- Probabilistic Language Modelling 概率语言模型
- Absolute-Discounting Interpolation
- Kneser-Ney Smoothing
- Smoothing for Web-scale N-grams
- Stupid Backoff
- Stupid Backoff
Goal: assign a probability to a word sequence
− Speech recognition:
• P(I ate a cherry) > P(Eye eight Jerry)
− Spelling correction:
• P(Australian National University) > P(Australian National Univerisity)
− Collocation error correction:
• P(high wind) > P(large wind)
− Machine Translation:
• P(The magic of Usain Bolt on show…) > P(The magic of Usain Bolt at the show …)
− Question-answering, summarization, etc
Probabilistic Language Modelling 概率语言模型
▪ A language model computes the probability of a sequence of words 一种计算单词序列概率的语言模型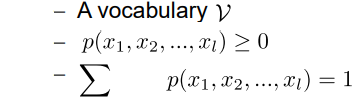
▪ Related task: probability of an upcoming word 相关任务:预测下一个单词的概率
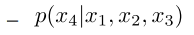
▪ LM: Either 
How to Compute 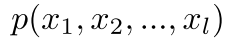
Apply chain rule: 应用链式法则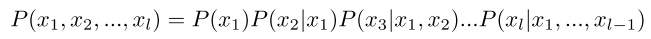
Compute 计算
P(John Smith’s hotel room bugged) = P(John)P(Smith’s | John)P(hotel | John Smith’s) … P(bugged | John Smith’s hotel room)
Estimate the Probabilities 估计概率
▪ P(bugged | John Smith’s hotel room) will most likely result in 0, as such specific long sequences are not likely to appear in the training set! 很可能导致0,因为这样的特定长序列不太可能出现在训练集中
▪ P(bugged | John Smith’s hotel room) =
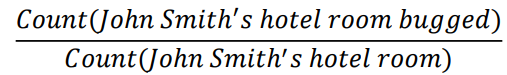
▪ Most likely to result in 0 counts! 大概率会得到0 counts
▪ So, we need to simplify the calculations! 因此,我们需要简化计算!
Markov Assumption (simplifying assumption) 马尔可夫假设(简化假设)
▪ Simplification: 简化:
P(bugged | John Smith’s hotel room) ~ P(bugged | room)
OR
P(bugged | John Smith’s hotel room) ~ P(bugged | hotel room)
▪ First-order Markov assumption: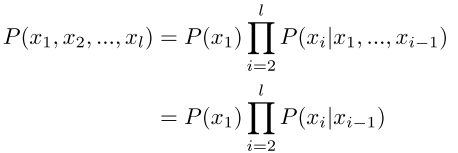
▪ Assumes only most recent words are relevant! 假设只有相邻的单词是相关的
Unigram Model 单幅模型
▪ Zero-order Markov assumption
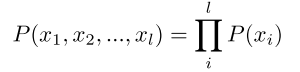
▪ Examples generated from a unigram model
▪ Not very good!
Bigram Model 双gram模型
▪ First-order assumption 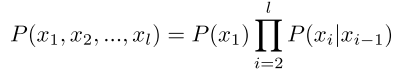
▪ P(I want to eat Chinese food) = ?
