For a set 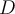 of data points, start with a user-defined parameter
of data points, start with a user-defined parameter 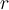 called the distance threshold 距离阈值 that defines a reasonable neighbourhood for each object. For each object o, examine the number of other objects in the r-neighbourhood of o. _If enough of the objects in
called the distance threshold 距离阈值 that defines a reasonable neighbourhood for each object. For each object o, examine the number of other objects in the r-neighbourhood of o. _If enough of the objects in 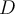 are beyond the r-neighbourhood of o, then o should be considered an outlier.
are beyond the r-neighbourhood of o, then o should be considered an outlier.
Formally, let 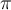 (
(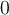 ) be a fraction threshold, a user-defined parameter that defines what proportion of objects in D are expected to be within the r-neighbourhood of every non-outlying object非离群对象.
) be a fraction threshold, a user-defined parameter that defines what proportion of objects in D are expected to be within the r-neighbourhood of every non-outlying object非离群对象.
Then an object 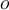 is a distance-based outlier
is a distance-based outlier 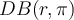 if
if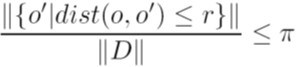
that is, if the proportion of objects in 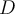 that are as close as
that are as close as 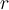 is no more than
is no more than 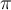 .
.
_Equivalently, one can check the distance between o and its k-nearest neighbour o, where k is defined by 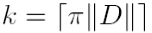
In this case, o is an outlier if 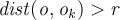
N.B. the upper-square brackets here indicate the ceiling function that rounds any-noninteger value up to the whole number above.
_
Computation
The simple nested-loop algorithm below, although theoretically 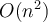 , is usually linear in practice because the inner loop terminates early when there are few outliers.
, is usually linear in practice because the inner loop terminates early when there are few outliers.
For any object o, calculate its distance from other objects, and count the number of other objects in the r-neighborhood.
If π∙n other objects are within r distance, terminate the inner loop, Otherwise, o is a DB(r, π) outlier.
ACTION: Note this pseudo-code, straight from the text, is ambiguous. The “exit” command must pass control out of the inner for loop back to the next iteration of the outer for loop, and thereby skipping the “print” command. If, like me, you find this odd, then an alternative correction would be to insert a test in front of the “print” command, i.e. insert “if not count >= π.n then”
ACTION: Check through this worked example of detecting distance-based outliers. You can watch the video or work through the paper-based working, or both.
Video for distance-based outlier example
Example: Distance-Based Outlier with Nested Loop

若有收获,就点个赞吧
0 人点赞
