocking and linkage quality (pairs completeness, pairs quality, precision, recall, etc.) 需要在这些测试数据库中提供基本事实,以评估阻断和连接质量(配对完整性、配对质量、精度、召回等)。
● It is generally very difficult to obtain such test databases
– Because in record linkage we often need personal details of people
– Linking product or bibliographic databases (which are publicly available) will not be helpful for linking personal data
● In other research areas (databases, data mining, machine learning, information retrieval) there are publicly available test data collections or even benchmarking systems 在其他研究领域(数据库、数据挖掘、机器学习、信息检索),有公开可用的测试数据收集,甚至基准系统
– Transaction Processing Performance Council (TPC) 交易处理绩效委员会
– UCI Machine Learning and KDD Repository UCI机器学习和KDD存储库
– Text Retrieval Conferences (TREC) 文本检索会议(TREC)
● In record linkage, individual research groups provide small test data collections
Generating and using synthetic data 生成和使用合成数据
● Privacy issues prohibit publication of real personal information 隐私问题禁止公布真实的个人信息
● De-identified or encrypted data cannot be used for record linkage research or evaluation of record linkage systems (because personal details such as real names and addresses are needed) 未识别或加密的数据不能用于记录链接研究或记录链接系统评估(因为需要真实姓名和地址等个人详细信息)
● Alternatively, create artificial / synthetic databases for research and evaluation, with several advantages 未识别或加密的数据不能用于记录链接研究或记录链接系统评估(因为需要真实姓名和地址等个人详细信息)
– Volume and characteristics can be controlled (errors and variations in records, number of duplicates, etc.) 可以控制数量和特征(记录中的错误和变化、重复数量等)。)
– It is known which records are duplicates of each other, and so linkage quality can be calculated 已知哪些记录相互重复,因此可以计算链接质量
– Data and the data generator program can be published可以发布数据和数据生成器程序
Creating synthetic data is usually a two step process 创建合成数据通常是一个两步的过程
– First generate data based on lookup tables with real values and their distributions (name and address values and their frequencies), and functions that generate values following real distributions (age, salary, blood pressure, etc.), and that model dependencies between attributes首先根据查找表生成数据,查找表包含真实值及其分布(姓名和地址值及其频率),以及根据真实分布(年龄、工资、血压等)生成值的函数。),并对属性之间的依赖关系进行建模
– Then corrupt the generated data using realistic corruption functions (such as typos, phonetic variations, OCR errors, etc) 然后使用真实的损坏函数损坏生成的数据(如错别字、语音变化、光学字符识别错误等)
● Various data generators have been developed, including at ANU: http://dmm.anu.edu.au/geco/ (GeCo generator / corruptor) 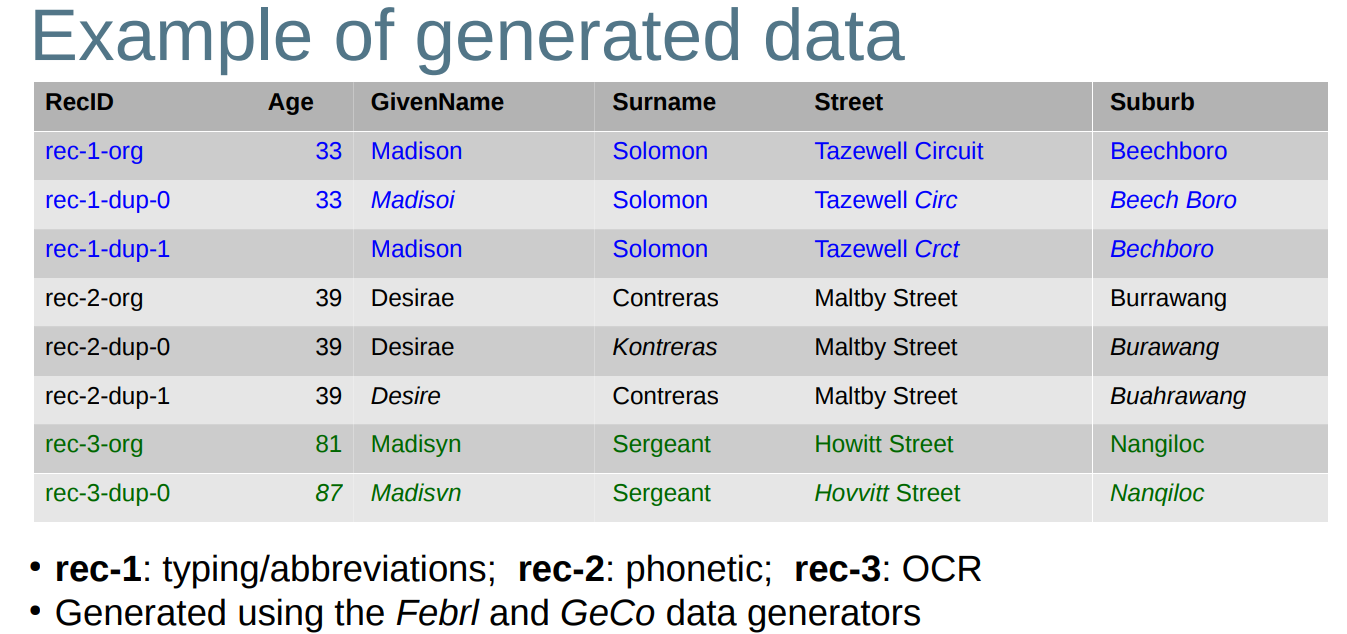

若有收获,就点个赞吧
0 人点赞