▪ Estimate bigram probabilities from a training corpus 从训练语料库中估计二元模型概率
Bigram Counts from Berkeley Restaurant Corpus 伯克利餐厅语料库中的二元模型计数
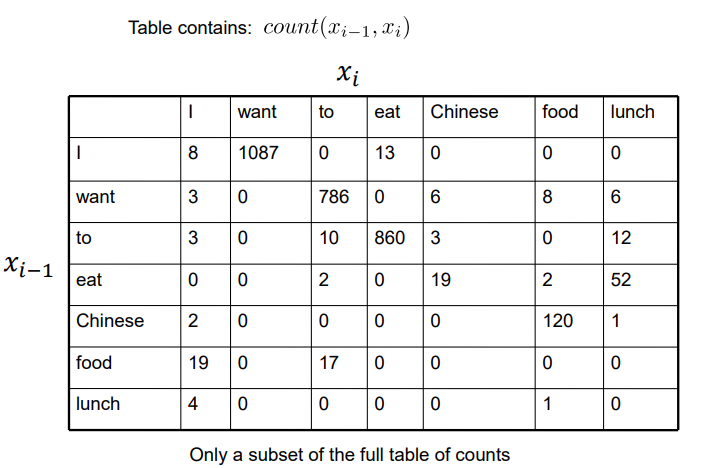
Compute Bigram Probabilities 计算二元模型概率

Log对数有助于数值稳定性(概率变小)
Trigram Models 三元模型
▪ Second order markov assumption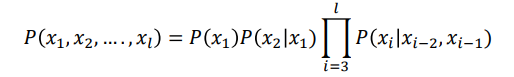
▪ Long-distance dependencies of language 语言的远距离依赖性
▪ We can extend to 4-grams , 5-grams …
Sequence Generation 序列生成
▪ Compute conditional probabilities: 计算条件概率
− P(want | I) = 0.32
− P(to | I) = 0
− P(eat | I) = 0.004
− P(Chinese | I) = 0
− P (I | I) = 0.002 − …
▪ Sampling: 取样
− Ensures you don’t just get the same sentence all the time! 确保您不会一直听到同一句话!
− Generate a random number in [0,1] 生成0-1之间的随机数 – corresponds to P’s 基于P
• Based on a uniform distribution 基于均匀分布
− Words that are a better fit, are more likely to be selected! 更可能选择到合适的单词
Approximating Shakespeare
▪ Generate sentences from a unigram model: 从单元模型生成句子
− Every enter now severally so, let
− Hill he late speaks; or! a more to leg less first you enter
▪ From a bigram model:
− What means, sir. I confess she? then all sorts, he is trim, captain
− Why dost stand forth thy canopy, forsooth; he is this palpable hit the King Henry
▪ From a trigram model:
− Sweet prince, Falstaff shall die
− This shall forbid it should be branded, if renown made it empty
The Perils of Overfitting 过拟合的危险
▪ P(I want to eat Chinese food) = ? when count(Chinese food) = 0 当部分短语概率为0,则整句的概率为?
▪ In practice, the test corpus is often different than the training corpus 测试集和训练集通常很不同
▪ Unknown words! 没见过的单词
▪ Unseen n-grams! 没见过的gram
Interpolation 插入文字
▪ Key idea: mix lower order n-gram probabilities 关键思想:混合低阶n-gram概率
▪ Lambdas are hyperparameters λ是超参数
▪ For bigram models: 双元模型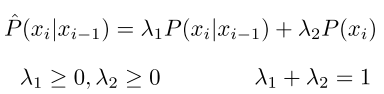
▪ For trigram models: 三元模型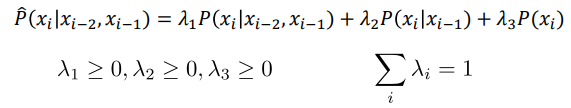
How to Set the Lambdas? 怎样设置超参数
▪ Estimate on the held-out data 留存预料
▪ Typically, Expectation Maximization (EM) is used 通常使用期望最大化
▪ One crude approach (Collins et al. Course notes 2013) 一种粗略的方法
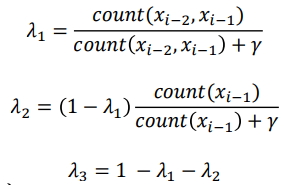
• Ensures is larger when count is larger.
• Different lambda for each n-gram.
• Only one parameter to estimate (gamma). 只需要估计一个值
Absolute-Discounting Interpolation 绝对贴现插值
We tend to systematically overestimate n-gram counts. 我们倾向于系统性地高估n-gram计数
We can use this to get better estimates and set the lambdas. Using discounting.
Absolute-Discounting Interpolation
▪ Involves the interpolation of lower and higher-order models 涉及低阶和高阶模型的插值
▪ Aims to deal with sequences that occur infrequently 旨在处理不常出现的序列
▪ Subtract d (the discount) from each of the counts 从每个计数中减去d(折扣)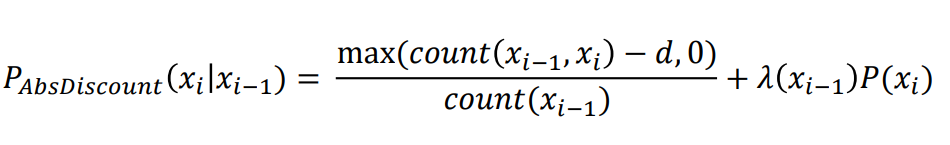
▪ The discount reserves some probability mass for the lower order n-grams ▪ Thus, the discount determines the lambda, for 0 < d < 1 we have: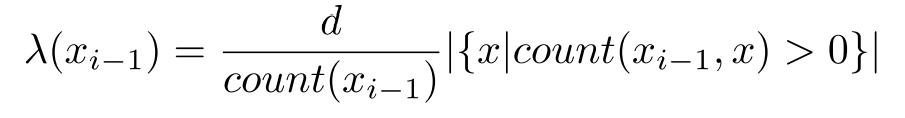
▪ Typically, d = 0.75 is used
Kneser-Ney Smoothing
▪ If there are only a few words that come after a context, then a novel word in that context should be less likely
▪ But we also expect that if a word appears after a small number of contexts, then it should be less likely to appear in a novel context…
Consider the word: Francisco
Might be common because: San Francisco is a common term.
But Francisco occurs in very few contexts.
▪ Provides better estimates for probabilities of lower-order unigrams:
− I can’t see without my reading __?
− “Francisco” is more common than “glasses”, say, … but “Francisco” always follows “San”!
▪ Pcontinuation(x) : How likely is a word to continue a new context?
− For each word x_i, count the number of bigram types it completes 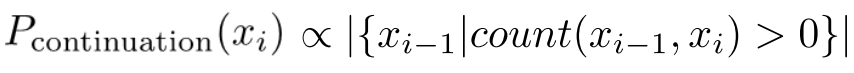
ie unigram probability is proportional to the number of different words it follows

▪ “smoothing” ~ adjusting low probs (such as zero probs) upwards, and high probs downward − ie adjusting MLE to produce more accurate probabilities
▪ Works very well, also used to improve NN approaches
▪ https://nlp.stanford.edu/~wcmac/papers/20050421- smoothing-tutorial.pdf
Smoothing for Web-scale N-grams
▪ “Stupid Backoff” (Brants et al. 2007)
▪ No discounting, just use relative frequencies!
▪ Does not give a probability distribution
Stupid Backoff
▪ A simplistic type of smoothing
▪ Inexpensive to train on large data sets, and approaches the quality of Kneser-Ney Smoothing as the amount of training data increases
▪ Try to use higher-order n-gram’s, otherwise drop to shorter sequence ie one less sequence, hence backoff!
− Every time you ‘backoff’, eg reduce from trigram to bigram because you’ve encountered a 0 probability, you multiply by 0.4
− ie use trigram if good evidence available, otherwise bigram, otherwise unigram!
▪ S = scores, not probabilities!
Stupid Backoff
▪ Extrinsic evaluation:
− Put each model in a task
• Spelling correction, machine translation etc
− Time consuming
▪ Intrinsic evaluation:
− Perplexity
− Weighted average number of possible next words that can follow a given word
- Normalised likelihood
– the lower the better - L = length of sequence
- Works well when test and training data are similar
- Pre-processing and vocabulary matter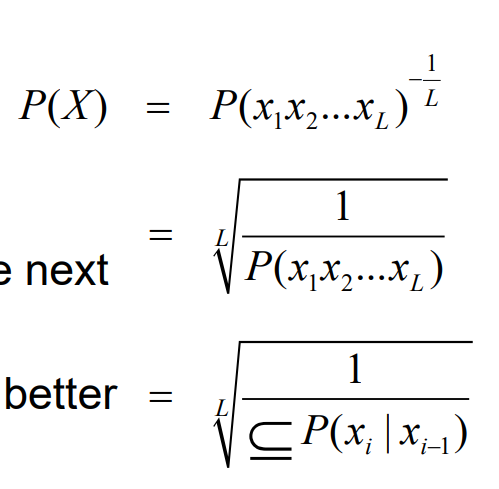


若有收获,就点个赞吧
0 人点赞
